10. 分层强化学习(1990)
文章插图
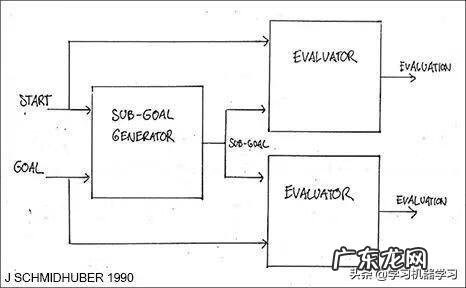
传统的不具有「老师」的强化学习(RL)不能层次化地将问题分解为更容易解决的子问题 。正是我在 1990 年提出分层强化学习(HRL)的原因,HRL 使用基于神经网络的端到端可微分的子目标生成器[HRL0],以及学着生成子目标序列的循环神经网络(RNN)[HRL1][HRL2] 。强化学习系统获得形如(start,goal)的额外输入 。有一个评价器神经网络会学着预测从起始状态到目标状态的奖励/开销 。基于 RNN 的子目标生成器也可以获取(start,goal),并使用评价器神经网络的副本通过梯度下降来学习成本最低的中间子目标序列 。强化学习系统试图使用这样的子目标序列来实现最终目标 。
我们在 1990-1991 年间发表的论文 [HRL0][HRL1] 是后续各种分层强化学习论文(例如,[HRL4])的先驱 。不久之后,其他的研究者们也开始发表 HRL 领域的论文 。例如,本文的参考文献 [ATT2] 的审稿人正是参考文献 [HRL3] 的尾作(相关工作请参见第 9章) 。
11. 通过循环神经世界模型规划并进行强化学习(1990)
文章插图
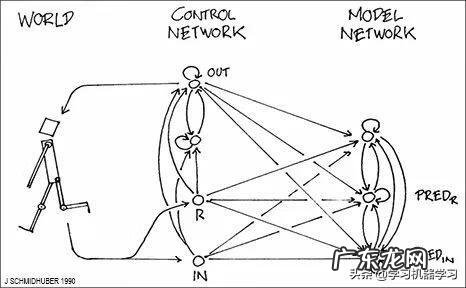
1990 年,我提出了基于两个 RNN 的组合 (控制器 C 和世界模型 M)的强化学习和规划(请参阅第五章) 。M 学着去预测 C 行为的后果 。C 则学着使用 M 提前几个时间步进行规划,从而选择最大化预测累积奖励的动作序列 [AC90] 。近年来,这一思路也催生了许多后续工作(例如,[PLAN2-6]) 。
1990 年的 FKI 科技报告 [AC90] 也提出了一些其它最近变得很热门的概念 。详情请参阅第 5、12、13、14、20 章 。
12. 将目标定义命令作为额外的神经网络输入(1990)

文章插图
在现在的强化学习神经网络中,有一个被广泛使用的概念:用额外的目标定义输入模式来编码各类人物,这样一来神经网络就知道下一步该执行哪个任务 。我们在 1990 年的许多工作中 [ATT0][ATT1][HRL0][HRL1] 提到了这一概念 。在 [ATT0][ATT1] 中,我们使用一个强化学习神经控制器学着通过一系列的「扫视」(Saccade)操作去控制任务的「凹轨迹」(Fovea),从而找到视觉场景下的特定目标,因此可以学习到顺序注意力(详见第 9 章) 。
我们通过特殊的不变的「目标输入向量」将用户定义的目标输入给系统(详见第 3 章第 2 节 [ATT1]),而系统通过「凹轨迹移动」(Fovea-Shifting)来形成其视觉输入流 。
具有端到端可微字目标生成器的分层强化学习(HRL,详见第 10 章)[HRL0][HRL1] 也使用了一个具有形如(start,goal)的任务定义输入的神经网络,学着预测从起始状态到目标状态的成本 。(25 年后,我之前的学生 Tom Schauls 在 DeepMind 提出了「通用值函数近似器」[UVF15]) 。
这一思想催生了许多后续的工作 。例如,我们开发的「POWERPLAY」系统(2011)[PP][PP1] 也使用了任务定义的输入将不同的任务区分开来,不断地提出自己IDE新目标和新任务,以一种主动的、部分无监督的或自监督的方式逐渐学着成为一个越来越通用的问题求解器 。2015 年,使用高维视频输入和内在动机(intrinsic motivation)的强化学习机器人也学着去探索 [PP2] 。
13. 作为神经网络输入/通用值函数的高维奖励信号(1990)
文章插图
传统的强化学习是基于一维奖励信号的 。然而,人类有数百万种作用于不同种类刺激(例如,疼痛和愉悦)的信息传感器 。据我所知,参考文献 [AC90] 是第一篇关于具有多维、向量值的损失和奖励信号的强化学习的论文,这些信号从许多不同的感知渠道传入,我们将预测所有这些传感器接受信号的累计值,而不仅仅是单个标量的整体奖励,这与之后的通用值函数(GVF)相类似 。不同于之前的自适应评价(adaptive critics),我们 1990 年发表的这篇论文 [AC90] 提出的学习机制是多维循环的 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。