图5:隐式因果不变模型(LaCIM)
LaCIM 的训练方法与 CSG 类似 , 只是需要对所有训练域上的目标函数求和 , 并在各训练域上使用各自的先验模型 p^d (s,v) 和推断模型 q^d (s,v│x) 。 而其预测方法则与 CSG-ind 类似 , 区别在于推断 (s,v) 不通过一个推断模型 , 而是直接使用最大后验估计(maximum a posteriori estimate, MAP):p^(d^' ) (y│x)=p(y│s(x) ), 其中 (s(x),v(x))?arg?max_(s,v)? p(x│s,v) p^⊥ (s,v)^λ .
理论
实验
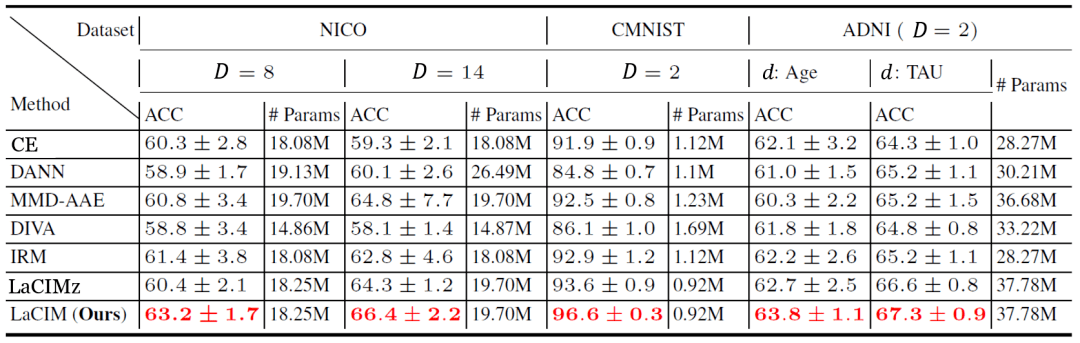
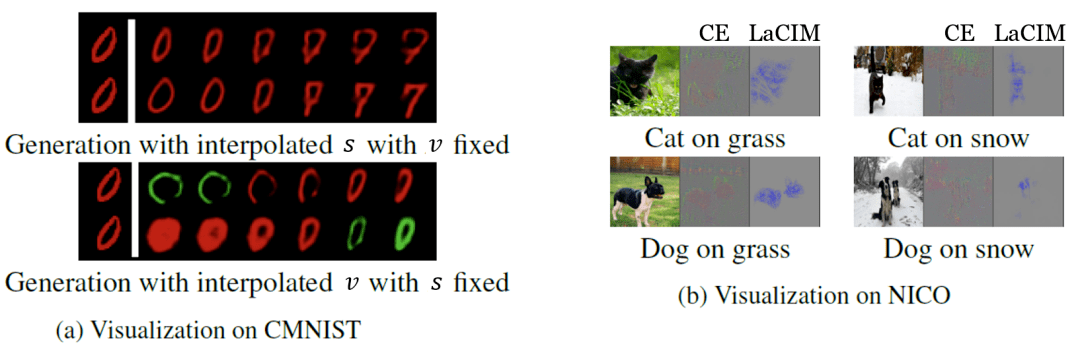
在实验中 , 研究员们选择了一些最新的领域泛化数据集 , 包括 NICO 自然图片数据集、彩色 MNIST , 以及预测阿尔兹海默症的 ADNI 数据集 。 表2中的结果表明 LaCIM 取得了最好的表现 。 可以注意到 LaCIM 也比不区分 s 和 v 的变种 LaCIMz 表现好 , 说明了将 s 和 v 分别建模的好处 。 图6中的可视化分析表明 , LaCIM 很好地区分开了语义和多样因子 , 且关注图片中具有语义信息的区域 。
文章图片
表2: 领域泛化的各数据集上各方法的表现(预测准确度%)
文章图片
图6:领域泛化任务中各方法的可视化结果
解决模仿学习中因果混淆问题的察觉对象的正则化方法

文章图片
- 论文链接: https://arxiv.org/pdf/2110.14118
- 代码链接: https://github.com/alinlab/oreo
研究员们发现 , 因果混淆问题在一般的场景中广泛存在 。 如图7所示 , 原本环境下学到的策略表现远不如训练时将分数掩盖掉的好 。 原环境中 , 策略模型会仅仅依赖于画面中的分数给出动作 , 因为它与专家动作的关系紧密而敏感 , 但却不知这只是专家动作的结果 , 所以在使用中不能采取有效的动作 。 而 在分数被掩盖的环境中 , 策略模型不得不寻找其他线索来预测专家动作 , 才得以发现真实规律 。
方法
由上述分析 , 研究员们发现产生因果混淆问题主要是因为策略模型仅仅依赖于画面中的个别对象采取动作 , 而此对象往往是专家动作所产生的看上去很明显的结果 。 这启发了研究员们通过让策略模型均衡地关注画面中的所有对象来应对此问题 , 使策略模型能注意到真正的因 。
实现此想法需要解决两个任务: (1)从图像中提取对象 。 (2)让策略模型注意到所有对象 。 对于第一个任务 , 研究员们采用了量子化向量变分自编码器(vector-quantized variational auto-encoder , VQ-VAE)[v.d. Oord’17] 抽取对象特征 。 如图8所示 , 研究员们发现 , VQ-VAE 学到的离散编码相近的值(相近的颜色)代表了同一(或语义相近的)对象 , 因此它找到并区分了图像中的对象 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。