今天聊聊数据采集 , 数据采集即是数据获取 , 是数据分析的前提 。 那数据采集的方法有哪些?
一、基本方法
数据采集根据采集数据的类型可以分为不同的方式 , 主要方式有:传感器采集、爬虫、录入、导入、接口等 。
传感器监测数据:通过传感器 , 即现在应用比较广的一个词:物联网 。 通过温湿度传感器、气体传感器、视频传感器等外部硬件设备与系统进行通信 , 将传感器监测到的数据传至系统中进行采集使用 。
文章插图
第二种是新闻资讯类互联网数据 , 可以通过编写网络爬虫 , 设置好数据源后进行有目标性地爬取数据 。
第三种通过使用系统录入页面将已有的数据录入至系统中 。
第四种方式是针对已有的批量的结构化数据可以开发导入工具将其导入系统中 。

文章插图
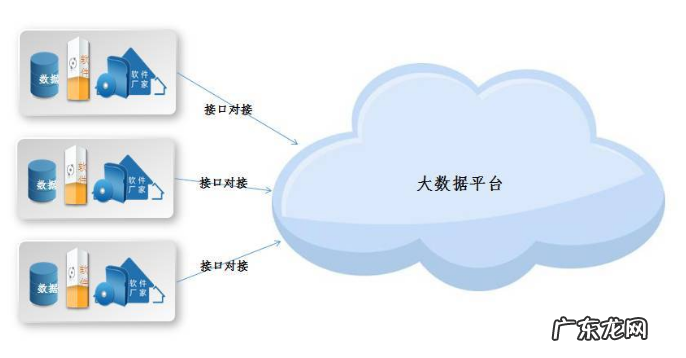
第五种方式 , 可以通过API接口将其他系统中的数据采集到本系统中 。
二、大数据技术的数据采集
(1)离线采集:
工具:ETL;
在数据仓库的语境下 , ETL基本上就是数据采集的代表 , 包括数据的提取(Extract)、转换(Transform)和加载(Load) 。 在转换的过程中 , 需要针对具体的业务场景对数据进行治理 , 例如进行非法数据监测与过滤、格式转换与数据规范化、数据替换、保证数据完整性等 。
(2)实时采集:
工具:Flume/Kafka;
实时采集主要用在考虑流处理的业务场景 , 比如 , 用于记录数据源的执行的各种操作活动 , 比如网络监控的流量管理、金融应用的股票记账和 web 服务器记录的用户访问行为 。 在流处理场景 , 数据采集会成为Kafka的消费者 , 就像一个水坝一般将上游源源不断的数据拦截住 , 然后根据业务场景做对应的处理(例如去重、去噪、中间计算等) , 之后再写入到对应的数据存储中 。 这个过程类似传统的ETL , 但它是流式的处理方式 , 而非定时的批处理Job , 些工具均采用分布式架构 , 能满足每秒数百MB的日志数据采集和传输需求
(3)互联网采集:
工具:Crawler, DPI等;
Scribe是Facebook开发的数据(日志)收集系统 。 又被称为网页蜘蛛 , 网络机器人 , 是一种按照一定的规则 , 自动地抓取万维网信息的程序或者脚本 , 它支持图片、音频、视频等文件或附件的采集 。
除了网络中包含的内容之外 , 对于网络流量的采集可以使用DPI或DFI等带宽管理技术进行处理 。
(4)其他数据采集方法
对于企业生产经营数据上的客户数据 , 财务数据等保密性要求较高的数据 , 可以通过与数据技术服务商合作 , 使用特定系统接口等相关方式采集数据 。 比如八度云计算的数据BDSaaS , 无论是数据采集技术、BI数据分析 , 还是数据的安全性和保密性 , 都做得很好 。
数据的采集是挖掘数据价值的第一步 , 当数据量越来越大时 , 可提取出来的有用数据必然也就更多 。 只要善用数据化处理平台 , 便能够保证数据分析结果的有效性 , 助力企业实现数据驱动 。
三、软件系统的数据采集方法
(1)软件接口方式
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。