选自arXiv
机器之心编译
为了探究 CV 领域的自监督学习是否会影响 NLP 领域 , 来自加州大学伯克利分校和 Facebook AI 研究院的研究者提出了一种结合语言监督和图像自监督的新框架 SLIP 。近来一些研究表明 , 在具有挑战性的视觉识别任务上 , 自监督预训练可以改善监督学习 。 CLIP 作为一种监督学习新方法 , 在各种基准测试中都表现出优异的性能 。
近日 , 为了探究对图像进行自监督学习的势头是否会进入语言监督领域 , 来自加州大学伯克利分校和 Facebook AI 研究院的研究者调查了 CLIP 形式的语言监督是否也受益于图像自监督 。 该研究注意到 , 将两种训练目标结合是否会让性能更强目前尚不清楚 , 但这两个目标都要求模型对有关图像的质量不同且相互矛盾的信息进行编码 , 因而会导致干扰 。

文章图片
论文地址:https://arxiv.org/abs/2112.12750v1
项目地址:https://github.com/facebookresearch/SLIP
为了探索这些问题 , 该研究提出了一种结合语言监督和自监督的多任务框架 SLIP(Self-supervision meet Language-Image Pre-training) , 并在 YFCC100M 的一个子集上预训练各种 SLIP 模型 , 又在三种不同的设置下评估了表征质量:零样本迁移、线性分类和端到端微调 。 除了一组 25 个分类基准之外 , 该研究还在 ImageNet 数据集上评估了下游任务的性能 。
该研究通过对不同模型大小、训练计划和预训练数据集进行实验进一步了验证了其发现 。 研究结果最终表明 , SLIP 在大多数评估测试中都显著提高了性能 , 这表明在语言监督背景下自监督具有普遍效用 。 此外 , 研究者更详细地分析了该方法的各个组成部分 , 例如预训练数据集和数据处理方法的选择 , 并讨论了此类方法的评估局限性 。
SLIP 框架
该研究提出了一种结合语言监督和图像自监督的框架 SLIP , 以学习没有类别标签的视觉表征 。 在预训练期间 , 为语言监督和图像自监督分支构建每个输入图像的单独视图 , 然后通过共享图像编码器反馈 。 训练过程中图像编码器学会以语义上有意义的方式表征视觉输入 。 然后该研究通过评估它们在下游任务中的效用来衡量这些学得表征的质量 。
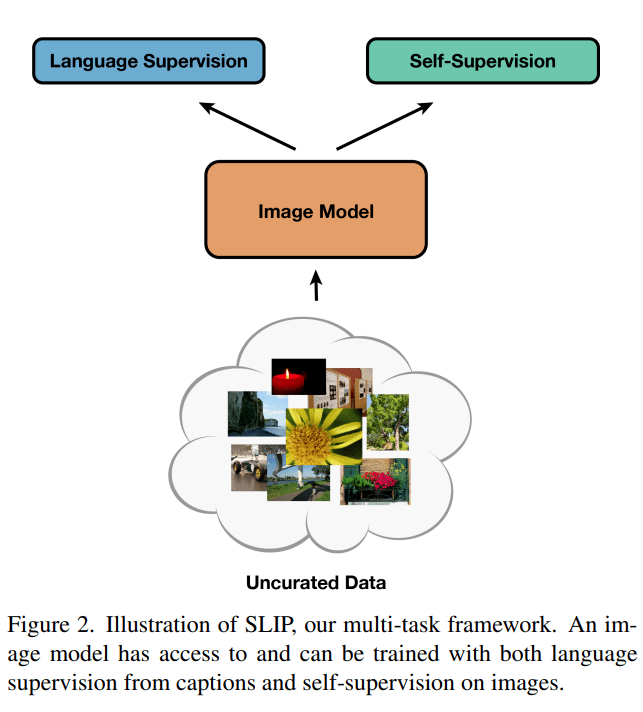
文章图片
方法
下图算法 1 概述了用于自监督的 SLIP-SimCLR 。 在 SLIP 中的每次前向传递期间 , 所有图像都通过相同的编码器进行反馈 。 CLIP 和 SSL 目标是在相关嵌入上计算的 , 然后再汇总为单个标量损失 , 可以通过重新调整 SSL 目标来平衡这两个目标 。 该研究将 SLIP-SimCLR 简称为 SLIP 。

文章图片
SLIP 增加了图像的处理数量 , 这导致产生约 3 倍多的激活 , 因此会扩大模型的内存占用并减慢训练过程中的前向传递速度 。
改进的训练过程
CLIP 的作者主要使用包含 400M 图像 - 文本对的大型私有数据集进行训练 , 这减少了正则化和数据增强的需求 。 在复现 CLIP 时 , 研究者发现了一些主要针对数据增强的简单调整 。 当在 YFCC15M 上进行预训练时 , 这些调整显著提高了性能 。
该研究对训练过程进行了改进 , 使用改进后的 ResNet-50 实现了 34.6% 的零样本迁移到 ImageNet , 超过了原始结果的 31.3% , 相比之下 , 另一项研究的 CLIP 复现在 ImageNet [29] 上实现了 32.7% 的准确率 。 该研究的实验主要关注视觉 Transformer 模型(ViT)系列 , 因为它们具有强大的扩展行为 [17] 。 并且该研究使用改进后的过程训练所有 ViT 模型 , 以便为该研究所提方法的评估比较设置强大的基线 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。