机器之心报道
编辑;泽南、杜伟
黄仁勋:芯片每代性能都翻倍 , 而且下个「TensorFlow」级 AI 工具可是我英伟达出的 。每年春天 , AI 从业者和游戏玩家都会期待英伟达的新发布 , 今年也不例外 。
北京时间 3 月 22 日晚 , 新一年度的 GTC 大会如期召开 , 英伟达创始人、CEO 黄仁勋这次走出了自家厨房 , 进入元宇宙进行 Keynote 演讲:

文章图片
「我们已经见证了 AI 在科学领域发现新药、新化合物的能力 。 人工智能现在学习生物和化学 , 就像此前理解图像、声音和语音一样 。 」黄仁勋说道「一旦计算机能力跟上 , 像制药这样的行业就会经历此前科技领域那样的变革 。 」
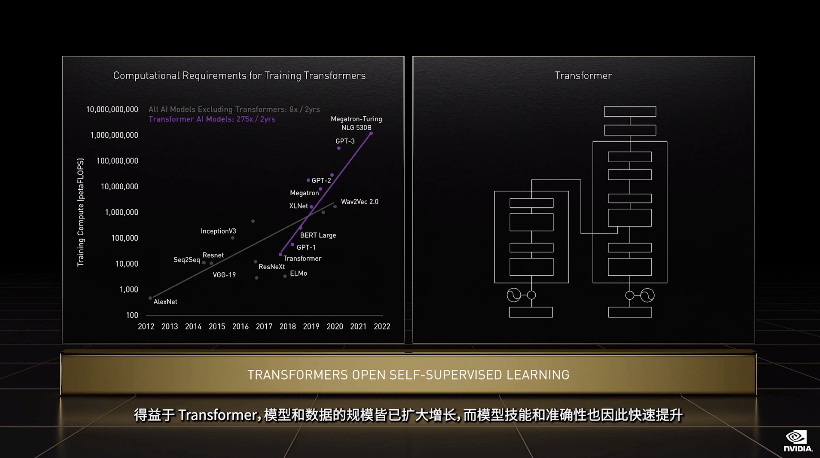
GPU 发展引爆的 AI 浪潮从开始到今天还没过去十年 , Transformer 这样的预训练模型和自监督学习模型 , 已经不止一次出现「算不起」的情况了 。
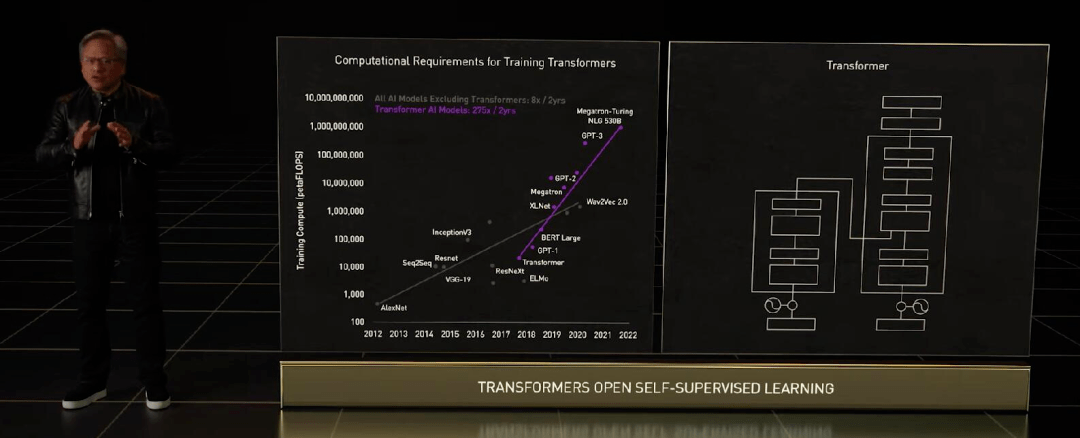
文章图片
算力需求因为大模型呈指数级上升 , 老黄这次拿出的是面向高性能计算(HPC)和数据中心的下一代 Hopper 架构 , 搭载新一代芯片的首款加速卡被命名为 H100 , 它就是 A100 的替代者 。

文章图片
Hopper 架构的名称来自于计算机科学先驱 Grace Hopper , 其延续英伟达每代架构性能翻倍的「传统」 , 还有更多意想不到的能力 。
为 GPT-3 这样的大模型专门设计芯片
H100 使用台积电 5nm 定制版本制程(4N)打造 , 单块芯片包含 800 亿晶体管 。 它同时也是全球首款 PCI-E 5 和 HBM 3 显卡 , 一块 H100 的 IO 带宽就是 40 terabyte 每秒 。
「为了形象一点说明这是个什么数字 , 20 块英伟达 H100 带宽就相当于全球的互联网通信 , 」黄仁勋说道 。
黄仁勋列举了 Hopper 架构相对上代安培的五大革新:

文章图片
首先是性能的飞跃式提升 , 这是通过全新张量处理格式 FP8 实现的 。 H100 的 FP8 算力是 4PetaFLOPS , FP16 则为 2PetaFLOPS , TF32 算力为 1PetaFLOPS , FP64 和 FP32 算力为 60TeraFLOPS 。
虽然比苹果 M1 Ultra 的 1140 亿晶体管数量要小一些 , 但 H100 的功率可以高达 700W——上代 A100 还是 400W 。 「在 AI 任务上 , H100 的 FP8 精度算力是 A100 上 FP16 的六倍 。 这是我们历代最大的性能提升 , 」黄仁勋说道 。
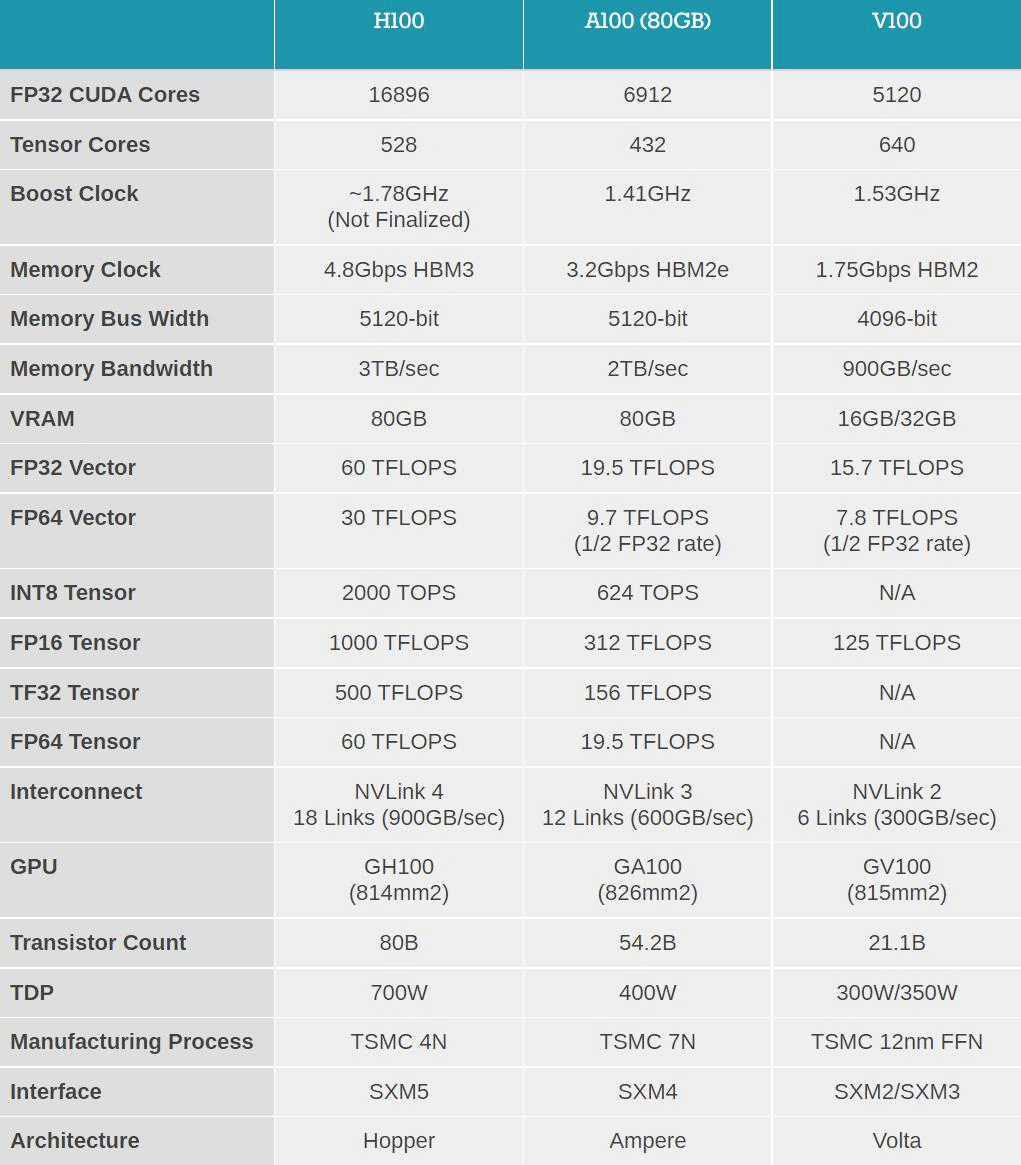
文章图片
图片来源:anandtech
Transformer 类预训练模型是当前 AI 领域里最热门的方向 , 英伟达甚至以此为目标专门优化 H100 的设计 , 提出了 Transformer Engine , 它集合了新的 Tensor Core、FP8 和 FP16 精度计算 , 以及 Transformer 神经网络动态处理能力 , 可以将此类机器学习模型的训练时间从几周缩短到几天 。
Transformer 引擎名副其实 , 是一种新型的、高度专业化的张量核心 。 简而言之 , 新单元的目标是使用可能的最低精度来训练 Transformer 而不损失最终模型性能 。
文章图片
针对服务器实际应用 , H100 也可以虚拟化为 7 个用户共同使用 , 每个用户获得的算力相当于两块全功率的 T4 GPU 。 而且对于商业用户来说更好的是 , H100 实现了业界首个基于 GPU 的机密计算 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。