11月25日 , 毫末智行CEO顾维灏应邀参加了由清华大学智能产业研究院(AIR)主办的AIR DISCOVER实验室青年企业家论坛 , 同清华AIR老师及清华学子就自动驾驶行业发展话题进行交流 。 活动中 , 顾维灏以“数据智能的深思考与慢功夫”为主题发表演讲 , 详细介绍了毫末智行如何使用数据智能加速自动驾驶落地 , 并围绕数据积累与治理、模型研发、芯片应用、安全解决方案等数据智能应用中的核心问题 , 给出了毫末智行的思考与探索 。

文章图片
(毫末智行CEO顾维灏在清华AIRDISCOVER青年企业家论坛进行分享)
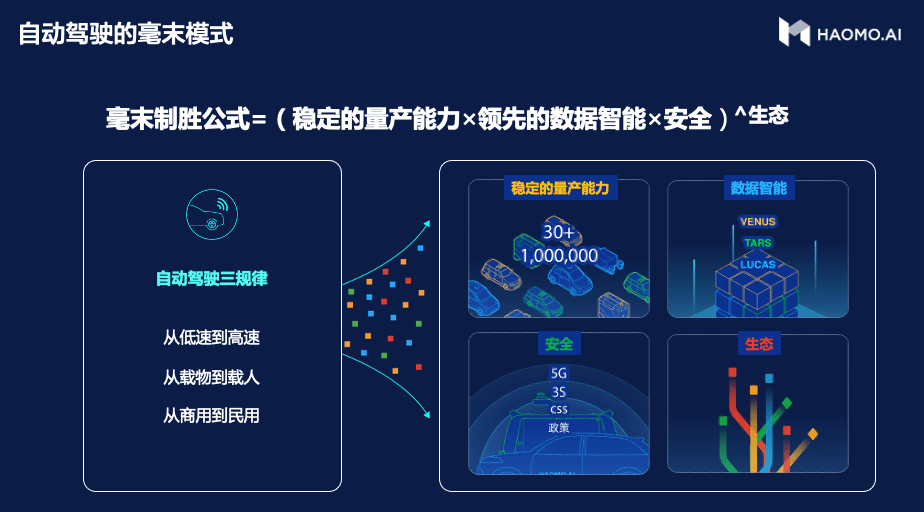
顾维灏表示 , 数据智能是自动驾驶的核心 , 规模化则是实现数据智能的前提 。 成立近两年来 , 毫末智行基于“车企+技术公司”的天然基因 , 摸索出了独特的制胜公式:(稳定的量产能力*数据智能*安全)^生态 , 并在自动驾驶量产交付、上车速度上频频刷新纪录 。 目前 , 毫末智行已将辅助驾驶系统陆续搭载至魏牌摩卡、坦克300城市版、哈弗神兽、魏牌玛奇朵、魏牌拿铁等多款热门车型 , 并携手美团、物美多点、阿里达摩院等合作伙伴 , 开启末端物流无人车服务 。 其中 , 辅助驾驶用户行驶里程已突破200万公里 , 预计未来三年搭载毫末智行辅助驾驶系统的乘用车总量将会超过100万台 , 从而形成有效的规模优势 , 进而推动毫末的数据智能高速进阶 。
文章图片
作为自动驾驶最基础且重要的一环 , 数据的质量与处理能力往往决定了一家自动驾驶企业的上限 。 顾维灏在演讲中也提出:“谁能用最低的成本 , 积累最多的数据 , 用最快的速度进行产品迭代 , 谁就将获得未来竞争的胜利 。 ”毫末智行的数据智能 , 即是让有价值的数据可持续且高效的积累 , 这也是毫末最核心的技术点 。 毫末投入了大量资源建立自身数据智能闭环 , 这背后是一门不折不扣的慢功夫 。 快慢之间 , 毫末智行逐渐探索出数据智能闭环搭建之路 。

文章图片
顾维灏介绍 , 毫末智行的数据智能体系在以下三个方面进行了深度布局:首先 , 采用大量人工标注的方式不断扩大可用数据量;其次 , 使用离线大模型为车载模型纠错 , 同时使用无监督聚类的方式去挖掘更多潜在的困难场景;最后 , 为了进一步提高数据流程的效率 , 离线大模型和无监督聚类都实现了高度的并行化训练和推断、依赖仿真引擎 , 毫末智行使用高度自动化的工具将场景库迅速转化为测试案例 , 极大提高模型研发效率 。

文章图片
除此以外 , 顾维灏还就数据智能面临的五大问题 , 给出了毫末的回答:
首先 , 如何解决数据偏见?得益于长城汽车的量产优势 , 毫末智行已经积累了大量的原始数据;同时可根据实际应用场景 , 找出有问题的场景 , 有针对性地补充足够的样本数据 , 进行样本调配 , 从而训练出一个更好的 AI 模型 。
有了巨量数据巨量模型参数 , 要面临的下一个问题便是“如何将数据训练得更快“以及”如何将模型更快地测试验证” 。 毫末为了提升训练速度 , 除了常见的数据并行之外 , 使用了更精细的模型并行方法 , 在每块 GPU 上训练完整的模型 , 同时每层的梯度还会和其他 GPU 交互 , 大大提升了模型训练效果 。 此外 , 在模型研发中 , 毫末智行使用了 ResNet50 提取图像特征 , 随后进行了多传感器在 BEV 空间的融合 , 此处采用了 Transformer 相关的模型结构 , 最后经由多任务的方式 , 感知模型直接输出在三维空间中的所有结果 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。