文章图片
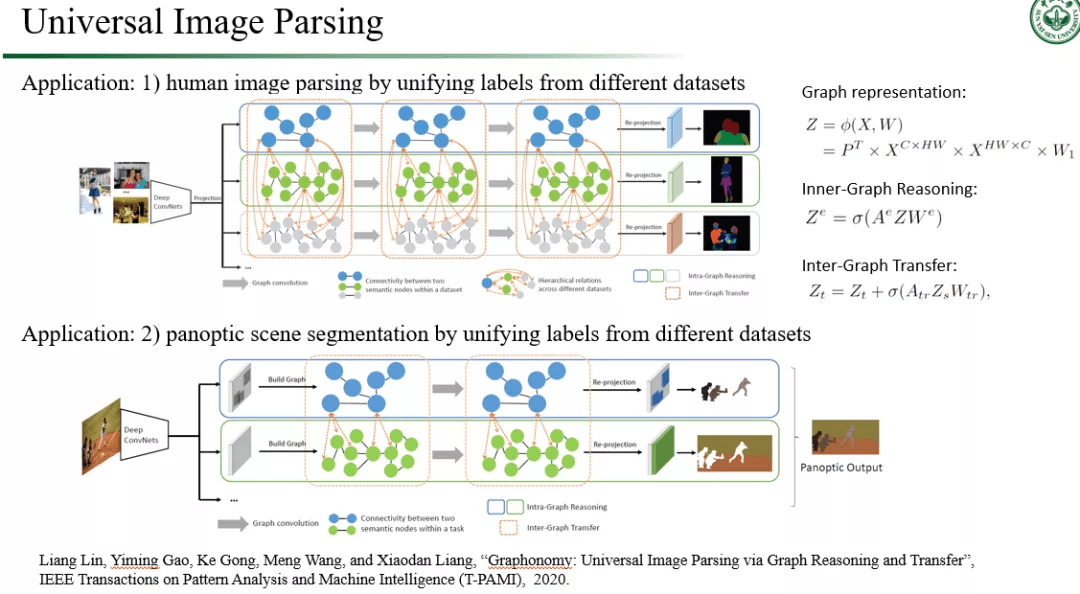
图 5. 中山大学 HCP 实验室在视觉推理方向上的代表性工作:通用图像解析 。
而在视觉理解中的知识推理这一方面问题 , 我们实验室早在 2017 年就开展了相关研究 , 取得的成果也比较多 。 我首先介绍一下我们团队利用知识推理去辅助高层视觉语义理解的两个工作 。 第一个工作是关于如何实现通用的图像解析(Image Parsing , 可看作是一种精细化的语义分割任务)模型[10] (见图 5) 。 通常要实现在某个领域上的图像解析 , 我们是要利用大量本领域上的图像数据参与模型训练的 , 这一方面往往不符合高效表达学习的设定 , 而另一方面 , 要让其实现在另一个领域上面的图像解析 , 模型则必须重新进行训练 , 因为新领域的图像分布和类别跟旧领域不一样 。 为了摆脱这些局限 , 我们的工作利用跨领域之间的知识共通性作为桥梁 , 将人类知识和标签分类法纳入到图卷积网络中构造新的迁移学习跨领域推理算法 , 再通过语义感知图推理和传输在多个域中保持一致性 , 实现跨域图像解析的语义包融和互补 。 我们的方法在著名人体解析数据集 LIP(顺带一提 , 该数据集也是由我们团队于 2017 年的 CVPR 工作中首次提出 , 在用于数次研讨会的专项比赛后 , 其已成为人体解析领域里面的著名基准数据集)中表现出非常优秀的跨领域人体解析效果 。 另外 , 在全景分割任务中 , 我们的方法也在跨领域迁移情况下达到了当前最先进的性能 。
文章图片
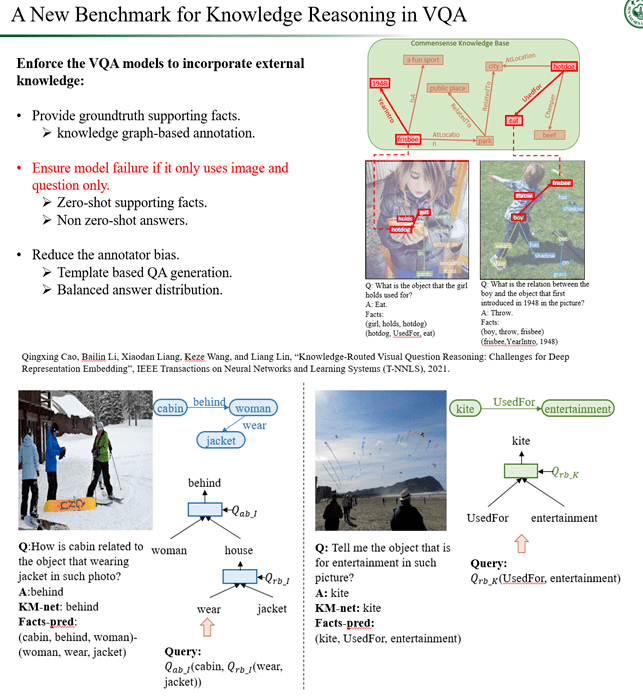
图 6. 中山大学 HCP 实验室在视觉推理方向上的代表性工作:融合知识推理的视觉问答 。
第二个工作是关于如何融入外部知识去完成视觉问答任务[11](见图 6) 。 具体来说 , 视觉问答任务的技术本质需要实现对图像和对应语言的同步理解 , 这需要在完备的知识空间里面进行推理 。 然而现存的大部分视觉问答的推理是通过配对封闭领域下的问答数据而实现的 , 其训练的模型极容易产生偏误 , 难以泛化到开放世界下的问答场景中 。 我们的工作提出了第一个融合外部知识进行多段推理的数据集 , 该数据集衍生于真实的问答情况 , 同时提供了从数据领域到知识图谱的推理路径标签 。 这有助于衡量视觉问答过程的模型推理可解释性 , 同时也比较容易应对未出现过的提问情况 。 我们基于树层次结构提出了针对该问题的模块化视觉推理问答网络 , 能够灵活结合结构知识库进行视觉表达学习 , 高效地推演出问题答案 。
除了高层视觉语义理解外 , 基于知识的视觉推理也可以被应用到一些传统的视觉任务当中 , 突破现有模型的性能瓶颈 。 接下来我简要介绍一下我们团队在这方面的四个工作 。
文章图片
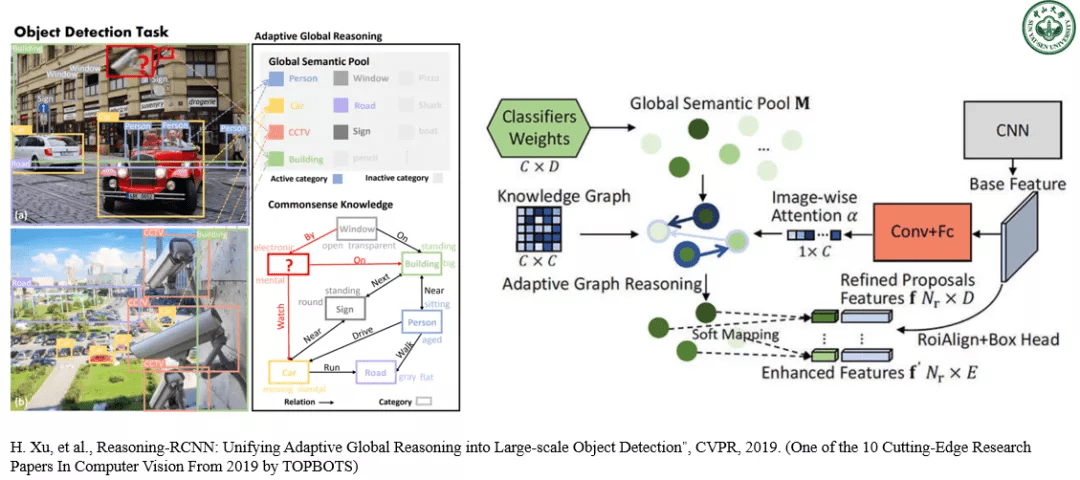
图 7. 中山大学 HCP 实验室利用视觉推理技术提高复杂场景下大规模物体检测的性能 。
第一个是我们在 CVPR-19 提出的 RCNN 系列衍生模型 Reasoning-RCNN , 将基于知识图谱的常识推理技术整合到神经符号模型中 , 从而让物体检测网络在所有对象区域上具备自适应全局推理的能力 , 能有效应对大规模物体检测问题中的长尾数据分布 , 严重的遮挡和类别模糊性等挑战 。 Reasoning-RCNN 不仅能在视觉层面上传播信息 , 同时也在全局知识范围内学习所有类别的高级语义表示 。 基于检测网络的特征表示 , Reasoning-RCNN 首先通过收集每个类别先前的分类层权重来生成全局语义池 , 然后通过联系全局语义池中上下文的不同语义来自适应地强化每个对象特征的信息 。 这让 Reasoning-RCNN 具备可扩展集成任何知识的能力 。 在三个大规模物体检测的基准数据集(物体种类可以多达数千个)中 , Reasoning-RCNN 实现了 15%-37% 的最优性能提升 。 该研究也被全球人工智能行业战略研究公司 TOPBOTS 评选为 2019 年计算机视觉领域最前沿的十个工作之一 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。