
文章图片
Hopper 还引入了 DPX 指令集 , 旨在加速动态编程算法 。 动态编程可将复杂问题分解为子问题递归解决 , Hopper DPX 指令集把这种任务的处理时间缩短了 40 倍 。
Hopper 架构的芯片和 HBM 3 内存用台积电 CoWoS 2.5D 工艺封装在板卡上 , 形成「超级芯片模组 SXM」 , 就是一块 H100 加速卡:

文章图片
这块显卡拿着可得非常小心——它看起来整体异常紧凑 , 整个电路板上塞满各种元器件 。 另一方面 , 这样的结构也适用于液冷——H100 设计 700W 的 TDP 已经非常接近散热处理的上限了 。
自建全球第一 AI 超算
「科技公司处理、分析数据 , 构建 AI 软件 , 已经成为智能的制造者 。 他们的数据中心就是 AI 的工厂 , 」黄仁勋说道 。
基于 Hopper 架构的 H100 , 英伟达推出了机器学习工作站、超级计算机等一系列产品 。 8 块 H100 和 4 个 NVLink 结合组成一个巨型 GPU——DGX H100 , 它一共有 6400 亿晶体管 , AI 算力 32 petaflops , HBM3 内存容量高达 640G 。
新的 NVLINK Swith System 又可以最多把 32 台 DGX H100 直接并联 , 形成一台 256 块 GPU 的 DGX POD 。
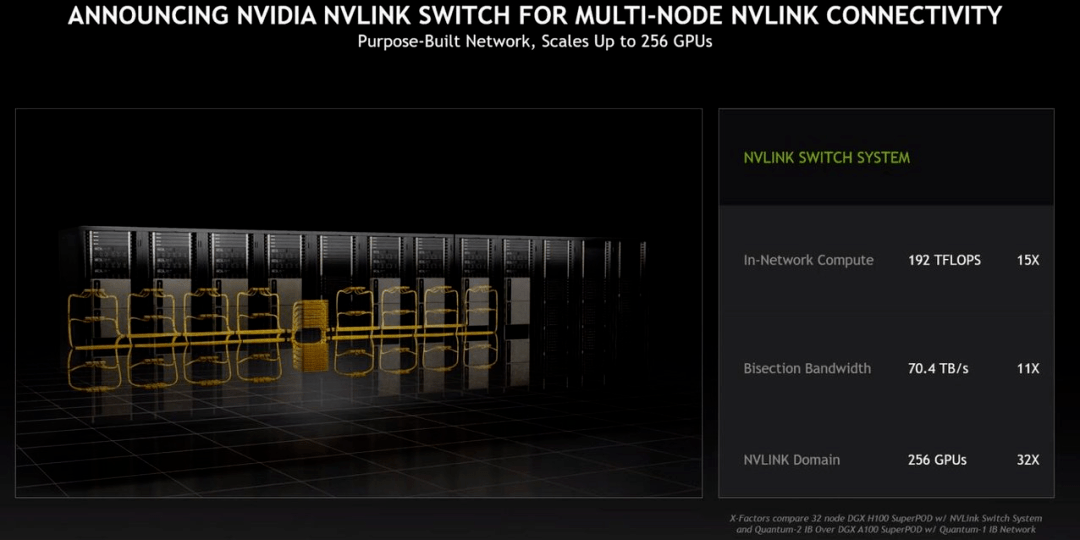
文章图片
「DGX POD 的带宽是每秒 768 terbyte , 作为对比 , 目前整个互联网的带宽是每秒 100 terbyte , 」黄仁勋说道 。

文章图片
基于新 superPOD 的超级计算机也在路上 , 英伟达宣布基于 H100 芯片即将自建一个名叫 EoS 的超级计算机 , 其由 18 个 DGX POD 组成 , 一共 4608 个 H100 GPU 。 以传统超算的标准看 , EoS 的算力是 275petaFLOPS , 是当前美国最大超算 Summit 的 1.4 倍 , Summit 目前是基于 A100 的 。
从 AI 计算的角度来看 , EoS 输出 18.4 Exaflops , 是当今全球第一超算富岳的四倍 。

文章图片
总而言之 , EoS 将会是世界上最快的 AI 超级计算机 , 英伟达表示它将会在几个月之后上线 。
下面看看 H100 在具体任务上的性能提升:单看 GPU 算力的话训练 GPT-3 速度提升 6.3 倍 , 如果结合新的精度、芯片互联技术和软件 , 提升增至 9 倍 。 在大模型的推理工作上 , H100 的吞吐量是 A100 的 30 倍 。
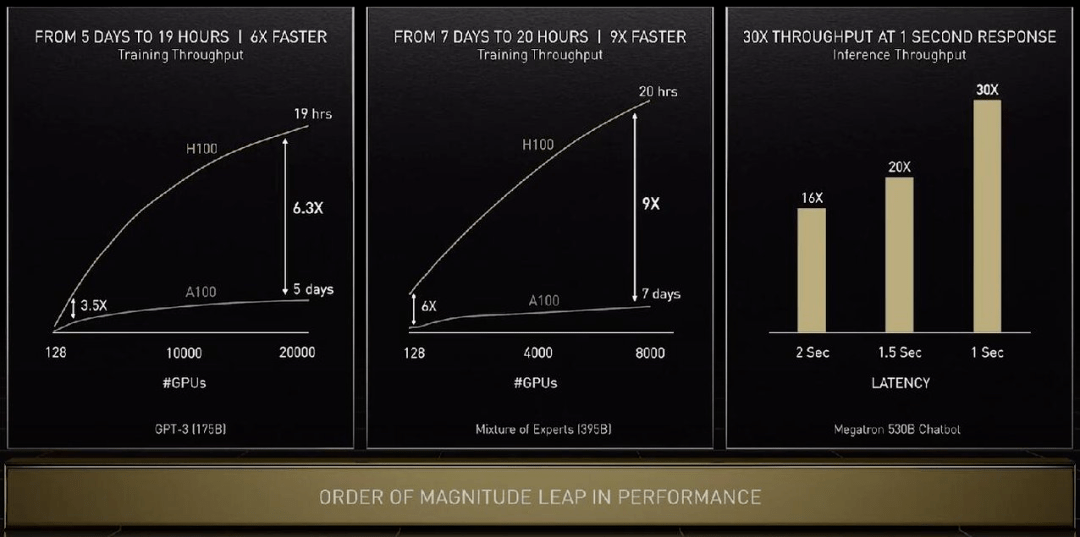
文章图片
对于传统服务器 , 英伟达提出了 H100 CNX , 通过把网络与 H100 直接并联的方式绕过 PCIE 瓶颈提升 AI 性能 。
英伟达更新了自家的服务器 CPU , 新的 Grace Hopper 可以在同一块主板上两块并联 , 形成一个拥有 144 核 CPU , 功耗 500W , 是目前产品性能的 2-3 倍 , 能效比也是两倍 。
在 Grace 上 , 几块芯片之间的互联技术是新一代 NVlink , 其可以实现晶粒到晶粒、芯片到芯片、系统到系统之间的高速互联 。 黄仁勋特别指出 , Grace CPU 与 Hopper 可以通过 NVlink 进行各种定制化配置 。 英伟达的技术可以满足所有用户需求 , 在未来英伟达的 CPU、GPU、DPU、NIC 和 SoC 都可以通过这种技术实现芯片端高速互联 。
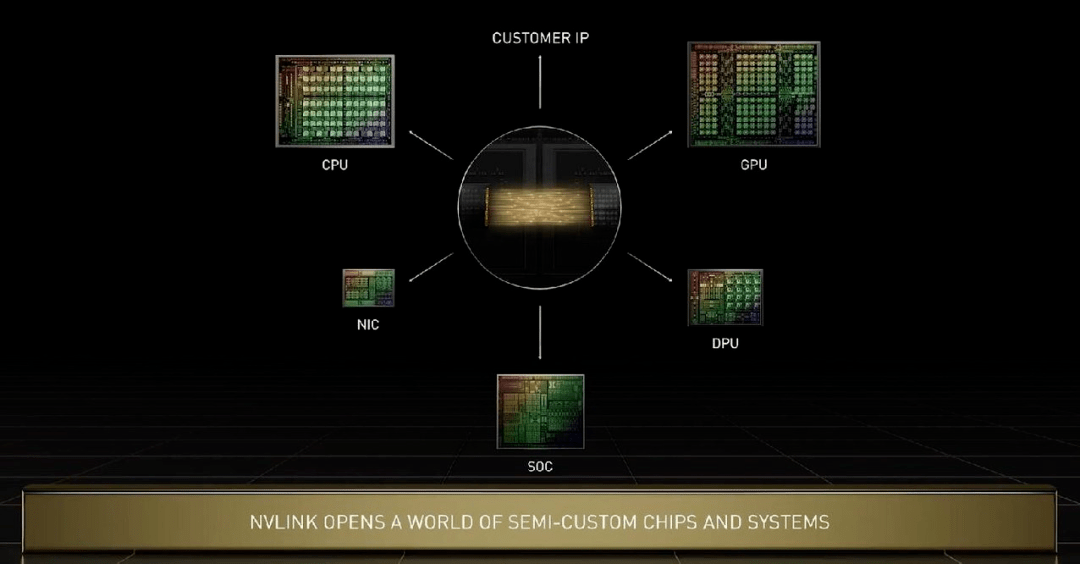
文章图片
英伟达计划在今年三季度推出配备 H100 的系统 , 包括 DGX、DGX SuperPod 服务器 , 以及来自 OEM 合作伙伴使用 HGX 基板和 PCIe 卡服务器 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。