你有多久没调过 kernel size 了?虽然常常被人忽略 , 但只要将其简单加大 , 就能给人惊喜 。
>>>>
当你在卷积网络(CNN)的深度、宽度、groups、输入分辨率上调参调得不可开交的时候 , 是否会在不经意间想起 , 有一个设计维度 kernel size , 一直如此显而易见却又总是被忽视 , 总是被默认设为 3x3 或 5x5?
当你在 Transformer 上调参调得乐不思蜀的时候 , 是否希望有一种简单、高效、部署容易、下游任务性能又不弱于 Transformer 的模型 , 带给你朴素的快乐?
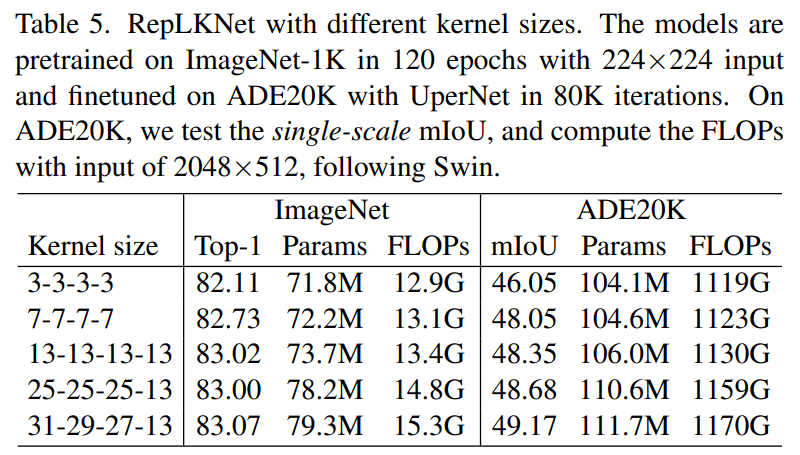
近日 , 清华大学、旷视科技等机构的研究者发表于 CVPR 2022 的工作表明 , CNN 中的 kernel size 是一个非常重要但总是被人忽略的设计维度 。 在现代模型设计的加持下 , 卷积核越大越暴力 , 既涨点又高效 , 甚至大到 31x31 都非常 work(如下表 5 所示 , 左边一栏表示模型四个 stage 各自的 kernel size)!
即便在大体量下游任务上 , 我们提出的超大卷积核模型 RepLKNet 与 Swin 等 Transformer 相比 , 性能也更好或相当!

文章图片
- 论文地址:https://arxiv.org/abs/2203.06717
- MegEngine 代码和模型:https://github.com/megvii-research/RepLKNet
- PyTorch 代码和模型:https://github.com/DingXiaoH/RepLKNet-pytorch
文章图片
太长不看版
以下是两分钟内可以看完的内容总结 。
A. 我们对业界关于 CNN 和 Transformer 的知识和理解有何贡献?
我们挑战了以下习惯认知:
1. 超大卷积不但不涨点 , 而且还掉点?我们证明 , 超大卷积在过去没人用 , 不代表其现在不能用 。 人类对科学的认知总是螺旋上升的 , 在现代 CNN 设计(shortcut、重参数化等)的加持下 , kernel size 越大越涨点!
2. 超大卷积效率很差?我们发现 , 超大 depth-wise 卷积并不会增加多少 FLOPs 。 如果再加点底层优化 , 速度会更快 , 31x31 的计算密度最高可达 3x3 的 70 倍!
3. 大卷积只能用在大 feature map 上?我们发现 , 在 7x7 的 feature map 上用 13x13 卷积都能涨点 。
4. ImageNet 点数说明一切?我们发现 , 下游(目标检测、语义分割等)任务的性能可能跟 ImageNet 关系不大 。
5. 超深 CNN(如 ResNet-152)堆叠大量 3x3 , 所以感受野很大?我们发现 , 深层小 kernel 模型有效感受野其实很小 。 反而少量超大卷积核的有效感受野非常大 。
6. Transformers(ViT、Swin 等)在下游任务上性能强悍 , 是因为 self-attention(Query-Key-Value 的设计形式)本质更强?我们用超大卷积核验证 , 发现kernel size 可能才是下游涨点的关键 。
B. 我们做了哪些具体的工作?
1. 通过一系列探索性的实验 , 总结了在现代 CNN 中应用超大卷积核的 五条准则:
- 用 depth-wise 超大卷积 , 最好再加底层优化( 已集成进开源框架 MegEngine )
- 加 shortcut
- 用小卷积核做重参数化(即 结构重参数化方法论, 见我们去年的 RepVGG , 参考文献 [1])
- 要看下游任务的性能 , 不能只看 ImageNet 点数高低
- 小 feature map 上也可以用大卷积 , 常规分辨率就能训大 kernel 模型
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。