对于 CSG-ind , 它一方面需要针对独立先验 p^⊥ (s,v) 的推断模型 q^⊥ (s,v│x) 用于预测 , 另一方面也需要训练域上的推断模型 q(s,v│x) 用于训练 。为避免使用两个推断模型的麻烦 , 研究员们发现可用 q^⊥ (s,v│x) 表示 q(s,v│x) 。 这是因为这两个模型分别以 CSG 所定义的 p(s,v│x) 及 CSG-ind 所定义的 p^⊥ (s,v) 为目标 , 根据两者的关系 , 取 q(s,v│x)=(p(s,v) / p^⊥(s,v)) (p^⊥(x) / p(x)) q^⊥(s,v|x) , 这样当 q^⊥ (s,v│x) 达成目标时 , 对应的 q(s,v│x) 也达成了目标 。 将此式代入 ELBO 中得到 CSG-ind 的训练目标为:
其中 π(y│x)?E_(q^⊥ (s,v│x) ) [p(s,v)/(p^⊥ (s,v) ) p(y│s)] 。 式子中的期望可在对 q(s,v│x) 进行重参化(reparameterization)后用蒙特卡罗(Monte Carlo)方法估计 。 预测由 p^⊥ (y│x)=E_(p^⊥ (s,v|x) ) [p(y│s)]≈E_(q^⊥ (s,v|x) ) [p(y│s)]给出 。
对于 CSG-DA , 它与 CSG-ind 类似 , 所以研究员们也用测试域上的推断模型 q ?(s,v│x) 来表示 q(s,v│x) , 并类似地写出训练域上的目标函数 。 CSG-DA 在测试域上还需要通过拟合无监督数据来学习测试域先验 p ?(s,v) , 这可由标准的 ELBO 实现:
理论
定理中研究员们发现 E_(p ?_(s,v) ) ‖? log?(p ?_(s,v)/p_(s,v) ) ‖_2^2 这一项正是衡量两个领域上先验分布差别的费舍尔散度(Fisher divergence)D_F (p ?_(s,v),p_(s,v) ) , 它在预测误差的意义下衡量了两个领域的差别程度 。 另外 , 更小的费舍尔散度 D_F (p ?_(s,v),?) 需要比 p ?_(s,v) 有更大支撑集的分布 , 而 p_(s,v)^⊥ 恰好比 p_(s,v) 有更大的支撑集 , 这说明 CSG-ind 比 CSG 有更小的预测误差界!
实验
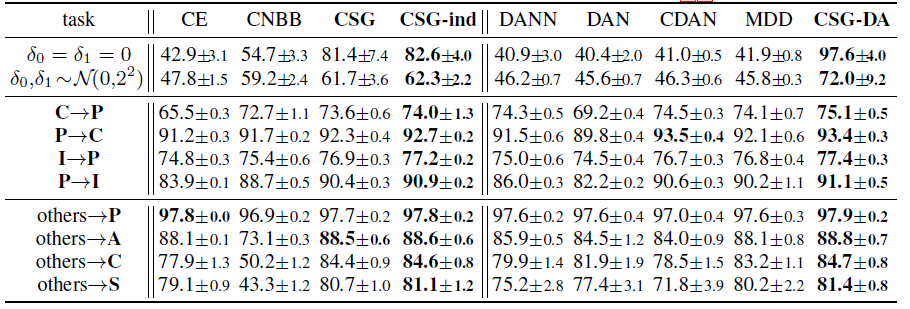
研究员们设计了一个只包含数字0和1的“平移 MNIST”数据集 , 其中训练数据中的0被有噪地向左平移5像素 , 而1向右 。 除了原本的测试集 , 研究员们也考虑将其中的数字用零均值噪声平移 。 更加真实的任务包括 ImageCLEF-DA , PACS 和 VLCS(附录) 。 表1中的结果表明 , 对于分布外泛化 , CSG 胜过标准监督学习(cross-entropy , CE)及判别式因果方法 CNBB , 同时 CSG-ind 也胜过 CSG , 表明了使用独立先验用于预测的好处 。 对于领域自适应 , CSG-DA 也胜过当前流行的方法 。 图4中的可视化分析表明所提方法更关注图片中有语义信息的区域和形状 。
文章图片
表1:平移MNIST(前两行)、ImageCLEF-DA(中四行)和 PACS(后四行)数据集上分布外泛化(左四列)和领域自适应(右五列)任务上各方法(所提方法加粗)的表现(预测准确度%)

文章图片
图4:分布外泛化(上两行)及领域自适应(下两行)任务中各方法的可视化结果(基于LIME [Ribeiro’16])
寻找用于变分布泛化的隐式因果因子

文章图片
- 论文链接: https://arxiv.org/pdf/2011.02203
- 代码链接: https://github.com/wubotong/LaCIM
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。