文章图片
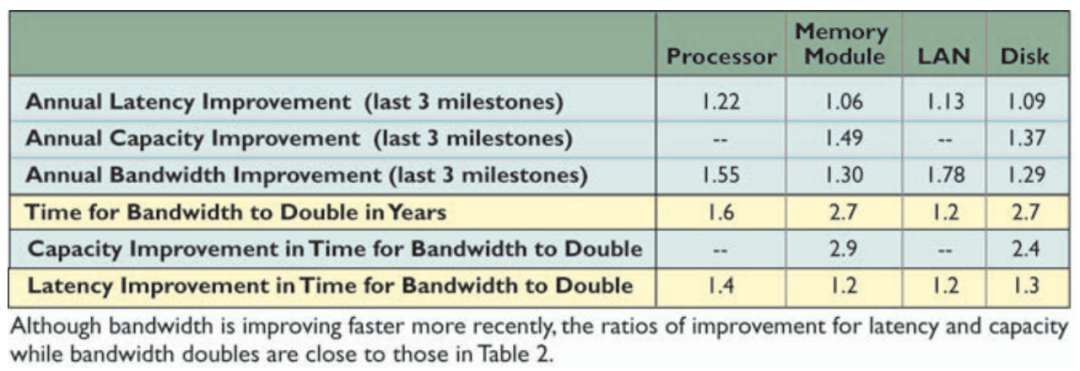
一种理解计算的方式是把它想象成工厂 。 我们把指令传达给我们的工厂(额外消耗) , 把原始材料送给它(内存带宽) , 所有这些都是为了让工厂运行得更加高效(计算) 。
文章图片
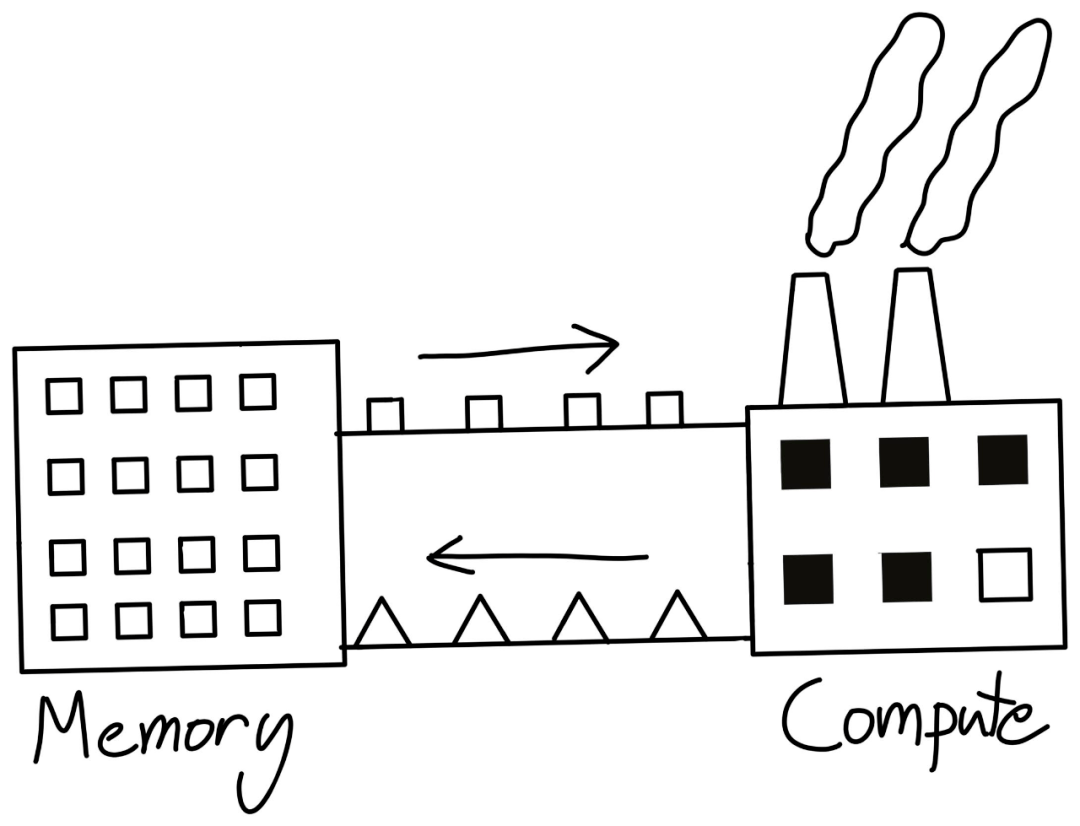
所以 , 如果工厂容量扩展的速度高于我们提供给它原材料的速度 , 它就很难达到一个顶峰效率 。
文章图片
即使我们工厂容量(FLOP)翻倍 , 但带宽跟不上 , 我们的性能也不能翻倍 。
关于 FLOPS 还有一点要说 , 越来越多的机器学习加速器都有专门针对矩阵乘法的硬件配置 , 例如英伟达的「Tensor Cores」 。

文章图片
所以 , 你要是不做矩阵乘法的话 , 你只能达到 19.5 万亿次运算 , 而不是 312 万亿次 。 注意 , 并不是只有 GPU 这么特殊 , 事实上 TPU 是比 GPU 更加专门化的计算模块 。
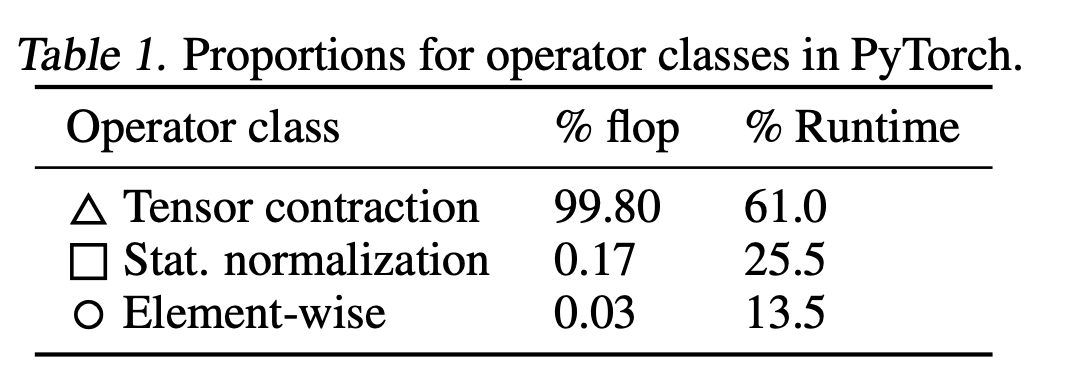
除了矩阵乘法以外 , GPU 处理其他运算时都比较慢 , 这一现象乍看上去似乎有问题:比如像是层归一化或者激活函数的其它算子怎么办呢?事实上 , 这些算子在 FLOPS 上仅仅像是矩阵乘法的舍入误差一样 。 例如 , 看看下表对于 BERT 中的不同算子类型占用的 FLOP 数 , 其中的「Tensor Contraction」就是指矩阵乘法 。
文章图片
可以看到 , 非矩阵乘法运算仅仅占所有运算的 0.2% , 所以即使它们的速度仅为矩阵乘法的 1/15 也没什么问题 。
事实上 , 归一化运算和逐点(pointwise)运算使用的 FLOPS 仅为矩阵乘法的 1/250 和 1/700 。 那为什么非矩阵乘法运算会远比它们应该使用的运行时间更多呢?
回到前文「工厂」的类比 , 罪魁祸首经常还是如何将原始材料运到以及运出工厂 , 换句话说 , 也就是「内存带宽」 。
带宽
带宽消耗本质上是把数据从一个地方运送到另一个地方的花费 , 这可能是指把数据从 CPU 移动到 GPU , 从一个节点移动到另一个节点 , 甚至从 CUDA 的全局内存移动到 CUDA 的共享内存 。 最后一个是本文讨论的重点 , 我们一般称其为「带宽消耗」或者「内存带宽消耗」 。 前两者一般叫「数据运输消耗」或者「网络消耗」 , 不在本文叙述范围之内 。
还是回到「工厂」的类比 。 虽然我们在工厂中从事实际的工作 , 但它并不适合大规模的存储 。 我们要保证它的存储是足够高效的 , 并且能够很快去使用(SRAM) , 而不是以量取胜 。
那么我们在哪里存储实际的结果和「原材料」呢?一般我们要有一个仓库 , 那儿的地足够便宜 , 并且有大量的空间(DRAM) 。 之后我们就可以在它和工厂之间运送东西了(内存带宽) 。
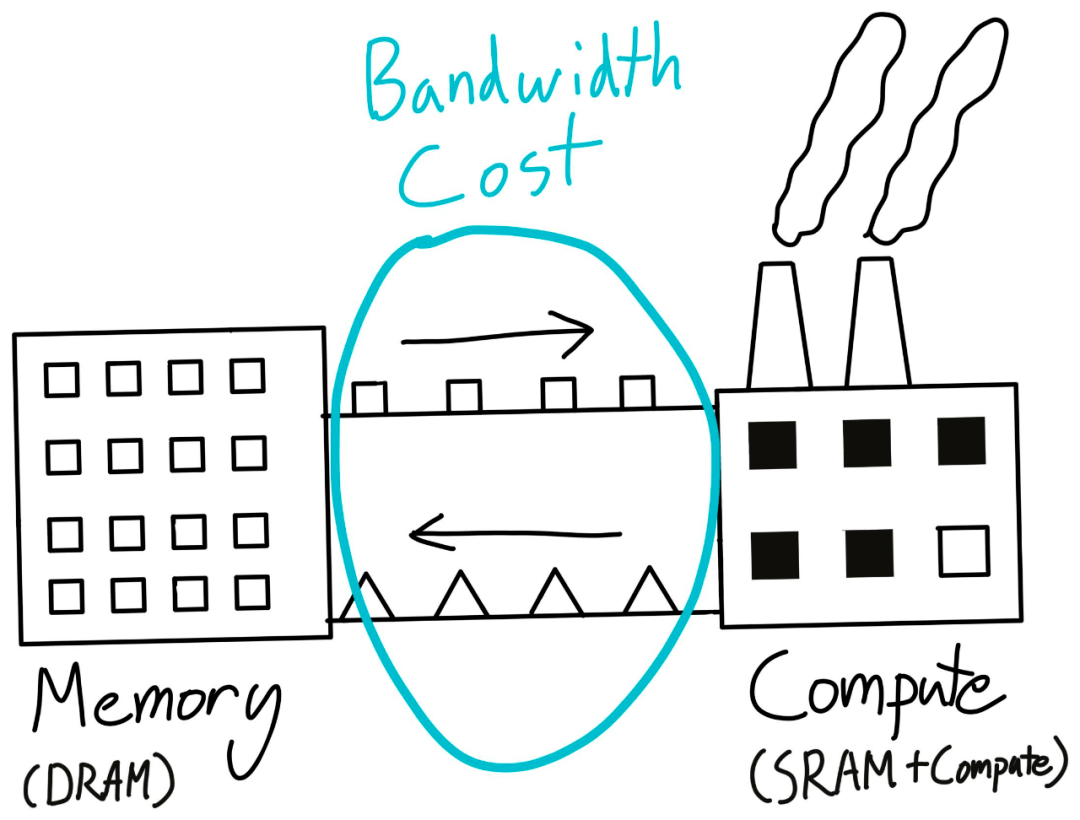
文章图片
这种在计算单元之间移动东西的成本就是所谓的「内存带宽」成本 。 事实上 , nvidia-smi 命令中出现的那个「内存」就是 DRAM , 而经常让人抓狂的「CUDA out of memory」说的就是这个 DRAM 。
值得注意的是:我们每执行一次 GPU 核运算都需要把数据运出和运回到我们的仓库 ——DRAM 。
现在想象一下 , 当我们执行一个一元运算(如 torch.cos)的时候 , 我们需要把数据从仓库(DRAM)运送到工厂(SRAM) , 然后在工厂中执行一小步计算 , 之后再把结果运送回仓库 。 运输是相当耗时的 , 这种情况下 , 我们几乎把所有的时间都花在了运输数据 , 而不是真正的计算上 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。