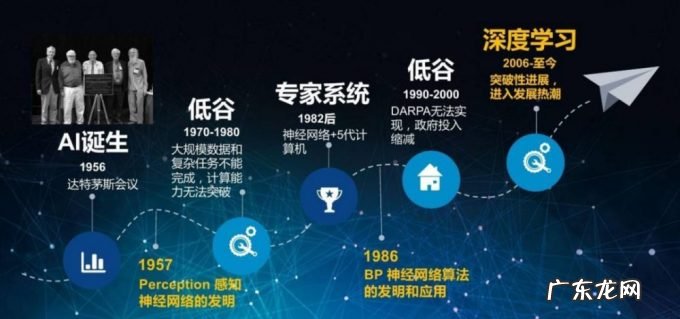
此报告一出 , 相关的研究经费大幅萎缩 。
文章插图
直至80年代后期 , 由于电脑运算效能的提升及电脑成本的降低 , 研究的重心开始放在机器翻译统计模型上 。
至今仍没有一个翻译系统能够达到「全自动优质翻译任何文体」(fully automatic high quality translation of unrestricted text)的境界 。
但在使用场景的严格限制下 , 已经有很多程序能够提供相对准确的翻译了 。
在神经网络在NLP领域大火前 , 机器翻译界的主流方法都是Phrased-Based Machine Translation (PBMT) , Google翻译使用的也是基于这个框架的算法 。
所谓Phrased-based , 即翻译的最小单位由任意连续的词(Word)组合成为的短语(Phrase) 。

文章插图
首先 , 算法会把句子打散成一个个由词语组成的词组(中文需要进行额外的分词);
然后 , 预先训练好的统计模型会对于每个词组 , 找到另一种语言中最佳对应的词组;
最后 , 需要将这样「硬生生」翻译过来的目标语言词组 , 通过重新排序 , 让它看起来尽量通顺以及符合目标语言的语法 。
传统的PBMT的方法 , 一直被称为NLP(Natural Language Processing , 自然语言处理)领域的终极任务之一 。
因为整个翻译过程中 , 需要依次调用其他各种更底层的NLP算法 , 比如中文分词、词性标注、句法结构等等 , 最终才能生成正确的翻译 。 这样像流水线一样的翻译方法 , 一环套一环 , 中间任意一个环节有了错误 , 这样的错误会一直传播下去(error propagation) , 导致最终的结果出错 。
因此 , 即使单个系统准确率可以高达95% , 但是整个翻译流程走下来 , 最终累积的错误可能就不可接受了 。
由于神经网络的大火 , 目前的机器翻译技术大多都采用神经网络机器翻译(Neural Machine Translation, NMT)的方式 。
相比于传统的统计机器翻译(SMT)而言 , NMT能够训练一张能够从一个序列映射到另一个序列的神经网络 , 输出的可以是一个变长的序列 , 这在翻译、对话和文字概括方面能够获得非常好的表现 。
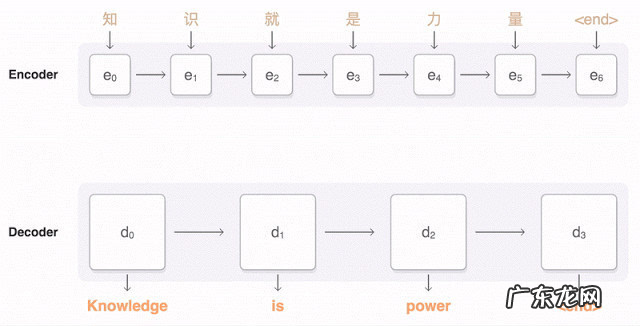
NMT本质上是一个encoder-decoder系统 , encoder把源语言序列进行编码 , 并提取源语言中信息 , 通过decoder再把这种信息转换到另一种语言即目标语言中来 , 从而完成对语言的翻译 。
文章插图
NMT这样的过程直接学习源语言到目标语言 , 省去了训练一大堆复杂NLP子系统的依赖 , 依靠大量的训练数据(平行语料库 , 比如同一本书的中文和英文版本) , 直接让深度神经网络去学习拟合 , 省去了很多人工特征选择和调参的步骤 。
2015年 , Yoshua Bengio团队进一步 , 加入了Attention的概念 。 稍微区别于上面描述的Encoder-Decoder方法 , 基于Attention的Decoder逻辑在从隐层h中读取信息输出的时候 , 会根据现在正在翻译的是哪个词 , 自动调整对隐层的读入权重 。 即翻译每个词的时候 , 会更加有侧重点 , 这样也模拟了传统翻译中词组对词组的对应翻译的过程 。
- 《鱿鱼游戏》火热全球,翻译人才出现巨大缺口
- 华为鸿蒙半年,就走完了苹果、谷歌5年,小米9年的路?
- 花钱给开发者在谷歌上投广告,苹果到底图的啥
- 三十而立四十不惑原文及翻译 三十而立四十不惑
- 翻译几个有关减肥的英语词汇
- 谷歌Pixel 6a将继续使用Tensor SoC,摄像模块会降级
- Coatue买了张元宇宙门票,3亿美金投了“谷歌的小老弟”
- 部署100 个机器人,执行办公室清洁等任务,谷歌母公司离“可以自己学习”的Robot还有多远?
- 大家电销售陷入两难:线下卖不动,线上带不动
- 联想陷入“塔西佗陷阱”
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。