文章插图
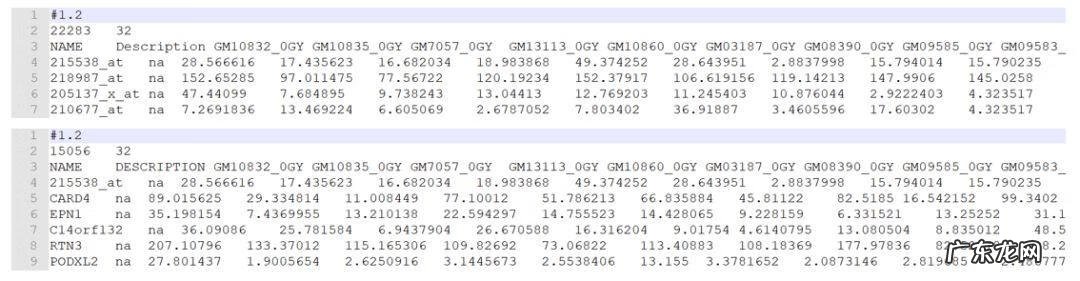
2. 样品分组信息
- 第一行:三个数分别表示:34个样品,2个分组,最后一个数字1是固定的;
- 第二行:以#开始,tab键分割,分组信息(有几个分组便写几个,多个分组在比较分析时,后面需要选择待比较的任意2组);
- (样品分组中NGT表示正常耐糖者,DMT表示糖尿病患者,自己使用时替换为自己的分组名字)
- 第三行:样本对应的组名 。样本分组信息的第三行,同一组内的不同重复一定要命名为相同的名字,可以是分组的名字 。例如相同处理的不同重复在自己试验记录里一般是Treat6h_1、Treat6h_2、Treat6h_3,但是在这里一定都要写成一样的值Treat6h 。与表达矩阵的样品列按位置一一对应,名字相同的代表样品属于同一组 。如果是样本分组信息,上图中的0和1也可以对应的写成NGT和DMT,更直观 。但是,如果想把分组信息作为连续表型值对待,这里就只能提供数字 。
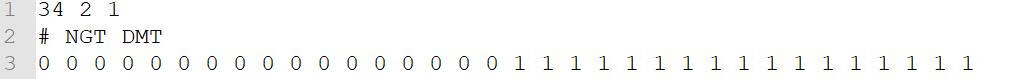
文章插图
3. 功能基因集文件(gene sets)
GSEA官网提供了8种基因分类数据库,都是关于人类的数据,包括Marker基因,位置临近基因,矫正过的基因集,调控motif基因集,GO注释,癌基因,免疫基因,最新一次更新是在2018年7月,下载地址:
http://software.broadinstitute.org/gsea/downloads.jsp#msigdb 。

文章插图
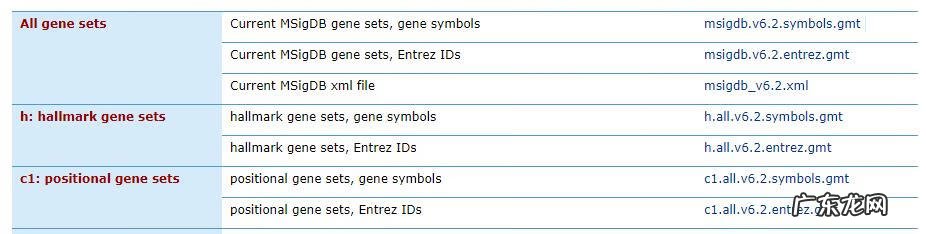
官网提供的gmt文件有两种类型,*.symbols.gmt中基因以symbols号命名,*.entrez.gmt中基因以entrez id命名 。注意根据表达矩阵的基因名字命名方式选择合适的基因集 。表达数据和通路数据能关联在一起依赖的是基因名字相同,所以一定保证基因命名方式的统一 。
文章插图
gmt格式是多列注释文件,第一列是基因所属基因集的名字,可以是通路名字,也可以是自己定义的任何名字 。第二列,官方提供的格式是URL,可以是任意字符串 。后面是基因集内基因的名字,有几个写几列 。列与列之间都是TAB分割 。
Pathway_descriptionAnystringGene1Gene2Gene3Pathway_description2AnystringGene4Gene2Gene3Gene5GSEA官网只提供了人类的数据,但是掌握了官网中基因表达矩阵和注释文件的数据格式,就可以根据自己研究的物种,在公共数据库下载对应物种的注释数据,自己制作格式一致的功能基因集文件,这样便就可以做各种物种的GSEA富集分析了 。4. 芯片注释文件
如果分析的表达数据是芯片探针数据就需要用到芯片注释文件(chip),用来做ID转换,把探针名字转换为基因名字 。如果我们的表达数据文件中已经是基因名了就不再需要这个文件了 。
演示使用的数据来自GSEA官网:
- 表达矩阵:Diabetes_collapsed_symbols.gct
- 样品分组信息:Diabetes.cls
- 基因功能分类数据选择GO数据库:c5.all.v6.2.symbols.gmt
- 因为表达矩阵与注释中基因名字可以直接对应,第四个文件不需要
文章插图
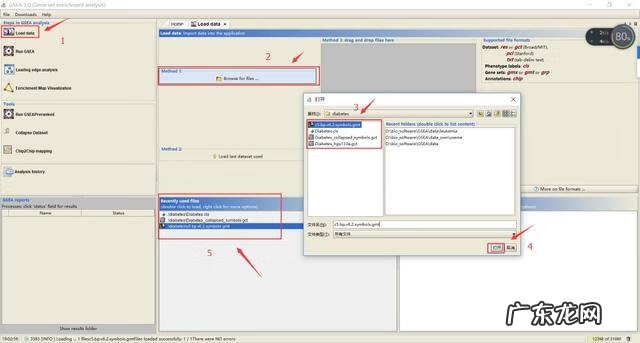
按照上图步骤依次点击Load data——Browse for file——在弹出文件框中找到待导入的文件,选中点击打开即可;
若文件格式没问题会弹出一个提示There were no error的框,证明文件上传成功,并且会显示在5所示的位置;若出错,请仔细核对文件格式 。
- 中国研究生准考证打印 研究生考试准考证打印要求
- 英语四级考试考什么 四级英语总分多少
- 天津会计初级考试 天津会计考试
- 四级考试时间 四级考试报名条件
- 英语口语考试常用对话 英语口语考试对话内容
- 公共英语等级有几级 全国公共英语等级考试
- 会计初级证书报名条件 会计初级职称考试报考条件
- 造价工程师入门手册书籍 造价师考试用书
- 幼儿教师招聘考试试题及答案?
- 广东省公务员考试成绩怎么查询?
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。