具体来说 , 假设我们对这段代码进行基准测试 , 首先要找出每秒执行的迭代次数;然后执行 2N(N 是张量大小)次内存访问和 N *repeat FLOP 。 因此 , 内存带宽将是 bytes_per_elem * 2 * N /itrs_per_second , 而 FLOPS 是 N * repeat /itrs_per_second 。
现在 , 让我们绘制计算强度的 3 个函数图象:运行时间、flops 和内存带宽 。
文章图片
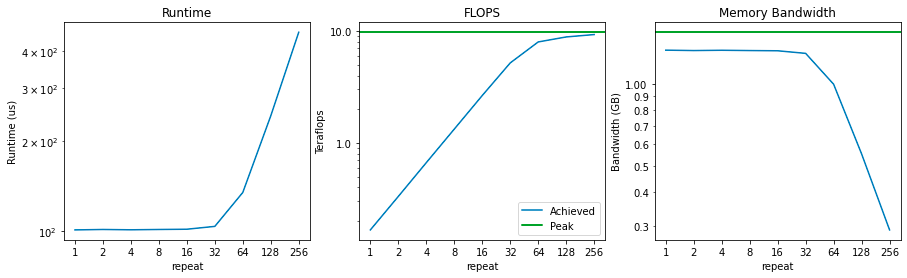
请注意 , 在执行 64 次乘法之前 , 运行时间根本不会显著增加 。 这意味着在此之前主要受内存带宽的限制 , 而计算大多处于空闲状态 。
一开始 FLOPS 的值是 0.2 teraflops 。 当我们将计算强度加倍时 , 这个数字会线性增长 , 直到接近 9.75 teraflops 的峰值 , 一旦接近峰值 teraflops 就被认为是「计算受限的」 。
最后 , 可以看到内存带宽从峰值附近开始 , 随着我们增加计算强度开始下降 。 这正是我们所期待的 , 因为这说明执行实际计算的时间越来越多 , 而不是访问内存 。
在这种情况下 , 很容易看出何时受计算限制以及何时受内存限制 。 repeat< 32 时 , 内存带宽接近饱和 , 而未进行充分的计算;repeat> 64 时 , 计算接近饱和(即接近峰值 FLOPS) , 而内存带宽开始下降 。
对于较大的系统 , 通常很难说是受计算限制还是内存带宽限制 , 因为它们通常包含计算限制和内存限制两方面的综合原因 。 衡量计算受限程度的一种常用方法是计算实际 FLOPS 与峰值 FLOPS 的百分比 。
然而 , 除了内存带宽成本之外 , 还有一件事可能会导致 GPU 无法丝滑运行 。
额外开销
当代码把时间花费在传输张量或计算之外的其他事情上时 , 额外开销(overhead)就产生了 , 例如在 Python 解释器中花费的时间、在 PyTorch 框架上花费的时间、启动 CUDA 内核(但不执行)所花费的时间 ,这些都是间接开销 。
额外开销显得重要的原因是现代 GPU 的运算速度非常快 。 A100 每秒可以执行 312 万亿次浮点运算(312TeraFLOPS) 。 相比之下 Python 实在是太慢了 ——Python 在一秒内约执行 3200 万次加法 。
这意味着 Python 执行单次 FLOP 的时间 , A100 可能已经运行了 975 万次 FLOPS 。
更糟糕的是 , Python 解释器甚至不是唯一的间接开销来源 , 像 PyTorch 这样的框架到达 actual kernel 之前也有很多层调度 。 PyTorch 每秒大约能执行 28 万次运算 。 如果使用微型张量(例如用于科学计算) , 你可能会发现 PyTorch 与 C++ 相比非常慢 。
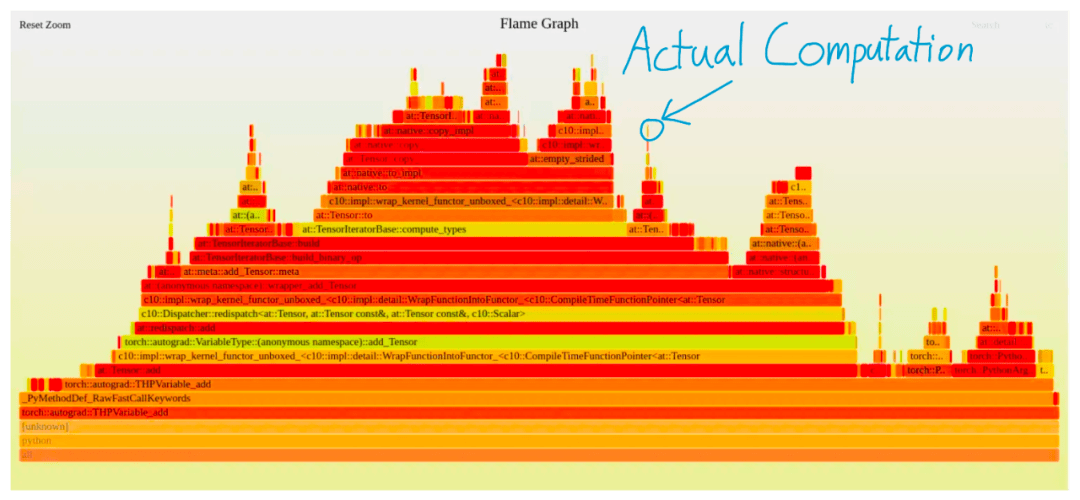
例如在下图中 , 使用 PyTorch 执行单次添加 , 仅有一小块图是实际执行计算的内容 , 其他的部分都是纯粹的额外开销 。
文章图片
鉴于此 , 你可能会对 PyTorch 成为主流框架的现象感到不解 , 而这是因为现代深度学习模型通常执行大规模运算 。 此外 , 像 PyTorch 这样的框架是异步执行的 。 因此 , 大部分框架开销可以完全忽略 。
文章图片
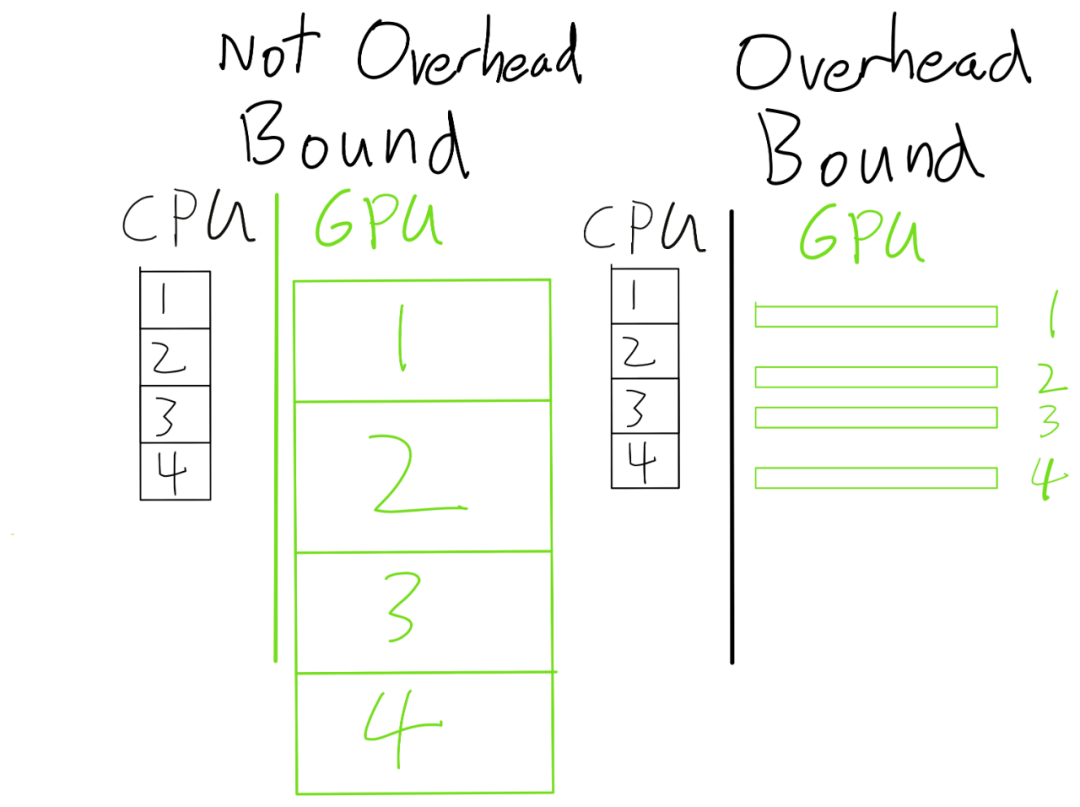
如果我们的 GPU 算子足够大 , 那么 CPU 可以跑在 GPU 之前(因此 CPU 开销是无关紧要的) 。 另一方面 , 如果 GPU 算子太小 , 那么 GPU 将在 paperweight 上花费大部分时间 。
那么 , 如何判断你是否处于这个问题中?由于额外开销通常不会随着问题的规模变化而变化(而计算和内存会) , 所以最简单的判断方法是简单地增加数据的大小 。 如果运行时间不是按比例增加 , 应该可以说遇到了开销限制 。 例如 , 如果将批大小翻倍 , 但运行时间仅增加 10% , 则可能会受到开销限制 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。