文章图片
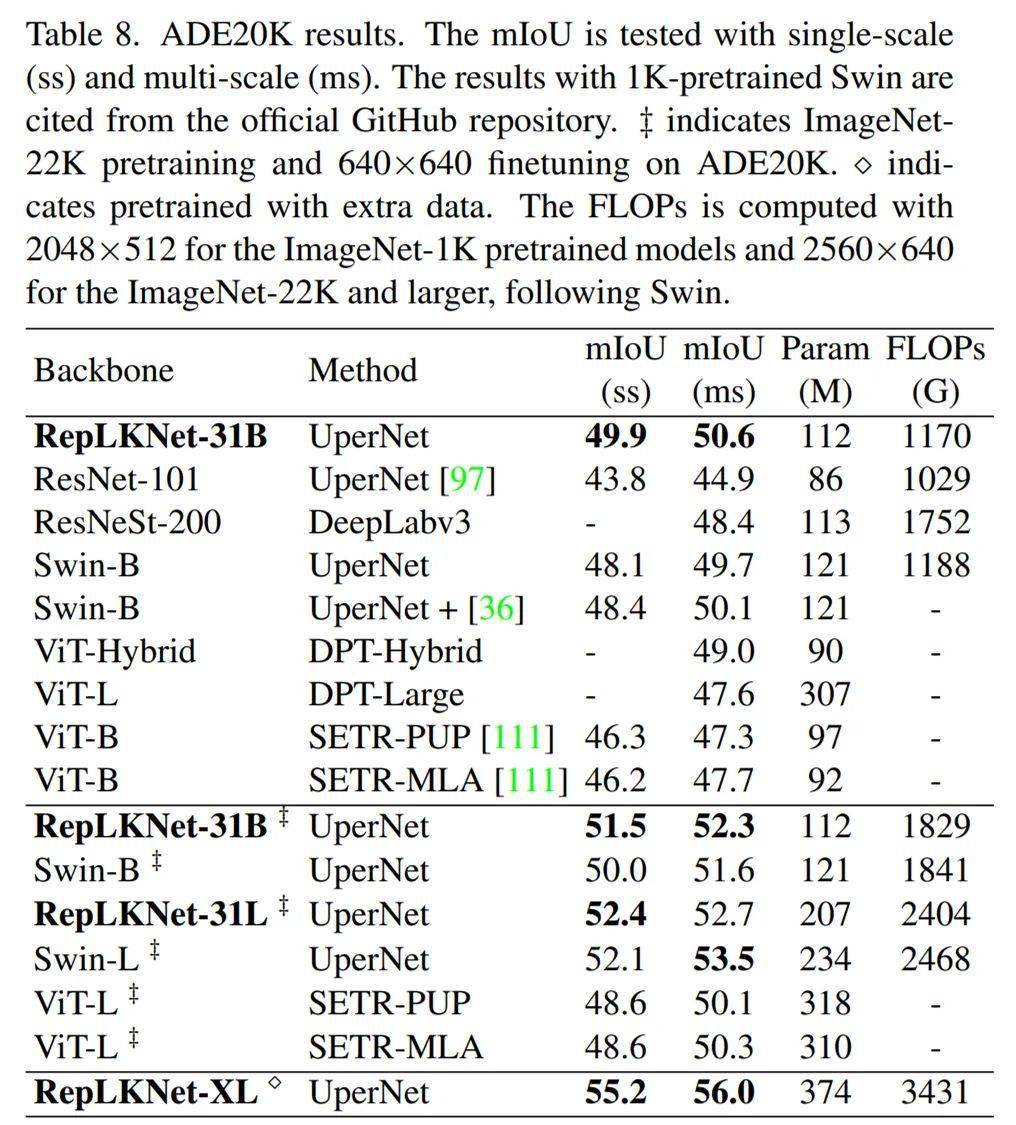
ADE20K 结果 。
ImageNet 分类、COCO 目标检测结果参见「太长不看」部分或论文 。
讨论与分析
有效感受野:大 kernel 模型远超深层小 kernel 模型
我们可视化了 RepLKNet-31、RepLKNet-13(前文所说的每个 stage 都是 13x13 的模型)、ResNet-101、ResNet-152 的有效感受野(方法详见论文)发现 ResNet-101 的有效感受野其实很小 , 而且 ResNet-152 相对于 101 的提升也很小;RepLKNet-13 的有效感受野很大 , 而 RepLKNet-31 通过增大 kernel size 进一步将有效感受野变得非常大 。

文章图片
Shape bias:大 kernel 模型更像人类
我们又研究了模型的 shape bias(即模型有多少比例的预测是基于形状而非纹理做出的) , 人类的 shape bias 在 90% 左右 , 见下图左边的菱形点 。 我们选用的模型包括 Swin、ResNet152、RepLKNet-31 和 RepLKNet-3(前文提到的每个 stage 都是 3x3 的小 kernel baseline) , 发现 RepLKNet-3 和 ResNet-152 的 kernel size 一样大(3x3) , shape bias 也非常接近(图中的两条竖直实线几乎重合) 。
有意思的是 , 关于 shape bias 的一项工作提到 ViT(全局 attention)的 shapebias 很高(参见参考文献 3 中的图) , 而我们发现 Swin(窗口内局部 attention)的 shape bias 其实不高(下图) , 这似乎说明 attention 的形式不是关键 , 作用的范围才是关键 , 这也解释了 RepLKNet-31 的高 shape bias(即更像人类) 。
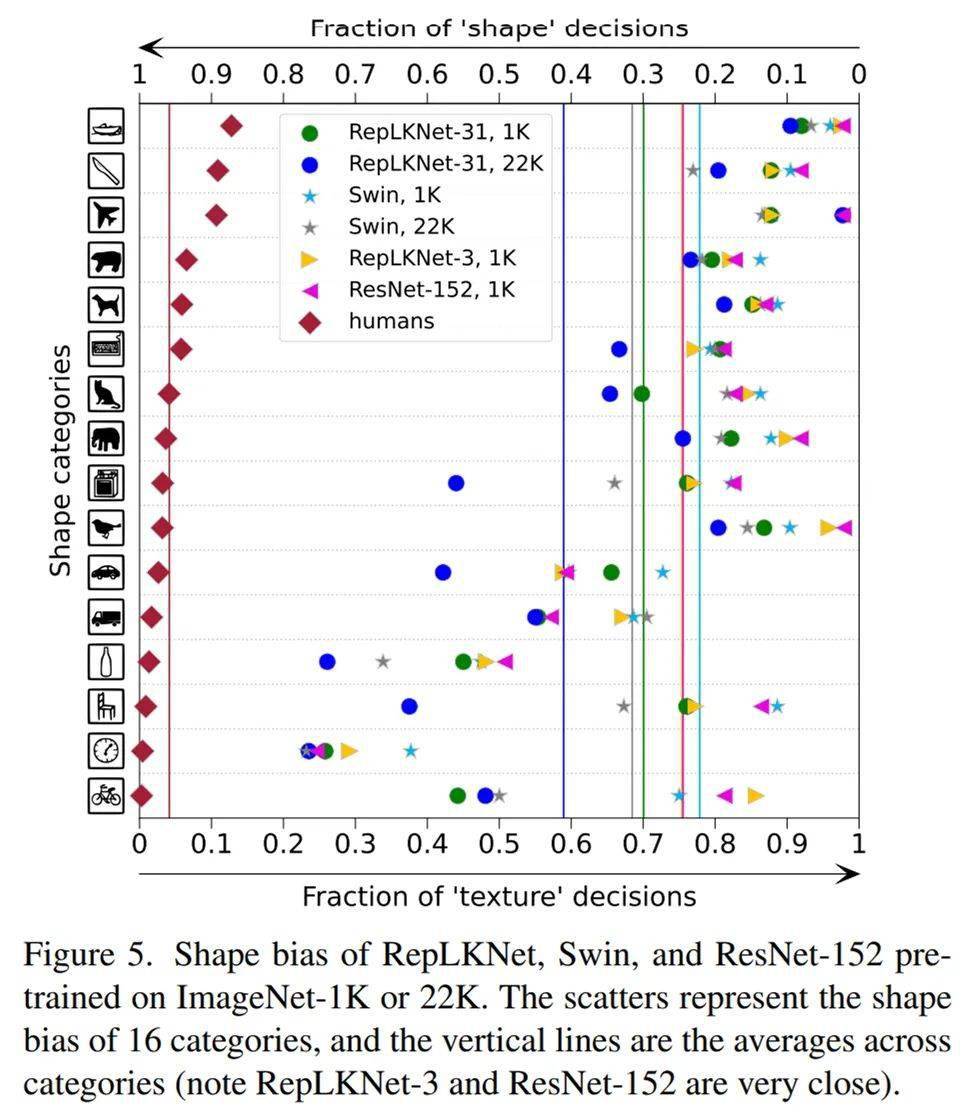
文章图片
shape bias 对比
MegEngine 对大 kernel 的强力优化
以往大家不喜欢用大 kernel 的其中一个原因是其较低的运行效率 。 但旷视开源的深度学习框架 MegEngine 通过分析和实验发现大 kernel depth-wise 卷积仍有很大的优化潜力 , 其运行时间可能不会显著慢于小 kernel(延展阅读 https://zhuanlan.zhihu.com/p/479182218) 。
MegEngine 针对大 kernel depthwise 卷积做了多种深度优化 , 优化后的 MegEngine 性能比 PyTorch 最高快 10 倍 , 31x31 大小卷积核上的运行时间几乎和 9x9 大小卷积核的运行时间差不多 , 可以打满设备的浮点理论峰值 。 MegEngine 用实际数据在一定意义上打消了大家对大 kernel 卷积运行效率的疑虑 。 这些优化已经集成到了 MegEngine 中 , 欢迎使用~
知乎原文:https://zhuanlan.zhihu.com/p/481445076?utm_source=wechat_session&utm_medium=social&utm_oi=56560353017856&utm_campaign=shareopn
—版权声明—
来源:知乎@丁霄汉 , 编辑:nhyilin
仅用于学术分享 , 版权属于原作者 。
若有侵权 , 请联系微信号:Eternalhui或nhyilin删除或修改!
—THE END—
? 缅怀中国“布鞋院士”李小文
? 美国著名核物理学家 , 前半生为美国造核弹 , 后半生为中国放牛
? 一分钟看懂一维空间到十维空间
? 爱因斯坦鲜为人知的另一面
? 拉马努金的那些壮观的公式 , 都是怎么发现的?
【大到31x31的超大卷积核,涨点又高效,一作解读RepLKNet】? 法国数学长盛不衰的历史渊源
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。