评估设置
谷歌使用 zero-shot 和 one-shot 两种设置 , 其中训练中使用的是未见过的任务 。 评估基准包括如下:
- 完形填空和完成任务;
- 开放域问答;
- Winograd-style 任务;
- 常识推理;
- 上下文阅读理解;
- SuperGLUE 任务;
- 自然语言推理 。
实验结果
当每个 MoE 层只有一个专家时 , GLaM 缩减为一个基于 Transformer 的基础密集模型架构 。 在所有试验中 , 谷歌使用「基础密集模型大小 / 每个 MoE 层的专家数量」来描述 GLaM 模型 。 比如 , 1B/64E 表示是 1B 参数的密集模型架构 , 每隔一层由 64 个专家 MoE 层代替 。
谷歌测试了 GLaM 的性能和扩展属性 , 包括在相同数据集上训练的基线密集模型 。 与最近微软联合英伟达推出的 Megatron-Turing 相比 , GLaM 使用 5% margin 时在 7 项不同的任务上实现了不相上下的性能 , 同时推理过程中使用的算力减少了 4/5 。
此外 , 在推理过程中使用算力更少的情况下 , 1.2T 参数的稀疏激活模型(GLaM)在更多任务上实现了比 1.75B 参数的密集 GPT-3 模型更好的平均结果 。
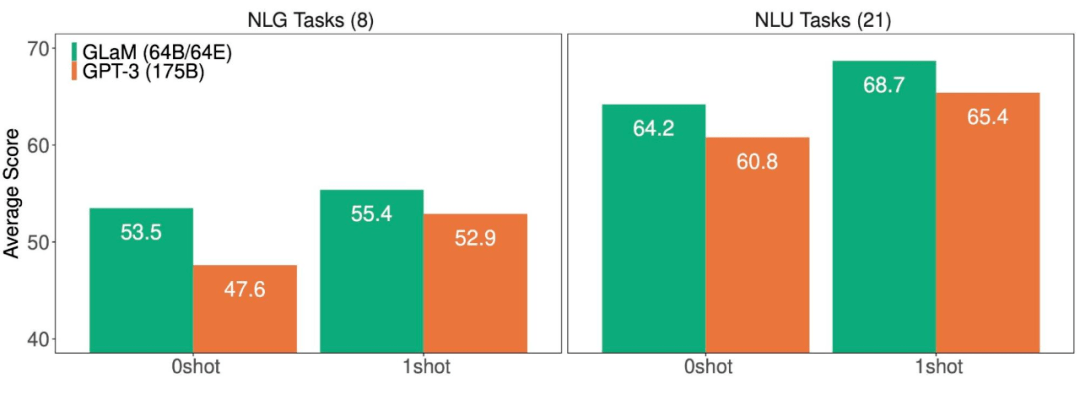
文章图片
NLG(左)和 NLU(右)任务上 , GLaM 和 GPT-3 的平均得分(越高越好) 。
谷歌总结了 29 个基准上 , GLaM 与 GPT-3 的性能比较结果 。 结果显示 , GLaM 在 80% 左右的 zero-shot 任务和 90% 左右的 one-shot 任务上超越或持平 GPT-3 的性能 。
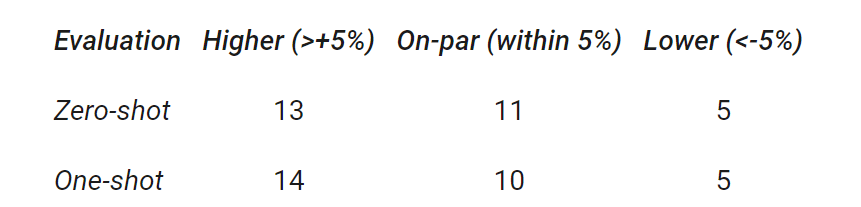
文章图片
此外 , 虽然完整版 GLaM 有 1.2T 的总参数 , 但在推理过程中每个 token 仅激活 97B 参数(1.2T 的 8%)的子网 。
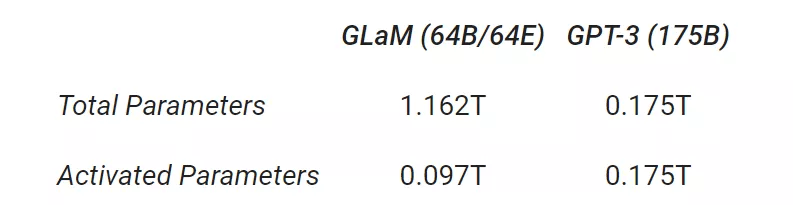
文章图片
扩展
GLaM 有两种扩展方式:1) 扩展每层的专家数量 , 其中每个专家都托管在一个计算设备中;2) 扩展每个专家的大小以超出单个设备的限制 。 为了评估扩展属性 , 该研究在推理时比较每个 token 的 FLOPS 相似的相应密集模型 。
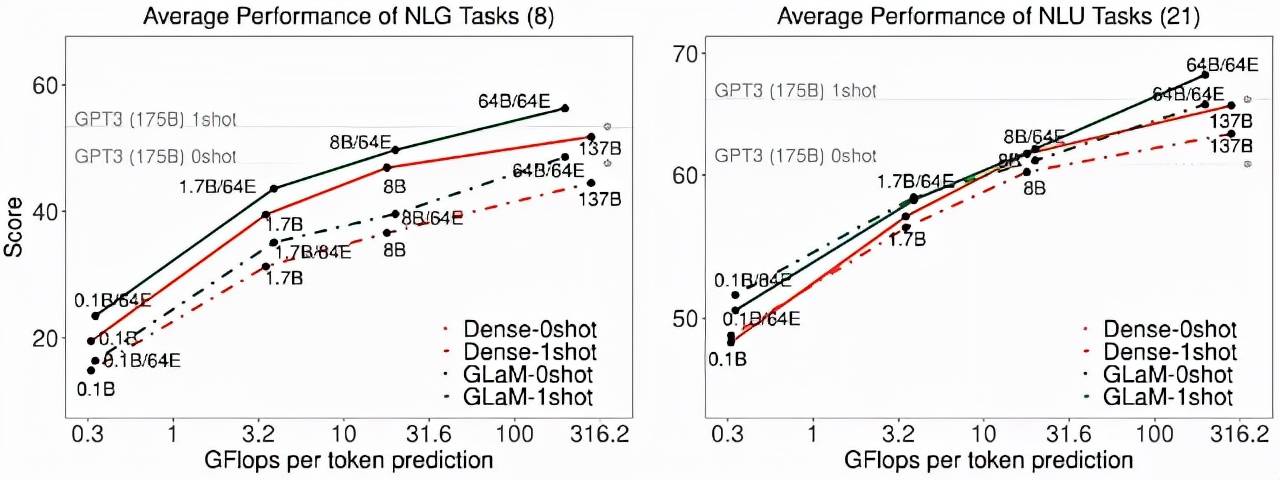
文章图片
通过增加每个专家的大小 , zero-shot 和 one-shot 的平均性能 。 随着专家大小的增长 , 推理时每个 token 预测的 FLOPS 也会增加 。
如上图所示 , 跨任务的性能与专家的大小成比例 。 在生成任务的推理过程中 , GLaM 稀疏激活模型的性能也优于 FLOP 类似的密集模型 。 对于理解任务 , 研究者观察到它们在较小的规模上性能相似 , 但稀疏激活模型在较大的规模上性能更好 。
数据效率
训练大型语言模型计算密集 , 因此提高效率有助于降低能耗 。 该研究展示了完整版 GLaM 的计算成本 。
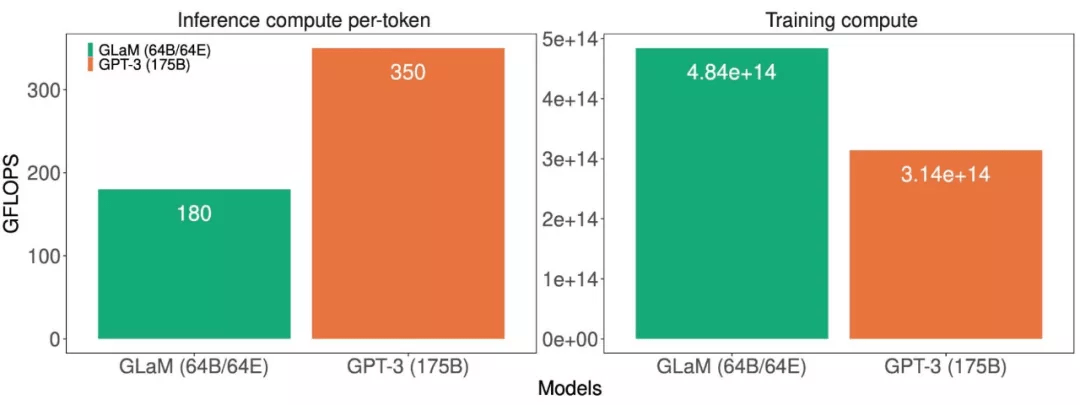
文章图片
模型推理(左)和训练(右)的计算成本(GFLOPS) 。
这些计算成本表明 GLaM 在训练期间使用了更多的计算 , 因为它在更多的 token 上训练 , 但在推理期间使用的计算却少得多 。 下图展示了使用不同数量的 token 进行训练的比较结果 , 并评估了该模型的学习曲线 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。