探索实验
为了搞明白大 kernel 到底应该怎么用 , 我们在 MobileNet V2 上进行了一系列探索实验 , 总结出五条准则 。 这里略去细节只说结论:
1. 用 depth-wise 大 kernel , 完全可以做到相当高效 。 在我们的优化(已经集成进开源框架 MegEngine)下 , 31x31 depth-wise 卷积的用时最低可达 3x3 卷积的 1.5 倍 , 而前者的 FLOPs 是后者的 106 倍(31x31/9) , 这意味着前者的效率是后者的 71 倍!
2. 不带 identity shortcut , 增大 kernel 会大幅掉点(ImageNet 掉了 15%);带 shortcut , 增大 kernel 才会涨点 。
3. 如果要想进一步加大 kernel size , 从大 kernel 到超大 kernel , 可以用小 kernel 做结构重参数化(参考文献 1) 。 也就是说 , 在训练的时候并行地加一个 3x3 或 5x5 卷积 , 训练完成后将小 kernel 等价合并到大 kernel 里面去 。 这样 , 模型就可以有效捕捉到不同尺度的特征 。 不过我们发现 , 数据集越小、模型越小 , 重参数化越重要 。 反之 , 在我们的超大规模数据集 MegData73M 上 , 重参数化提升很小(0.1%) 。 这一发现跟 ViT 类似:数据规模越大 , inductive bias 越不重要 。
4. 我们要的是在目标任务上涨点 , 而不是 ImageNet 上涨点 , ImageNet 的精度跟下游任务不一定相关 。 随着 kernel size 越来越大 , ImageNet 上不再涨点 , 但是 Cityscapes、ADE20K 语义分割上还能涨一到两个点 , 而增大 kernel 带来的额外的参数量和计算量很少 , 性价比极高!
5. 有点反直觉的是 , 在 7x7 的小 feature map 上用 13x13 也可以涨点!也就是说 , 大 kernel 模型不一定需要大分辨率来训 , 跟小 kernel 模型差不多的训练方法就可以 , 又快又省!
RepLKNet:超大卷积核架构
我们以 Swin 作为主要的对比对象 , 并无意去刷 SOTA , 所以简单借鉴 Swin 的宏观架构设计了一种超大卷积核架构 。 这一架构主要在于把 attention 换成超大卷积和与之配套的结构 , 再加一点 CNN 风格的改动 。 根据以上五条准则 , RepLKNet 的设计元素包括 shortcut、depth-wise 超大 kernel、小 kernel 重参数化等 。
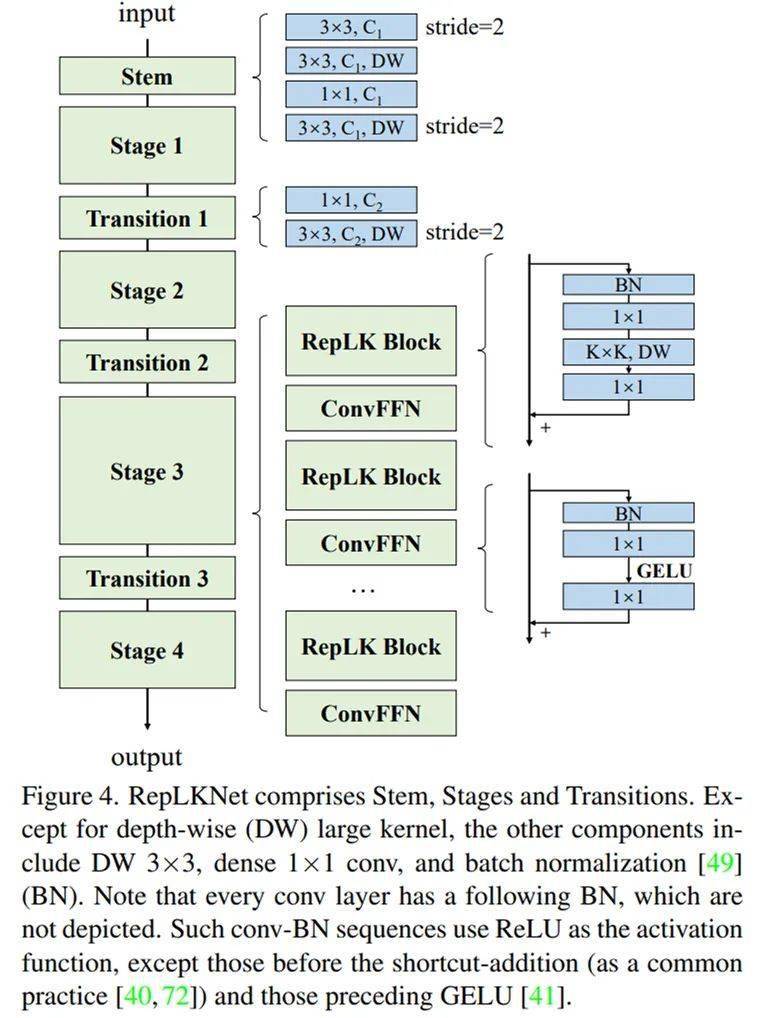
文章图片
整体架构图 。
增大 kernel size:越大越暴力!
我们给 RepLKNet 的四个 stage 设定不同的 kernel size , 在 ImageNet 和 ADE20K 语义分割数据集上进行实验 , 结果颇为有趣:ImageNet 上从 7x7 增大到 13x13 还能涨点 , 但从 13x13 以后不再涨点;但是在 ADE20K 上 , 从四个 stage 均为 13 增大到四个 stage 分别为 31-29-27-13 , 涨了 0.82 的 mIoU , 参数量只涨了 5.3% , FLOPs 只涨了 3.5% 。
所以 , 后面的实验主要用 31-29-27-13 的 kernel size , 称为 RepLKNet-31B , 并将其整体加宽为 1.5 倍 , 称为 RepLKNet-31L 。
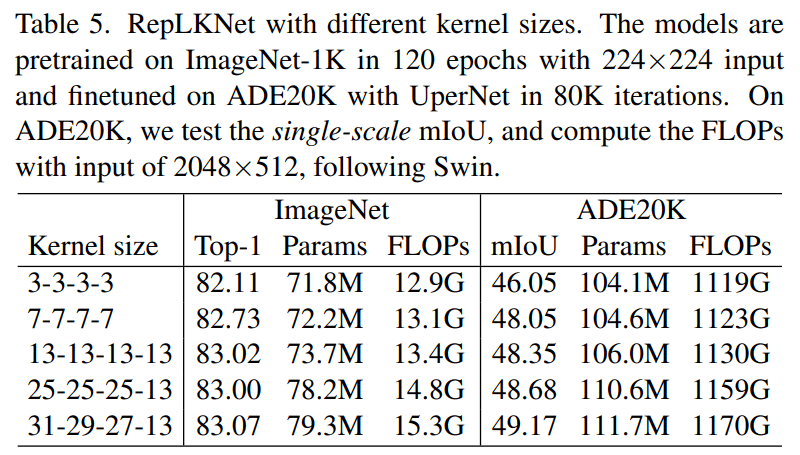
文章图片
Cityscapes 语义分割
RepLKNet-31B 的体量略小于 Swin-Base , 在仅仅用 ImageNet-1K pretrain 前提下 , mIoU 超过 Swin-Large + ImageNet-22K , 完成了跨模型量级、跨数据量级的超越 。
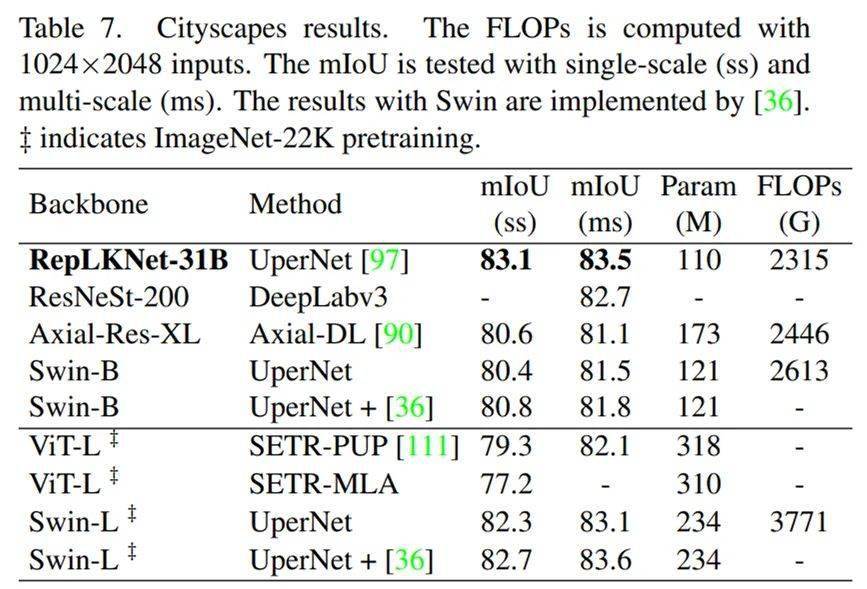
文章图片
Cityscapes 结果 。
ADE20K 语义分割
RepLKNet 相当能打 , 特别是 Base 级别 。 跟量级差不多的 ResNet 相比 , mIoU 高了 6.1 , 体现出了少量大 kernel 相对于大量小 kernel 的显著优势 。 (COCO 目标检测上也有相同结论 , RepLKNet-31B 的 mAP 比体量相当的 ResNeXt-101 高了4.4)RepLKNet-XL 是更大级别的模型 , 用私有数据集 MegData-73M 进行预训练 , 达到了 56.0 的 mIoU(跟 ViT-L 相比 , 这个模型其实并不算很大) 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。