评估实验
ImageNet 分类任务
该研究在三种不同的设置下评估了模型在 ImageNet 上的性能:零样本迁移、线性分类和端到端微调 。
- 零样本迁移任务在预训练后直接在分类基准上评估模型性能 , 而无需更新任何模型权重 。 通过简单地选择字幕嵌入与输入图像最接近的类 , 可以将使用对比语言监督训练的模型用作图像分类器;
- 线性分类 , 也称为线性探测 , 是一种用于评估无监督或自监督表征的标准评估方法 。 训练随机初始化的终极分类层 , 同时冻结所有其他模型权重;
- 最后 , 另一种评估表征质量的方法是 , 在对模型进行端到端微调时 , 评估预训练模型是否可以提高监督学习的性能 。
文章图片
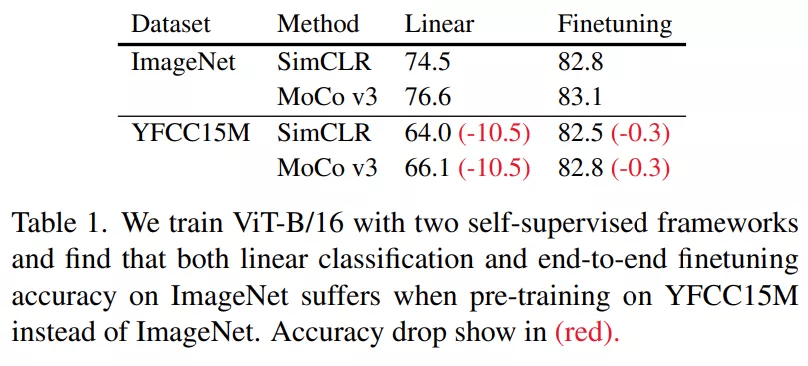
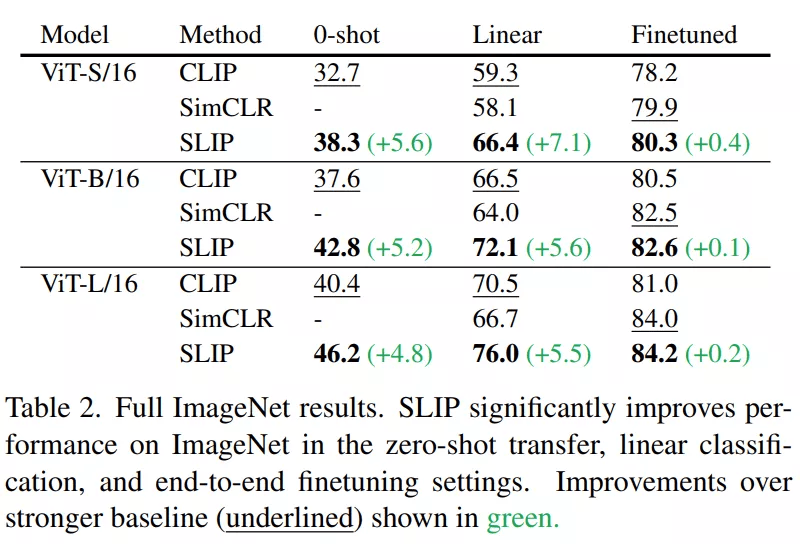
下表 2 提供了三种尺寸的 Vision Transformer 和所有三种 ImageNet 设置的 CLIP、SimCLR 和 SLIP 的评估结果 。 所有模型都在 YFCC15M 上训练了 25 个 epoch 。 该研究发现语言监督和图像自监督在 SLIP 中建设性地相互作用 , 单独提高了这两种方法的性能 。
文章图片
模型规模和计算量扩展
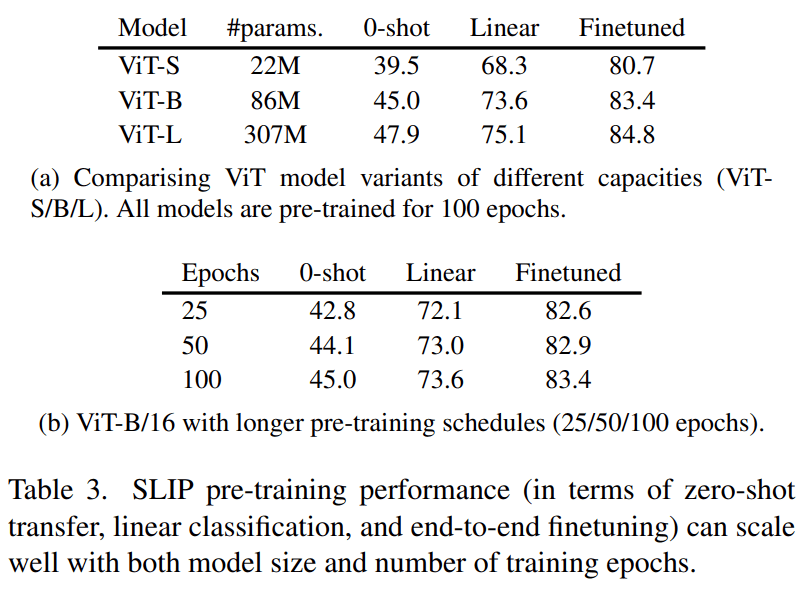
在这一部分 , 研究者探索了使用更大的计算量(训练更久)和更大的视觉模型之后 , SLIP 的表现有何变化 。 他们注意到 , YFCC15M 上的 100 个训练 epoch 对应着 ImageNet1K 上的 1200 个训练 epoch 。
下表 3 的结果表明 , 无论是增加训练时间 , 还是增大模型尺寸 , SLIP 都能实现良好的扩展 。
文章图片
其他基准
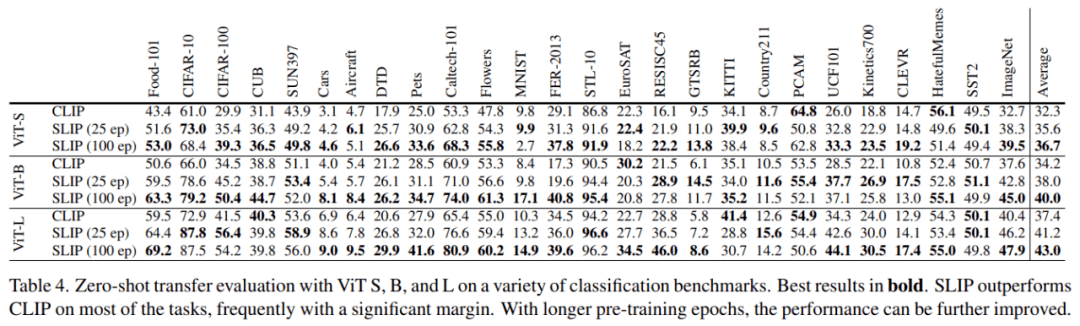
在下表 4 中 , 研究者评估了一组下游图像分类任务上的 zero-shot 迁移学习性能 。 这些数据集跨越许多不同的领域 , 包括日常场景(如交通标志)、专业领域(如医疗和卫星图像)、视频帧、带有或不带有视觉上下文的渲染文本等 。
在这些数据集上 , 我们看到 , 更大的模型和使用 SLIP 进行更长时间的训练通常可以提高 zero-shot 迁移学习的准确性 。
文章图片
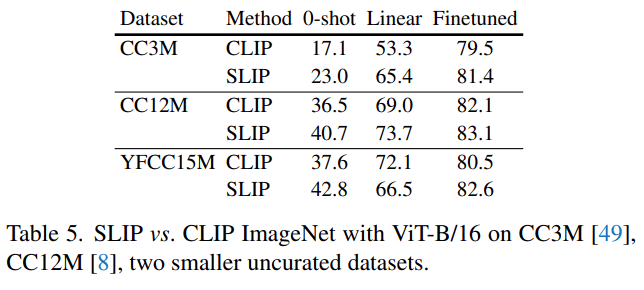
其他预训练数据集
除了 YFCC15M 之外 , 研究者还用另外两个图像 - 文本数据集——CC12M 和 CC3M——进行了实验 。 如下表 5 所示 , 他们在 CC12M 和 CC3M 上同时使用 SLIP 和 CLIP 训练 ViT-B/16 , 并与他们之前在 YFCC15M 上得到的数据进行比较 。 在所有的 ImageNet 评估设置中 , SLIP 都比 CLIP 有改进的余地 。 值得注意的是 , 在 CC12M 而不是 YCC15M 上预训练 SLIP 会产生较低的 zero-shot 准确率 , 但实际上会带来较高的线性和微调性能 。 CLIP 让人看到了更惊艳的 1.6% 的微调性能提升 。
文章图片
其他自监督框架
作者在论文中提到 , SLIP 允许使用许多不同的自监督方法 。 他们用 SimCLR 的不同替代方法——MoCo v3、BYOL 和 BeiT 在 ViT-B/16 上进行了几次实验 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。