文章图片
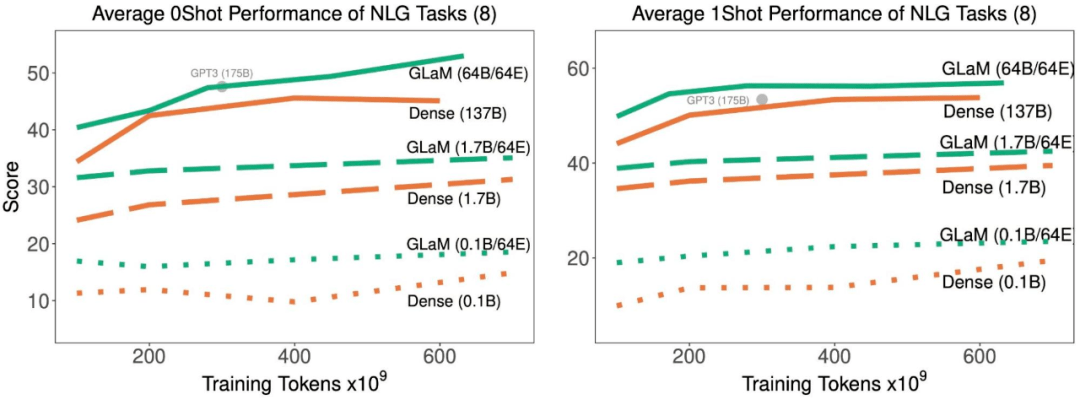
随着训练中处理了更多的 token , 稀疏激活型和密集模型在 8 项生成任务上的平均 zero-shot 和 one-shot 性能 。
文章图片
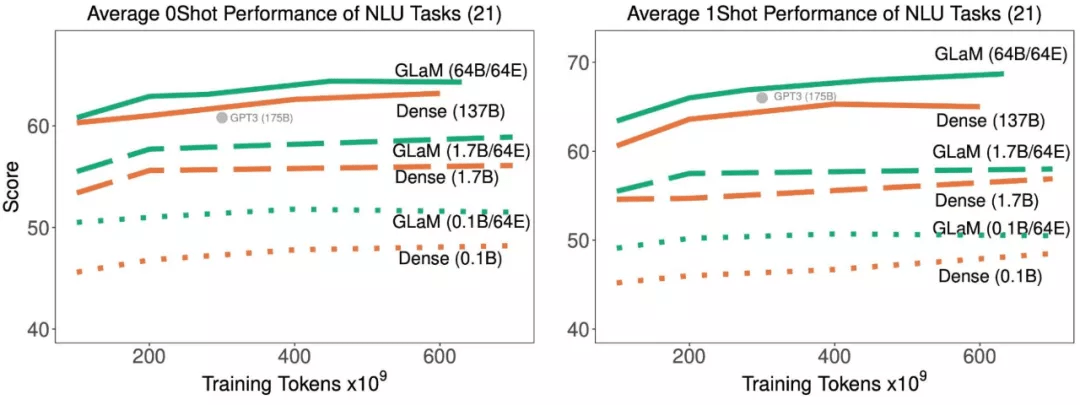
随着训练中处理了更多的 token , 稀疏激活型和密集模型在 21 项理解任务上的平均 zero-shot 和 one-shot 性能 。
结果表明 , 稀疏激活模型在达到与密集模型相似的 zero-shot 和 one-shot 性能时 , 训练时使用的数据显著减少 。 并且 , 如果适用的数据量相同 , 稀疏型模型的表现明显更好 。
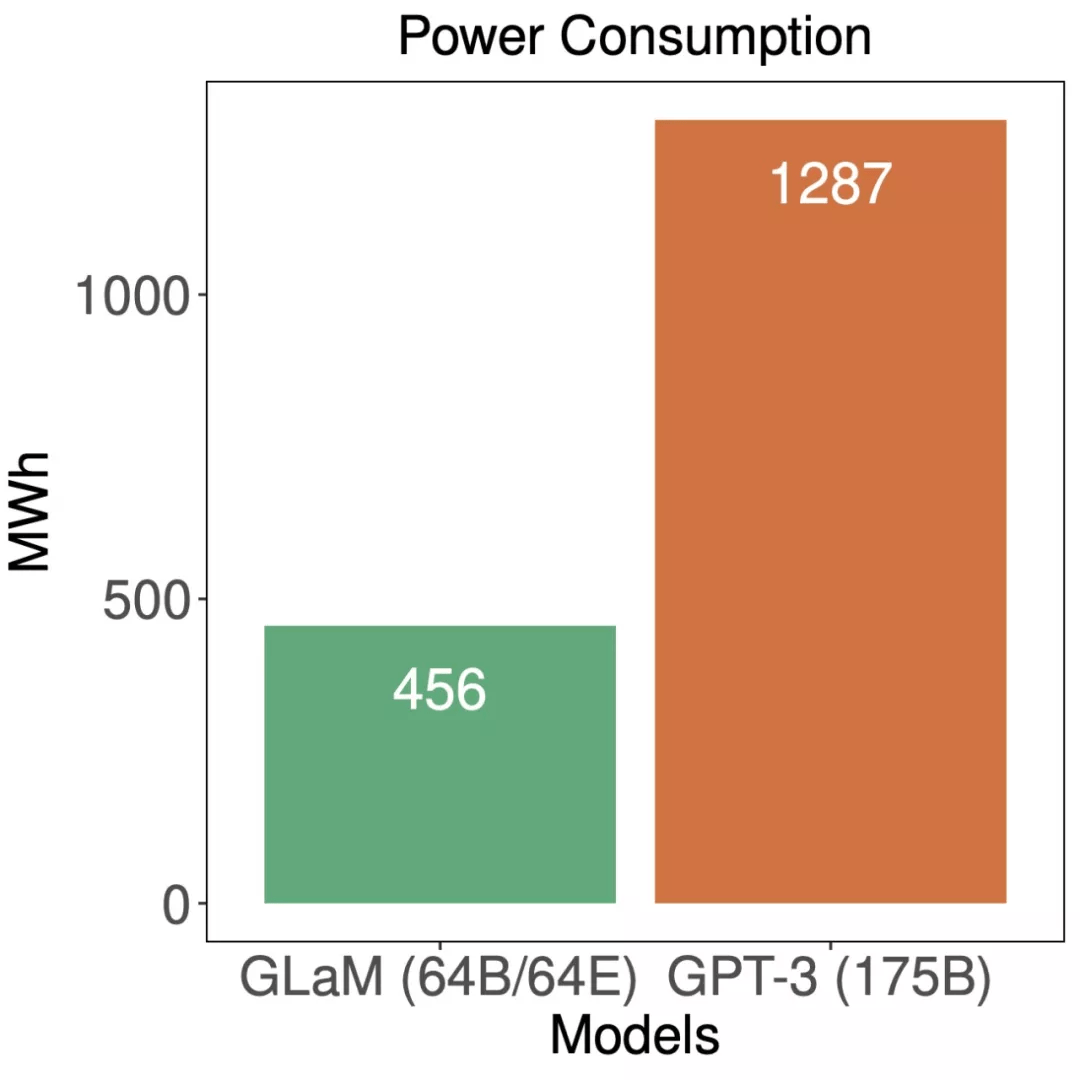
最后 , 谷歌对 GLam 的能效进行了评估:
文章图片
训练期间 , GLaM 与 GPT-3 的能耗比较 。
虽然 GLaM 在训练期间使用了更多算力 , 但得益于 GSPMD(谷歌 5 月推出的用于常见机器学习计算图的基于编译器的自动化并行系统)赋能的更高效软件实现和 TPUv4 的优势 , 它在训练时耗能要少于其他模型 。
【1.2万亿参数:谷歌通用稀疏语言模型GLaM,小样本学习打败GPT-3】英文原文:https://ai.googleblog.com
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。