机器之心报道
机器之心编辑部
2021 年模式识别与机器智能前沿研讨会于 10 月 29 日上午在线上举行 , 来自中山大学的林倞教授分享了题为《视觉语义理解的新趋势:从表达学习到知识及因果融合》的主旨演讲 。2021 年模式识别与机器智能前沿研讨会于 10 月 29 日上午线上举行 。 会议由中国自动化学会模式识别与机器智能(Pattern Recognition and Machine Intelligence , PRMI)主办 , 旨在将从事模式识别与人工智能各个方向的顶尖学者与研究人员聚集在一起进行技术分享 , 以便开展相关领域的交流与合作 。 在研讨会中 , 来自中山大学的林倞教授分享了关于《视觉语义理解的新趋势:从表达学习到知识及因果融合》的报告 。 表达学习和知识推理一直是模式识别与计算机视觉中的核心研究内容 , 两者的有效结合将成为打开当代通用人工智能的第一扇门 。 然而在机器视觉的背景下 , 如何将认知推理、知识表示与机器学习等多个领域的技术融会打通 , 依然是一个极具挑战和迫切的难题 。
在报告中 , 林倞教授首先简要回顾了计算机视觉领域从传统到现代的研究发展趋势 , 然后分享了他在表达学习和知识融合方面的一系列代表性工作 。 林倞教授认为目前绝大部分的知识融合表达学习工作依然无法完全实现两者的有效融合 , 主要原因是高维度的视觉大数据难以避免地夹杂了各种混淆因子 , 导致深度学习模型难以从这些数据中提取无偏误的表征与因果相关的知识 。 鉴于此 , 林倞教授提出融入因果关系理解的知识表达学习的新视角和新方法 。 与现有因果推断作用于固定的低维度统计特征的做法不同 , 融合因果关系理解的表达学习往往需要结合复杂的多模态结构知识 , 以因果关系指导表达学习 , 再用学习到的表征反绎因果关系 。 最后林倞教授分享了他所带领的中山大学人机物智能融合实验室(以下简称 HCP 实验室)最近在因果表达学习领域的研究进展 , 并展示了如何将因果表达学习与多模态结构知识融合实现去数据偏见的解释性和优越模型性能 。
以下为机器之心根据林倞教授的演讲内容进行的整理 。
计算机视觉语义理解:从过去到现在
【中山大学林倞解读视觉语义理解新趋势:表达学习到知识及因果融合】
文章图片
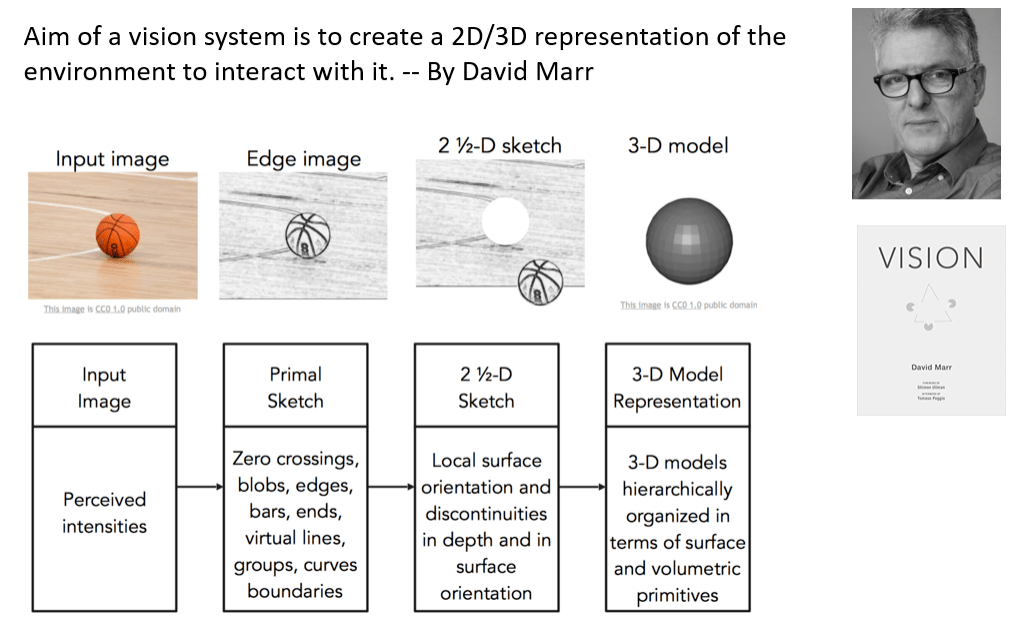
图 1.David Marr 首次对计算机视觉系统应该要做什么给出了观点 。
计算器视觉奠基人之一的 David Marr 在他的著作《视觉》[1]一书中提出了视觉理解研究的核心问题(见图 1):视觉系统应以构建环境的二维或三维表达 , 使得我们可以与之交互(这里的交互意味着学习 , 理解和推理) 。 David Marr 把计算视觉表达分成几个层面 , 从单纯的二维视觉图像 , 然后到代表边缘结构和轮廓信息的原始简约图(Primal Sketch) , 再到包含一定程度深度信息的模态 2.5 维简约图(2.5-D Sketch) , 最后到完整的三维表达 。 长期以来 , 计算视觉领域都围绕这样一个脉络来开展研究工作 。
文章图片
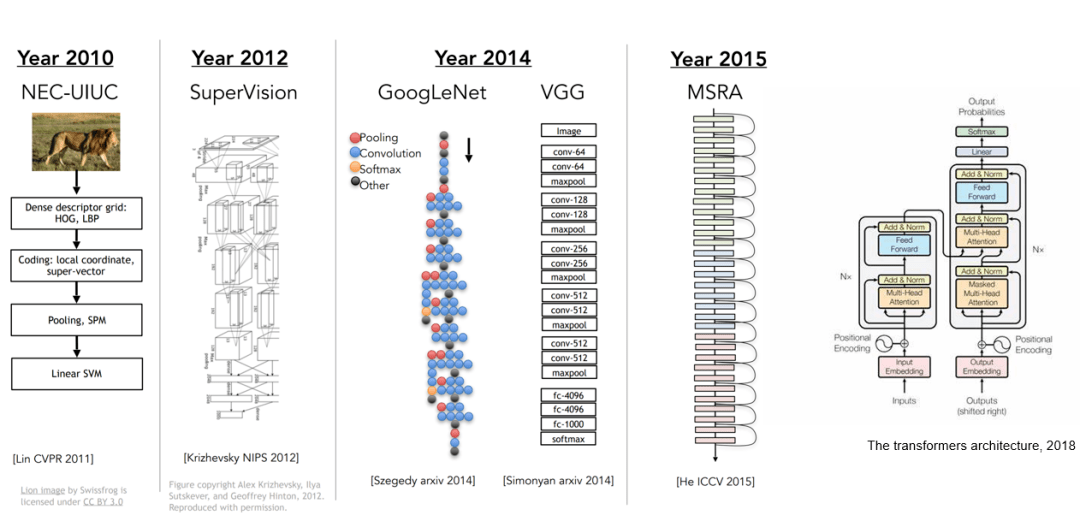
图 2. 神经网络架构随着研究的深入变得越来越复杂
后续的视觉研究越来越多地跟机器学习 , 特别是深度学习相关 。 2010 年 , 当时的主流做法是利用特征工程 , 比如 HOG[2],LBP[3] , 来提取图像的统计特征 , 再结合一些如特征金字塔等的特征增强方法 , 最后利用支持向量机等判别器来完成识别任务 。 自 2012 年起 , 深度卷积神经网络在 ImageNET 图像识别大赛中大放异彩 , 其技术本质上是舍弃了人工构建特征时造成的信息丢失 , 转而直接从图像中学习并提取判别性更强的视觉表达 。 于是越来越多的研究者开始关注如何利用更强的深度模型去提升视觉表达的学习能力 , 从残差网络到今天的 Visual Transformer 架构[4 , 5] , 近十年来的计算机视觉研究围绕着如何构建强大的表达学习模型这个主题 。 在深度学习蓬勃发展的过程中 , 各类视觉任务(如物体识别 , 检测 , 图像分割等)的性能不断提升 。 然而 , 该研究路线也逐渐遇到了瓶颈 , 这是因为仅仅通过设计神经网络模型 , 很多关于计算机视觉理解的问题无法得到根本解决 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。