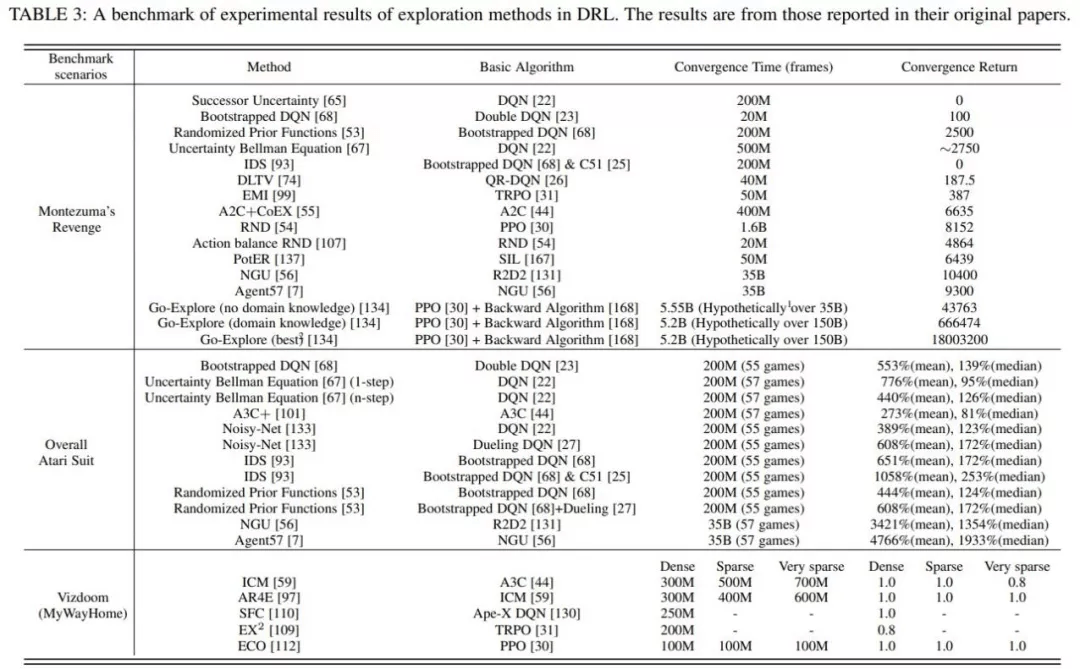
蒙特祖玛的复仇由于其稀疏、延迟的奖励成为?个较难解决的任务 , 需要RL智能体具有较强的探索能?才能获得正反馈;?穿越多个房间并获得?分则进?步需要?类?平的记忆和对环境中事件的控制 。
整个雅达利系列侧重于对提?RL 智能体学习性能的探索?法进?更全?的评估 。
Vizdoom是另?个具有多种奖励配置(从密集到?常稀疏)的代表性任务 。 与前两个任务不同的是 , Vizdoom是?款带有第??称视?的导航(和射击)游戏 。 这模拟了?个具有严重的局部可观测性和潜在空间结构的学习环境 , 更类似于?类?对的现实世界的学习环境 。
文章图片
基于上表所?的统?的实验结果 , 结合所提出的探索中的主要挑战 , 综述中详细分析了各类探索策略在这些任务上的优劣 。
关于探索策略的开放问题和未来方向
尽管探索策略的研究取得了?常前沿的进展 , 但是仍然存在?些问题没有被完全解决 。 综述主要从以下五个?度讨论了尚未解决的问题 。
- 在?规模动作空间的探索 。 在?规模动作空间上 , 融合表征学习、动作语义等?法 , 降低探索算法的计算复杂度仍然是?个急需解决的问题 。
- 在复杂任务(时间步较长、极度稀疏、延迟的奖励设置)上的探索 , 虽然取得了一定的进展 , ?如蒙特祖玛的复仇 , 但这些解决办法代价通常较? , 甚?要借助?量?类先验知识 。 这其中还存在较多普遍性的问题值得探索 。
- ?噪声问题 。 现有的?些解决?案都需要额外估计动态模型或状态表征 , 这?疑增加了计算消耗 。 除此之外 , 针对?噪声问题 , 利?对抗训练等?式增加探索的鲁棒性也是值得研究的问题 。
- 收敛性 。 在?向不确定性的探索中 , 线性MDP下认知不确定性是可以收敛到0的 , 但在深度神经?络下维度爆炸使得收敛困难 。 对于?向内在激励的探索 , 内在激励往往是启发式设计的 , 缺乏理论上合理性论证 。
- 多智能体探索 。 多智能体探索的研究还处于起步阶段 , 尚未很好地解决上述问题 , 如局部观测、不稳定、协同探索等 。
杨天培博? , 现任University of Alberta博?后研究员 。 杨博?在2021年从天津?学取得博?学位 , 她的研究兴趣主要包括迁移强化学习和多智能体强化学习 。 杨博?致?于利?迁移学习、层次强化学习、对?建模等技术提升强化学习和多智能体强化学习的学习效率和性能 。 ?前已在IJCAI、AAAI、ICLR、NeurIPS等顶级会议发表论??余篇 , 担任多个会议期刊的审稿? 。
汤宏垚博? , 天津?学博?在读 。 汤博?的研究兴趣主要包括强化学习、表征学习 , 其学术成果发表在AAAI、IJCAI、NeurIPS、ICML等顶级会议期刊上 。
??甲博? , 哈尔滨?业?学博?在读 , 研究兴趣包括探索与利?、离线强化学习 , 学术成果发表在ICML、NeurIPS等 。
刘?毅 , 天津?学智能与计算学部硕?在读 , 研究兴趣主要包括强化学习、离线强化学习等 。
郝建业博? , 天津?学智能与计算学部副教授 。 主要研究?向为深度强化学习、多智能体系统 。 发表??智能领域国际会议和期刊论?100余篇 , 专著2部 。 主持参与国家基?委、科技部、天津市??智能重?等科研项?10余项 , 研究成果荣获ASE2019、DAI2019、CoRL2020最佳论?奖等 , 同时在游戏AI、?告及推荐、?动驾驶、?络优化等领域落地应? 。
Reference
[1]P. Auer, N. Cesa-Bianchi, and P. Fischer, “Finite-time analysis of the multiarmed bandit problem,” Machinelearning, vol. 47, no. 2-3, pp. 235–256, 2002.
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。