机器之心报道
编辑:杜伟、陈萍
GFlowNet 会成为新的深度学习技术吗?近日 , 一篇名为《GFlowNet Foundations》的论文引发了人们的关注 , 这是一篇图灵奖得主 Yoshua Bengio 一作的新研究 , 论文长达 70 页 。
在 Geoffrey Hinton 的「胶囊网络」之后 , 深度学习的另一个巨头 Bengio 也对 AI 领域未来的方向提出了自己的想法 。 在该研究中 , 作者提出了名为「生成流网络」(Generative Flow Networks , GFlowNets)的重要概念 。
文章图片
GFlowNets 灵感来源于信息在时序差分 RL 方法中的传播方式(Sutton 和 Barto , 2018 年) 。 两者都依赖于 credit assignment 一致性原则 , 它们只有在训练收敛时才能实现渐近 。 由于状态空间中的路径数量呈指数级增长 , 因此实现梯度的精确计算比较困难 , 因此 , 这两种方法都依赖于不同组件之间的局部一致性和一个训练目标 , 即如果所有学习的组件相互之间都是局部一致性的 , 那么我们就得到了一个系统 , 该系统可以进行全局估计 。
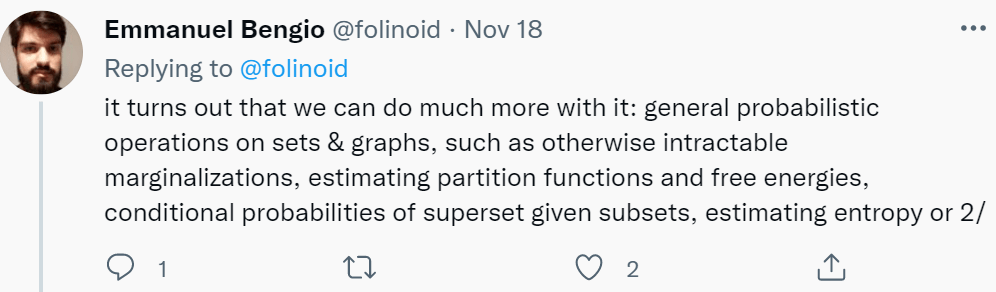
【70页论文,图灵奖得主Yoshua Bengio一作:「生成流网络」拓展深度学习领域】至于 GFlowNets 作用 , 论文作者之一 Emmanuel Bengio 也给出了一些回答:「我们可以用 GFlowNets 做很多事情:对集合和图进行一般概率运算 , 例如可以处理较难的边缘化问题 , 估计配分函数和自由能 , 计算给定子集的超集条件概率 , 估计熵、互信息等 。 」
文章图片
本文为主动学习场景提供了形式化理论基础和理论结果集的扩展 , 同时也为主动学习场景提供了更广泛的方式 。 GFlowNets 的特性使其非常适合从集合和图的分布中建模和采样 , 估计自由能和边缘分布 , 并用于从数据中学习能量函数作为马尔可夫链蒙特卡洛(Monte-Carlo Markov chains , MCMC)一个可学习的、可分摊(amortized)的替代方案 。
GFlowNets 的关键特性是其学习了一个策略 , 该策略通过几个步骤对复合对象 s 进行采样 , 这样使得对对象 s 进行采样的概率 P_T (s) 与应用于该对象的给定奖励函数的值 R(s) 近似成正比 。 一个典型的例子是从正例数据集训练一个生成模型 , GFlowNets 通过训练来匹配给定的能量函数 , 并将其转换为一个采样器 , 我们将其视为生成策略 , 因为复合对象 s 是通过一系列步骤构造的 。 这类似于 MCMC 方法的实现 , 不同的是 , GFlowNets 不需要在此类对象空间中进行冗长的随机搜索 , 从而避免了 MCMC 方法难以处理模式混合的难题 。 GFlowNets 将这一难题转化为生成策略的分摊训练(amortized training)来处理 。
本文的一个重要贡献是条件 GFlowNet 的概念 , 可用于计算不同类型(例如集合和图)联合分布上的自由能 。 这种边缘化还可以估计熵、条件熵和互信息 。 GFlowNets 还可以泛化 , 用来估计与丰富结果 (而不是一个纯量奖励函数) 相对应的多个流 , 这类似于分布式强化学习 。
本文对原始 GFlowNet (Bengio 等人 , 2021 年)的理论进行了扩展 , 包括计算变量子集边缘概率的公式(或自由能公式) , 该公式现在可以用于更大集合的子集或子图 ;GFlowNet 在估计熵和互信息方面的应用;以及引入无监督形式的 GFlowNet(训练时不需要奖励函数 , 只需要观察结果)可以从帕累托边界进行采样 。
尽管基本的 GFlowNets 更类似于 bandits 算法(因为奖励仅在一系列动作的末尾提供) , 但 GFlowNets 可以通过扩展来考虑中间奖励 , 并根据回报进行采样 。 GFlowNet 的原始公式也仅限于离散和确定性环境 , 而本文建议如何解除这两种限制 。 最后 , 虽然 GFlowNets 的基本公式假设了给定的奖励或能量函数 , 但本文考虑了 GFlowNet 如何与能量函数进行联合学习 , 为新颖的基于能量的建模方法、能量函数和 GFlowNet 的模块化结构打开了大门 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。