文章图片
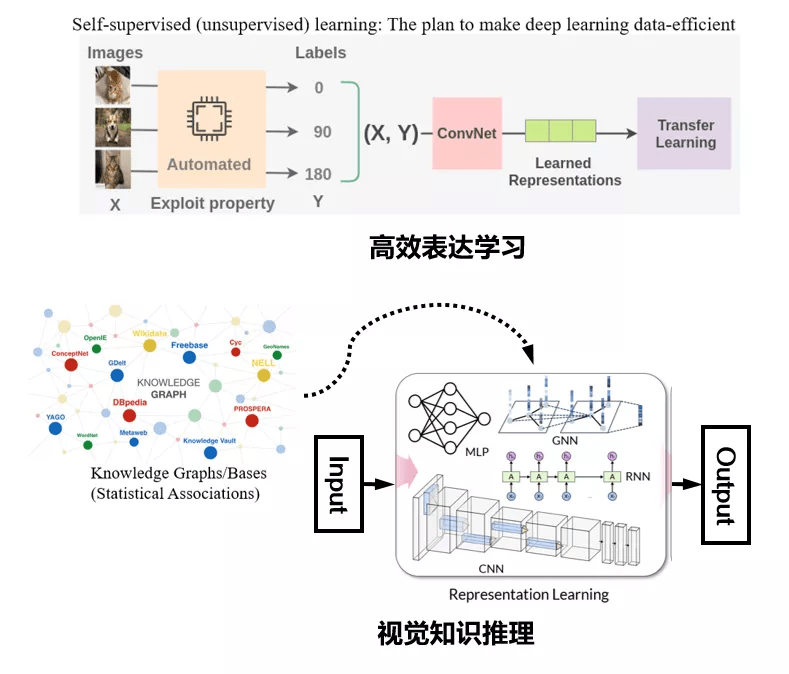
图 3. 计算机视觉研究的两大新出路:高效的视觉表达学习与视觉知识推理
这些问题我们可以归纳为两大方面(图 3) 。 第一是强调训练"性价比"(Cost-effective)的高效表达学习 。 图灵奖得主 Yan Lecun 在三年前的神经信息处理系统大会上的专题报告中 , 曾拿蛋糕作为比喻 , 其大意是如何利用无标注数据或者挖掘无标注信息 , 才是人工智能目前最值得关注的研究方向 。 这个方向包括了无监督学习 , 迁移学习或者自监督学习等[6 , 7] , 其技术核心是发掘图像视频数据中的一些内在属性和先验信息 , 通过预训练的方法先得到归纳偏置再拓展到下游任务中去 , 从而提升整个深度神经网络模型的训练效率 , 这类方法在自然语言理解、计算机视觉等领域有着诸多成功的应用 , 被认为是最近主流的一种研究和工程实践方法 。 第二 , 当我们试图跳出视觉表达学习的框架 , 用宏观的角度去看数据拟合的时候 , 我们会发现有很多领域上的问题 , 由于数据并没有很好地呈现完整的知识 , 通过拟合数据得到的模型往往无法排除数据带来的偏见 。 因此不论采用的是卷积神经网络 , 图神经网络或者是最近大热的 Transformer 模型 , 最终模型学习到的知识可能是错误的 , 并且无法解释 。 于是从 18 年开始 , 就有许多工作便试图将知识图谱、常识库等一些结构化、符号化的知识表达与表达学习相结合 , 转向更高理解层面的视觉知识推理研究 。 这些知识规则有两个核心作用 。 首先 , 在有标注样本缺乏的一些情况下 , 可以用这种知识规则去改善模型的学习能力 。 其次 , 知识规则指导的学习也可以让训练出来的深度神经模型与人类认知保持一定程度的一致 , 增强其可解释性 。
高效表达学习与视觉知识推理
基于上述两个方面问题 , 本人分享一下我们实验室最近的几个研究工作 。
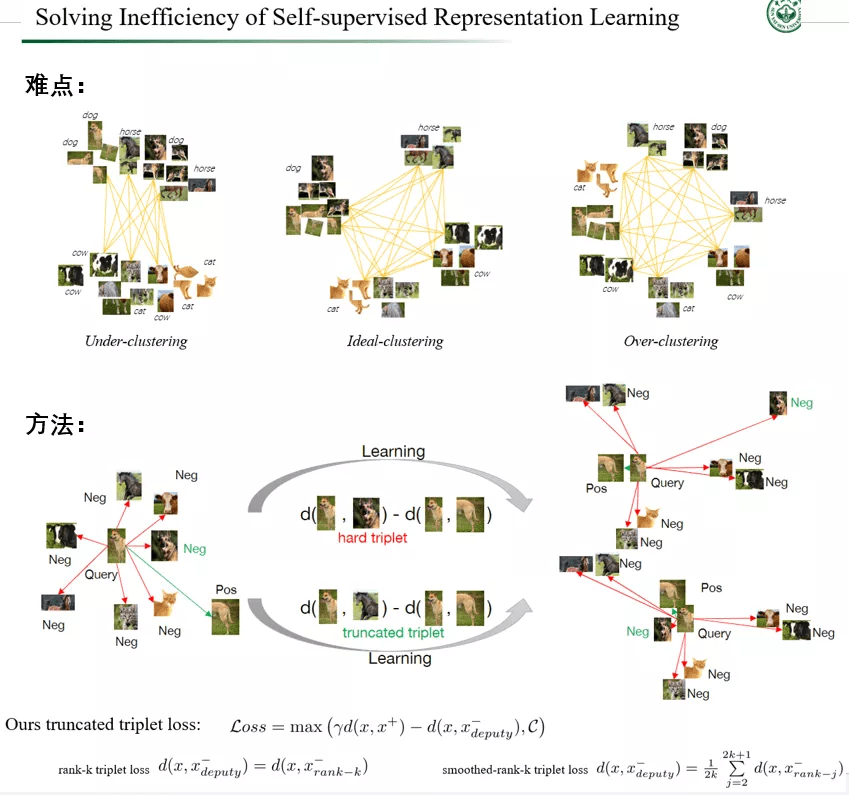
针对第一个问题 , 我们今年有一个与牛津大学 Philip Torr 合作的 ICCV 工作[9] , 内容是关于如何有效地构建训练样本组合 , 来实现高效的自监督表达学习 , 从而促进模型训练(见图 4) 。 更具体地说 , 现有的研究表明 , 即使自监督对比学习能够让预训练模型取得逼近甚至超越全监督预训练模型的效果 , 其代价是需要超过十倍的训练量 。 而我们的研究揭示了对比学习中的两个矛盾现象 , 我们称之为欠聚类和过度聚类问题:欠聚类意味着当用于对比学习的负样本对不足以区分所有实际对象类时 , 模型无法有效地学习并发现类间样本之间的差异;过度聚类意味着模型无法有效地从过多的负样本对中学习特征 , 迫使模型将实际相同类别的样本过度聚类到不同的聚类中 。 欠聚类和过度聚类是造成自监督学习效率低下的主要原因 , 而我们提出了一种高效的截断三元组样本对组合方法 , 采用三元组损失趋于最大化正对和负对之间的相对距离来解决聚类不足问题;并通过从所有负样本中选择一个负样本代理来构建负对 , 来避免过度聚类 。 从实验结果来看 , 我们的方法基本上能够在两倍于全监督训练量下达到其预训练模型水平 , 比起现有的自监督训练方法提高了 5 倍的效率 。 然后在下游任务的迁移上 , 如物体检测和行人再识别 , 在主流的大型数据集上都验证了这种方法的高效性 , 该方法训练出来的模型性能甚至优于一些全监督方法 。
文章图片
图 4. 中山大学 HCP 实验室关于研究高效自监督表达学习的最新成果 , 可以节省 80% 训练量的情况下 , 达到同样的模型性能 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。