注意:1)本地文件存放路径不要有中文、空格(用_代替空格)和其他特殊字符;2)所有用到的文件都需要通过上述方式先上传至软件;3)数据上传错误后可以通过点击工具栏file——clear recent file history进行清除 。
2. 指定参数
点击软件左侧Run GSEA,将跳出参数选择栏 。参数设置分为三个部分Require fields(必须设置的参数项)、Basic fields(基本参数设置栏)和Advanced fields(高级参数设置栏),后面两栏的参数一般不做修改,使用默认的就行 。后面两部分参数设置,如果涉及到需要根据实验数据做调整的地方,会在后面的分析中会提到 。
1)Require fields
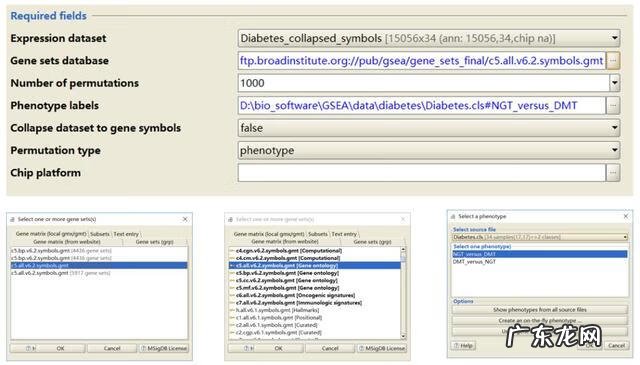
文章插图
- Expression dataset: 导入表达数据集文件,点击后自动显示上一步中从本地导入软件内的文件,所以一定要确认上一步导入数据是否成功;
- Gene sets database: 基因功能集数据库,可以从本地导入(上一步);
- 在联网的情况下软件也可以为自动下载GSEA官网中的gene sets文件;
- Number of permutations: 置换检验的次数,数字越大结果越准确,但是太大会占用太多内存,软件默认检验1000次 。
- 软件分析时会得到一个基因富集的评分(ES),但是富集评分是否具有统计学意义,软件就会采用随机模拟的方法,根据指定参数随机打乱1000次,得到1000个富集评分,然后判断得到的ES是否在这1000个随机产生的得分中有统计学意义 。测试使用时建议填一个很小的数如10,先让程序跑通 。真正分析时再换为1000 。
- Phenotype labels: 选择比较方式,如果文件只有2个组别的话就比较方便了,任意选一个就行,哪个在前在后全在自己怎么解释方便;如果数据有多组的话,GSEA会提供两两间比较的组合选项或者某一组与剩下所有组的比较 。选择好后,GSEA会在分析过程中根据组别信息自动到表达数据集文件中提取对应的数据作比较 。
- Collapse dataset to gene symbols: 如果表达数据集文件中NAME已经与gene sets database中名字一致,选择FALSE,反之选择TRUE 。
- Permutation type: 选择置换类型,phenotype或者gene sets 。
- 每组样本数目大于7个时 ,建议选择phenotype,否则选择gene sets 。
- Chip platform: 表达数据集为芯片数据时才需要,目的是对ID进行注释转换,如果已经转换好了就不需要了 。应该也适用于其它需要转换ID的情况,不过事先转换最方便 。

文章插图
通常选择默认参数即可,在此简单介绍一下
- Analysis name: 取名需要注意不能有空格,需要用_代替空格 。如果做的分析多,最好选择一个有意义的名字,比如shengxinbaodian (生信宝典全拼),方便查找 。
- Enrichment statistic: 基因集富集分析(PNAS)的最后一部分给出了GSEA中所用方法的数学描述,感兴趣的可以查看一下论文 。在此给出每种富集分析不同算法的参数情况:? classic: p=0 若基因存在,则ES值加1;若基因不存在,则ES值减1 ? weighted (default): p=1 若基因存在,则ES加rank值;若基因不存在,则ES减rank值 ? weighted_p2: p=2 基因存在,ES加rank值的平方,不存在则减rank值的平方 ? weighted_p1.5: p=1.5 基因存在,ES加rank值得1.5次方,不存在则减rank值得1.5次方
- 中国研究生准考证打印 研究生考试准考证打印要求
- 英语四级考试考什么 四级英语总分多少
- 天津会计初级考试 天津会计考试
- 四级考试时间 四级考试报名条件
- 英语口语考试常用对话 英语口语考试对话内容
- 公共英语等级有几级 全国公共英语等级考试
- 会计初级证书报名条件 会计初级职称考试报考条件
- 造价工程师入门手册书籍 造价师考试用书
- 幼儿教师招聘考试试题及答案?
- 广东省公务员考试成绩怎么查询?
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。