作者:杨天培、汤宏垚、白辰甲、刘金毅等
强化学习是在与环境交互过程中不断学习的 , ?交互中获得的数据质量很?程度上决定了智能体能够学习到的策略的?平 。 因此 , 如何引导智能体探索成为强化学习领域研究的核?问题之? 。 本?介绍天津?学深度强化学习实验室近期推出的深度强化学习领域第?篇系统性的综述?章 , 该综述?次全?梳理了DRL和MARL的探索?法 , 深?分析了各类探索算法的挑战 , 讨论了各类挑战的解决思路 , 并揭?了未来研究?向 。当前 , 强化学习(包括深度强化学习DRL和多智能体强化学习MARL)在游戏、机器?等领域有?常出?的表现 , 但尽管如此 , 在达到相同?平的情况下 , 强化学习所需的样本量(交互次数)还是远远超过?类的 。 这种对?量交互样本的需求 , 严重阻碍了强化学习在现实场景下的应? 。 为了提升对样本的利?效率 , 智能体需要?效率地探索未知的环境 , 然后收集?些有利于智能体达到最优策略的交互数据 , 以便促进智能体的学习 。 近年来 , 研究?员从不同的?度研究RL中的探索策略 , 取得了许多进展 , 但尚??个全?的 , 对RL中的探索策略进?深度分析的综述 。

文章图片
论文地址:https://arxiv.org/pdf/2109.06668.pdf
本?介绍深度强化学习领域第?篇系统性的综述?章Exploration in Deep Reinforcement Learning: A Comprehensive Survey 。 该综述?共调研了将近200篇?献 , 涵盖了深度强化学习和多智能体深度强化学习两?领域近100种探索算法 。 总的来说 , 该综述的贡献主要可以总结为以下四??:
- 三类探索算法 。 该综述?次提出基于?法性质的分类?法 , 根据?法性质把探索算法主要分为基于不确定性的探索、基于内在激励的探索和其他三?类 , 并从单智能体深度强化学习和多智能体深度强化学习两??系统性地梳理了探索策略 。
- 四?挑战 。 除了对探索算法的总结 , 综述的另??特点是对探索挑战的分析 。 综述中?先分析了探索过程中主要的挑战 , 同时 , 针对各类?法 , 综述中也详细分析了其解决各类挑战的能? 。
- 三个典型benchmark 。 该综述在三个典型的探索benchmark中提供了具有代表性的DRL探索?法的全?统?的性能?较 。
- 五点开放问题 。 该综述分析了现在尚存的亟需解决和进?步提升的挑战 , 揭?了强化学习探索领域的未来研究?向 。
三类探索算法
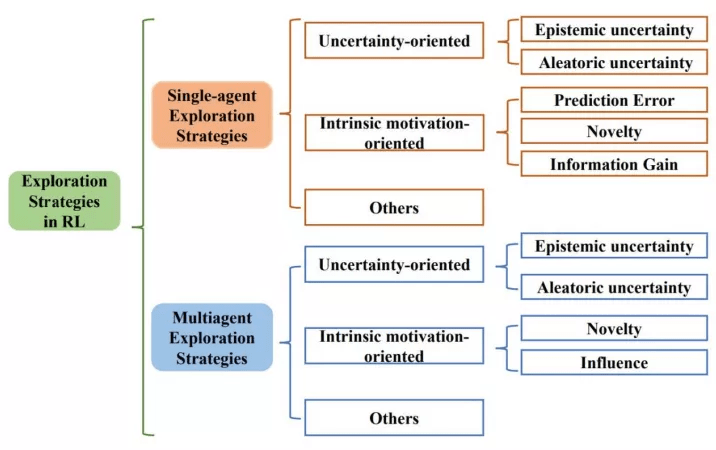
文章图片
上图展?了综述所遵循的分类?法 。 综述从单智能体深度强化学习算法中的探索策略、多智能体深度强化学习算法中的探索策略两??向系统性地梳理了相关?作 , 并分别分成三个?类:?向不确定性的(Uncertainty-oriented)探索策略、?向内在激励的(Intrinsic motivation oriented)探索策略、以及其他策略 。
1、?向不确定性的探索策略
通常遵循“乐观对待不确定性”的指导原则(OFU Principle)「1」 。 这类做法认为智能体对某区域更?的不确定性(Uncertainty)往往是因为对该区域不充分的探索导致的 , 因此乐观地对待不确定性 , 也即引导智能体去探索不确定性?的地? , 可以实现?效探索的?的 。
强化学习中?般考虑两类不确定性 , 其中引导往认知不确定性?的区域探索可以促进智能体的学习 , 但访问环境不确定性?的区域不但不会促进智能体学习过程 , 反?由于环境不确定性的?扰会影响到正常学习过程 。 因此 , 更合理的做法是在乐观对待认知不确定性引导探索的同时 , 尽可能地避免访问环境不确定性更?的区域 。 基于此 , 根据是否在探索中考虑了环境不确定性 , 综述中将这类基于不确定性的探索策略分为两个?类 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。