机器之心报道
编辑:陈萍、小舟
模型越大 , 超参数(HP)调优成本越高 , 微软联合 OpenAI 提出 HP 调优新范式 , 单个 GPU 上就可以调优 GPT-3 超参数 。伟大的科学成就不能仅靠反复试验取得 。 例如太空计划中的每一次发射都是基于数百年的空气动力学、推进和天体等基础研究 。 同样 , 在构建大规模人工智能系统时 , 基础研究大大减少了试错次数 , 效益明显 。
超参数(Hyperparameter , HP)调优是深度学习的关键 , 但也是一个昂贵的过程 , 对于具有数十亿参数的神经网络来说更是如此 。 假如 HP 选择不当 , 会导致模型性能不佳、训练不稳定 。 当训练超大型深度学习模型时 , 这些问题更加严重 。
最近 , 有研究 [54] 表明不同的神经网络参数化会导致不同的无限宽度限制(infinitewidth limits) , 他们提出了最大更新参数化(Maximal Update Parametrization , μP) , 该方法可以在限制内实现「最大」特征学习 。 直观地说 , 它确保每一层在训练期间以相同的顺序更新 , 而不管宽度如何 。 相比之下 , 虽然标准参数化 (standard parametrization , SP) 在初始化时保证了激活是单位顺序的 , 但实际上在训练 [54] 时 , 由于每层学习率的不平衡 , 导致激活在宽模型中爆炸 。
来自微软和 OpenAI 的研究者首次提出了基础研究如何调优大型神经网络(这些神经网络过于庞大而无法多次训练) 。 他们通过展示特定参数化保留不同模型大小的最佳超参数来实现这一点 。 利用 μP 将 HP 从小型模型迁移到大型模型 。 也就是说 , 该研究在大型模型上获得了接近最优的 HP 。
论文作者之一、来自微软的 Greg Yang 表示:「你不能在单个 GPU 上训练 GPT-3 , 更不用说调优它的超参数(HP)了 。 但是由于新的理论进步 , 你可以在单个 GPU 上调优 HP ?」
本文的想法非常简单 , 论文中引入了一种特殊参数化 μP , 窄和宽的神经网络共享一组最优超参数 。 即使宽度→∞也是如此 。
文章图片
具体而言 , 该研究证明 , 在 μP 中 , 即使模型大小发生变化 , 许多最优的 HP 仍保持稳定 。 这导致一种新的 HP 调优范式:μTransfer , 即在 μP 中对目标模型进行参数化 , 并在较小的模型上间接调优 HP , 将其零样本迁移到全尺寸模型上 , 无需调优后者 。 该研究在 Transformer 和 ResNet 上验证 μTransfer , 例如 , 1)通过从 13M 参数的模型中迁移预训练 HP , 该研究优于 BERT-large (350M 参数) , 总调优成本相当于一次预训练 BERT-large;2)通过从 40M 参数迁移 , 该研究的性能优于已公开的 6.7B GPT-3 模型 , 调优成本仅为总预训练成本的 7% 。

文章图片
- 论文地址:https://arxiv.org/pdf/2203.03466.pdf
- 项目地址:https://github.com/microsoft/mup
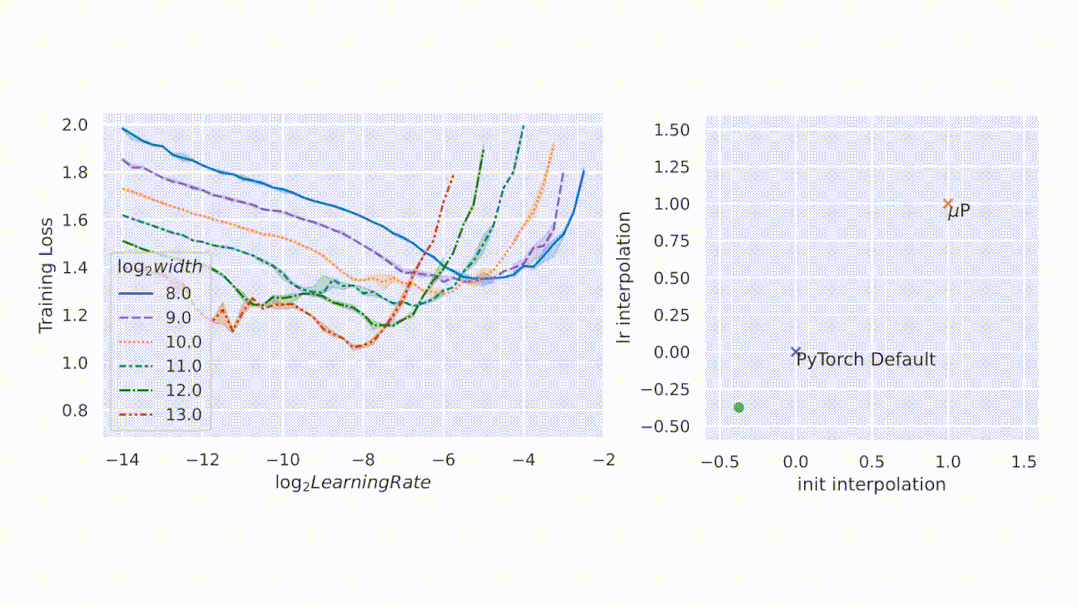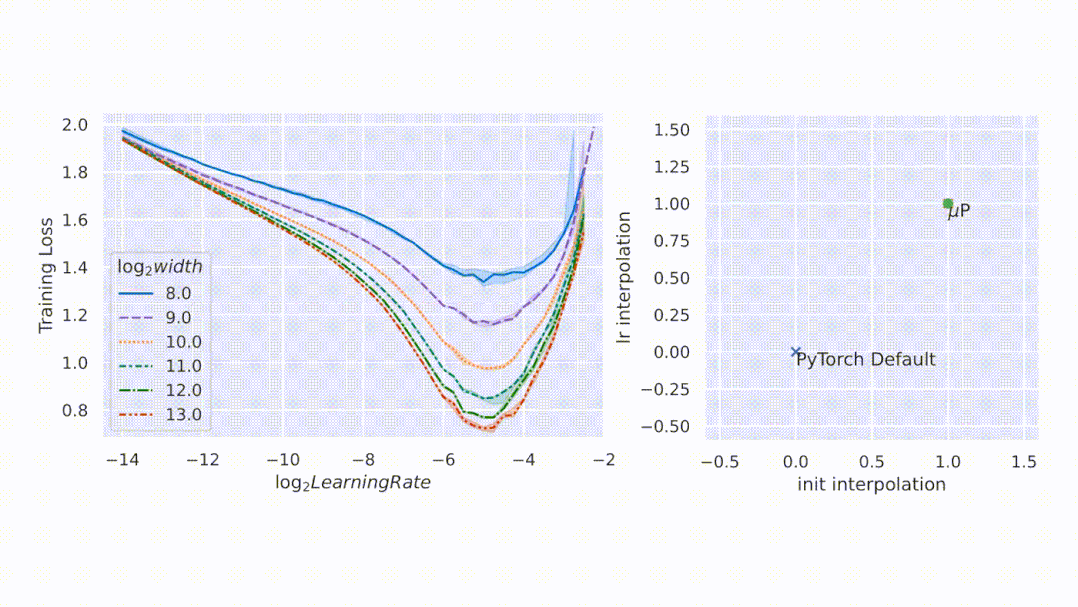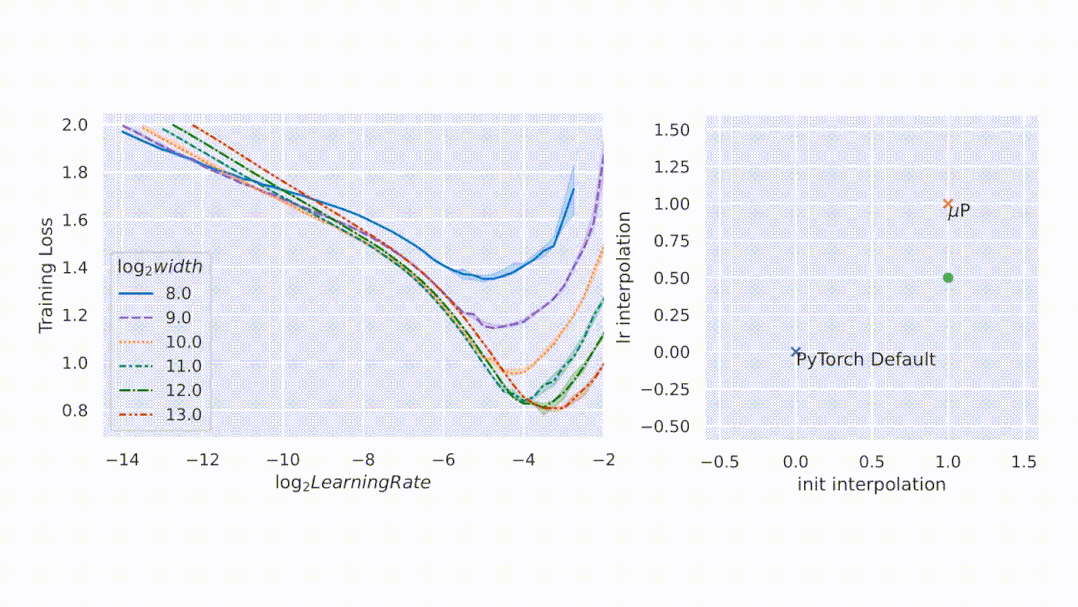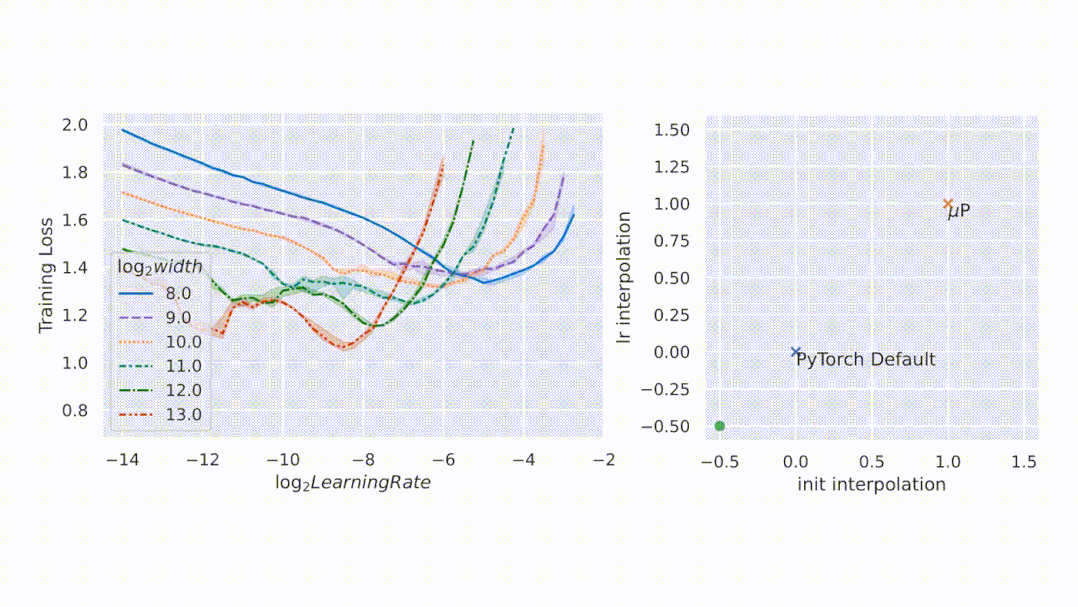
文章图片
扩展初始化容易 , 但扩展训练难
大型神经网络很难训练 , 部分原因是不了解其行为如何随着规模增加而变化 。 在深度学习的早期工作中 , 研究者采用启发式算法 。 一般来说 , 启发式方法试图在模型初始化时保持激活扩展一致 。 然而 , 随着训练的开始 , 这种一致性会在不同的模型宽度处中断 , 如图 1 左侧所示 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。