在跨模态推理任务上 , MVPTR 在 VQA 上有着一定的提升 , 同时对比 MVPTR 和 VinVL 在各个类别上的表现 , MVPTR 在 VQA v2 的 “其他” 类问题上表现较好 , VinVL 在数字类问题上表现较好 。 因为 VinVL 会直接根据物体检测标签去预测答案 , 研究者猜想这样的方法能很好地完成数数类问题 , 而 MVPTR 则更好地学习了跨模态的交互 , 来解决需要推理的其他类问题 。 在 SNLI-VE 上的视觉蕴含任务里 , MVPTR 在测试集上效果要稍逊于 ALBEF , 研究者认为 ALBEF 在测试集上的强大的泛化表现来自于其设计的动量蒸馏方法 , 此外 , 该研究也会进一步探究这样的方法对于 MVPTR 的改进 。
在 RefCOCO + 上的短语指代表示任务上 , 因为该任务很依赖于物体检测器和所考虑的区域选择 , 所以研究者比较了 MVPTR 和 VinVL(VinVL 的结果为该研究使用与 MVPTR 类似方法进行微调实验得到):在 RefCOCO + 上的 testA 和 testB 上的两个测试集准确率上 , MVPTR 的表现为 80.88/67.11 , 要高于 VinVL 的 80.5/65.96 , 说明 MVPTR 具有更强的对于短语级别对齐能力 。
消融实验
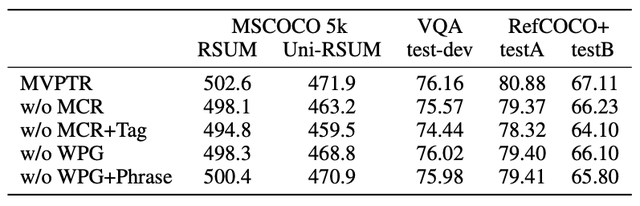
为了验证各层次对齐的协同促进作用 , 该研究针对物体 / 短语级概念的引入和对齐设计了消融实验:
文章图片
首先比较表内的前三行 , 可以看出缺少物体级概念的引入会给其他层次的语义对齐带来负面影响 , 包括细粒度、粗粒度的图片文本匹配 , 短语级别的对齐 , 并进一步影响对视觉问答的推理能力 , 且影响为所有消融实验里最大的 , 说明物体级的概念为其他层次对齐的基础 。 同时仅在引入输入的基础上 , 通过 MCR 的弱监督能进一步提高模型的性能 , 尤其是对于 Uni-RSUM 的影响说明了 MCR 能强化物体概念的锚点能力 。 总的来说物体级别的对齐帮助了短语级与图文级的对齐 。
通过比较第一行和最后两行 , 可以看到短语级的概念能比较有效地帮助完成 visual grounding 和细粒度的图文匹配任务 , 同时比较最后两行可以看出如果不通过 WPG 显式地引导学习短语概念的表示 , 仅在输入端引入短语概念反而会引入一些噪声 , 拉低了图文匹配的表现 。 总的来说短语级的对齐帮助了图片文本的对齐 。
概念的层次化表示
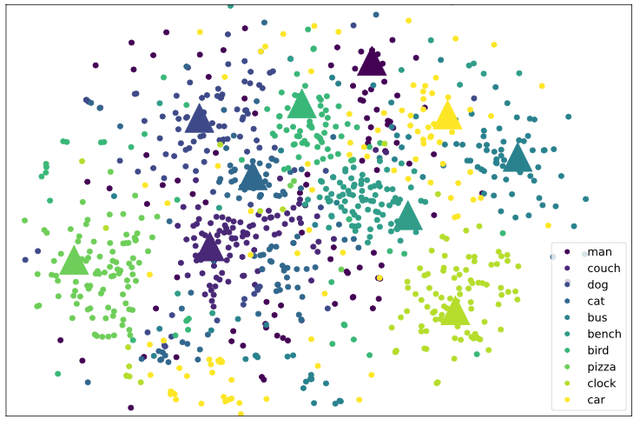
在 MVPTR 中该研究显式学习了短语级、物体级的概念 , 研究者通过可视化学习到的概念 embedding 表征来验证两者间存在嵌套层次关系 。 如下图所示 , 研究者使用 t-SNE 将学习到的 embedding 降维到 2 维 , 选择了几个常见的物体概念(三角形)和包含该物体概念的短语概念(圆点)进行呈现:
文章图片
可以从图中看到明显的层次化特点:物体级别的概念作为聚类的中心 , 与其相关的短语级概念分布在其周围 , 出现在各种场景中的 man 和 car 分布很广泛 , cat/dog/bird 都为动物分布很接近 。
短语指代可视化
为了显式展现 MVPTR 学习到的短语级别概念的对齐 , 该研究使用 WPG 中的短语 - 区域间的相似度 , 对每个短语展示了与其语义相似度最高的区域 , 以下展现了一个 MSCOCO 测试集中的例子:

文章图片
参考文献
[1] Li, Junnan, et al. "Align before fuse: Vision and language representation learning with momentum distillation." Advances in Neural Information Processing Systems 34 (2021).
[2] Radford, Alec, et al. "Learning transferable visual models from natural language supervision." International Conference on Machine Learning. PMLR, 2021.
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。