通过在约 9M 的图片 - 文本对的语料库上进行预训练 , 该研究的 base 设定下的 MVPTR 在下游任务上有着更好的表现 。
方法介绍
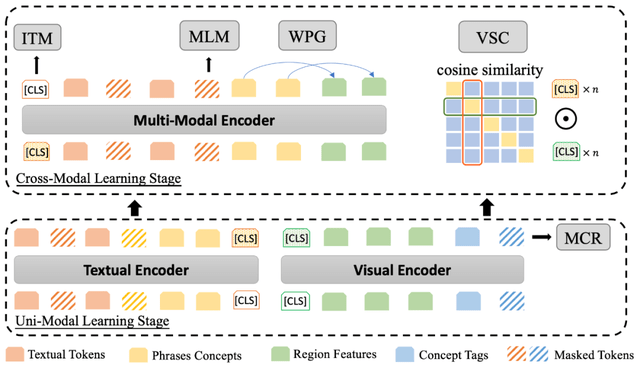
MVPTR 的模型结构如下图所示:
文章图片
模型输入
为了能显式地学习多层次语义 , 如图所示 , 对于每个模态研究者构建了两个部分的输入 , 通过不同的颜色进行表示 。 受启发于之前主要是用在 Image captioning 任务中的方法 , 该研究通过学习概念 embedding 的方法引入其他层次的语义 。
对于文本 , 类似 BERT 的处理方式 , 该研究首先将其经过分词器拆分成词 , 同时使用现成的文本场景图解析器 SPICE 将其解析为一个场景图 , 将图中的结构元组(物体 , 属性 - 物体 , 物体 - 关系 - 物体)作为短语级语义概念 。 对于每个短语概念 , 该研究会为其单独学习一个 embedding 表示 , 初始化自其中所有词的平均 embedding , 同时因为概念需要有泛化性 , 该研究只考虑出现在预训练语料库中超过 50 次的短语 。
对于图片 , 该研究使用固定的物体检测器从图片中检测出重要的物体的标记框和对应的视觉特征 , 进一步通过一个线性层将视觉特征和标记框坐标映射到与其他 embedding 同样的维度 。 同时对每个框使用对应的物体标签作为物体级别的概念 , 使用其标签词的 embedding 作为这个概念的表示 。
单模态学习
在单模态学习阶段 , MVPTR 只通过一个视觉编码器和文本编码器学习模态内的交互和表示 , 视觉编码器以拼接后物体特征序列和物体标签序列作为输入 , 学习物体间的关系 , 同时对齐物体特征和对应的物体级概念;文本编码器以拼接后的词序列和短语序列作为输入 , 提供短语中的结构信息 , 并进一步学习语境下的短语级概念 。
MCR 遮盖概念恢复
在视觉编码器中 , 输入的视觉序列里包括了物体级的概念 , 以预测标签的方式 。 之前的代表性工作 Oscar 认为这样的概念可以作为锚点帮助对齐物体表示和词 。 为了能进一步地强化其锚点的作用 , 该研究提出了一个预训练任务 MCR 。
类似于 BERT 的 MLM 任务 , 研究者随机地遮盖输入标签序列中的一部分 , 将其设为特殊字符 [MASK] 或随机替换 , 基于视觉编码器的输出 , 通过一个线性层预测遮盖部分原本的标签 。 MCR 任务可以看作是弱监督下的视觉特征和物体概念的对齐(预测特定的标签需要学习到对应物体与其的联系) , MCR 类似 image tagging , 能进一步对齐区域的表示 , 帮助之后跨模态的交互学习 。
跨模态学习
在学习了单模态内的交互和表征后 , 在第二阶段学习跨模态的语义交互和对齐 。 首先从粗粒度 , 使用 VSC 任务对齐单模态编码器得到的全局表示 , 对齐两个编码器的语义空间;之后将对齐后的 token、短语、物体特征序列拼接输入到多模态编码器中进行学习 , 为了防止在进行后续预训练任务中产生从标签到词的 shortcut , 影响真正跨模态关系的学习 , 标签序列并没有被考虑进去 。 在本阶段 , 进一步通过 WPG 来对齐物体特征和短语表示 , 并基于之前的表征 , 完成高层的推理任务 , 包括 ITM 和 MLM 。
VSC 视觉语义对比学习
在输入跨模态编码器之前 , MVPTR 通过 VSC 对齐两个模态编码器的语义空间 , 其具体的做法类似于 CLIP 和 ALBEF 中的训练方式 , 在全局层次上粗粒度地对齐图片和文本 。
该研究将视觉、文本编码器得到的“[CLS]”token 的表示作为图片和文本的全局表征 , 以两个向量间的余弦相似度作为语义相似度 。 使用 InfoNCE 作为训练损失 , 同一 batch 里仅匹配的图片 - 文本为正样本对(对应模型图中 cosine similarity 矩阵的对角线部分) , 其余都为负样本对 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。