文章图片
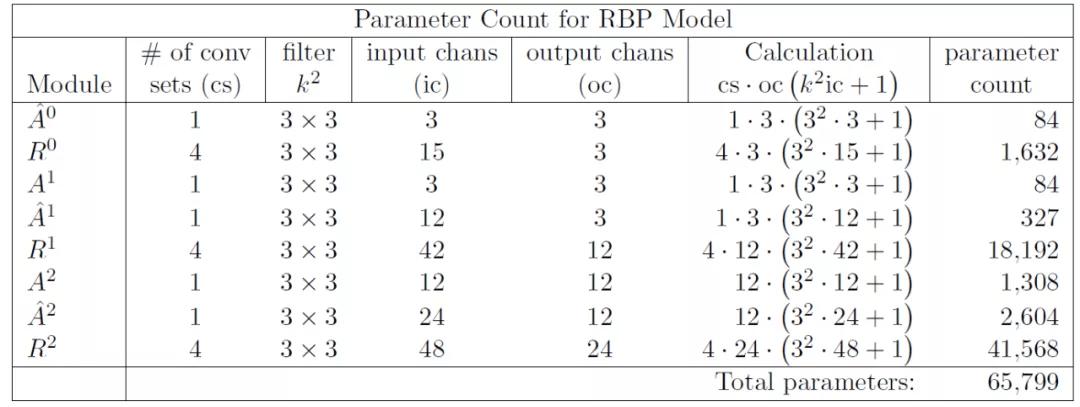
图 7. 改进的 RBP 模型架构
文章图片
表 1. 图 7 所示模型的参数计算量 。 如果 R^l 模型中的 LSTM 被 GRU 替换 , 则参数计数为 50451 , 而不是 65799 。 这是通过将每个 R^l 模块中的卷积集的数量从四个更改为三个来实现的
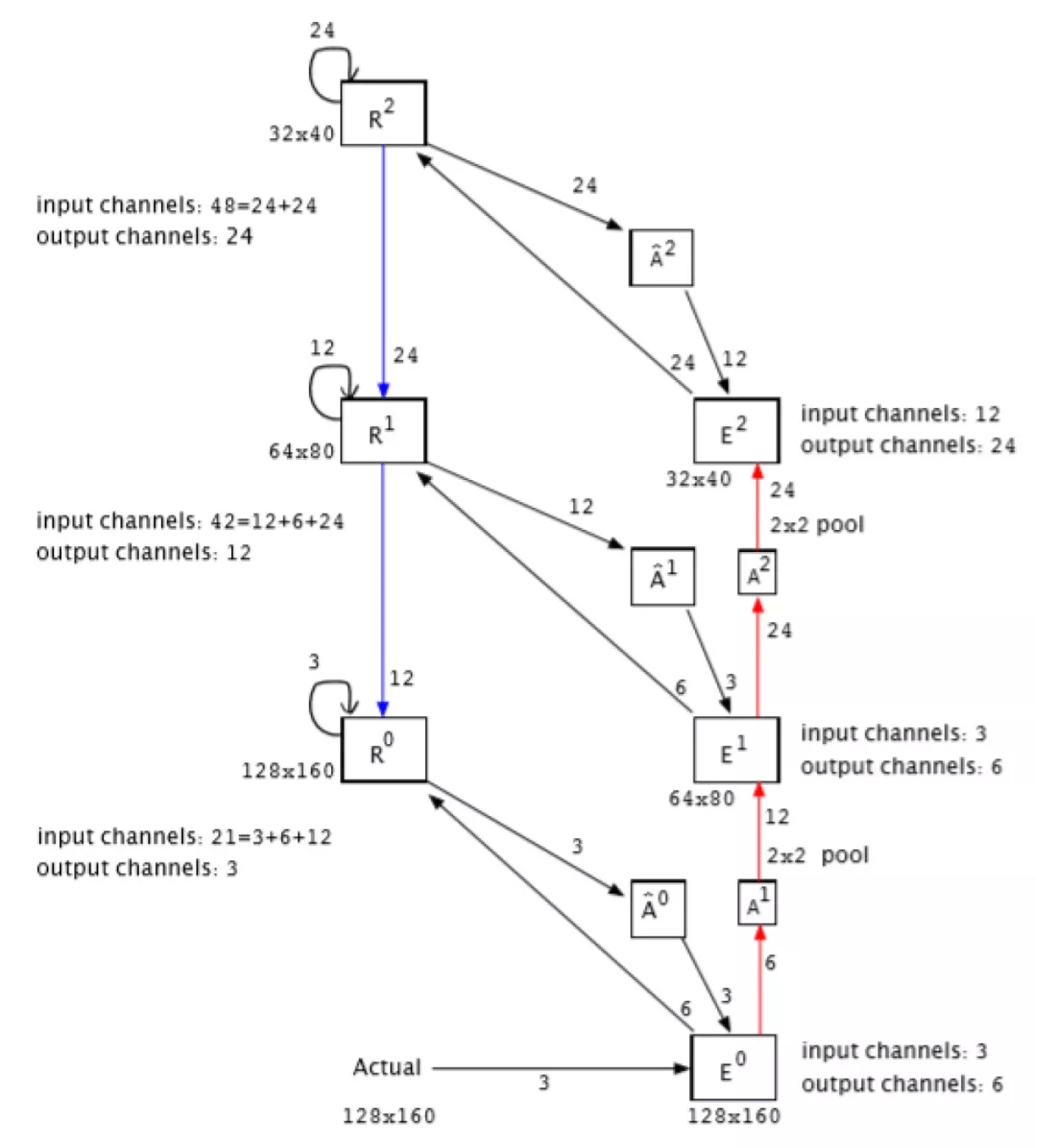
接下来 , 作者将图 7 中的 RBP 模型与原始 PredNet 3 层模型进行比较 。 两个模型都使用相同的 11 个模块 。 两种模式都被限制在 R^l 模块中使用相同的输出通道 。 为了将这些模块组合在一起 , 要求 Rl^ 模块的输入通道数不同 , E^1 和 E^2 模块以及连接它们的 A^l 和(A^l)^ 模块的通道数也不同 。 由于输入通道的数量不同 , 图 8 模型有 103,020 个参数(参见表 2) , 而不是 65,799 。 图 7 和图 8 中连接模块的箭头表示信息流的方向 。 箭头上的数字标签表示该路径的通道数 。 每个模型的 R^l 模块中的输出通道数量是匹配的 。
文章图片
图 8. 扩充后的三层 PredNet 模型 , 其中 , 蓝色路线在 RBP 模型中不存在 , 但在扩充后的模型中使用 , 红色通路在 RBP 和混合模型中都是缺失的 , 这是原始 PredNet 模型特有的 。 箭头附近的标签是通道数 。 这种结构由表 3 中给出的 Pred1 和 Pred2 模型实现

文章图片
表 2. 图 8 中涉及的参数计算量
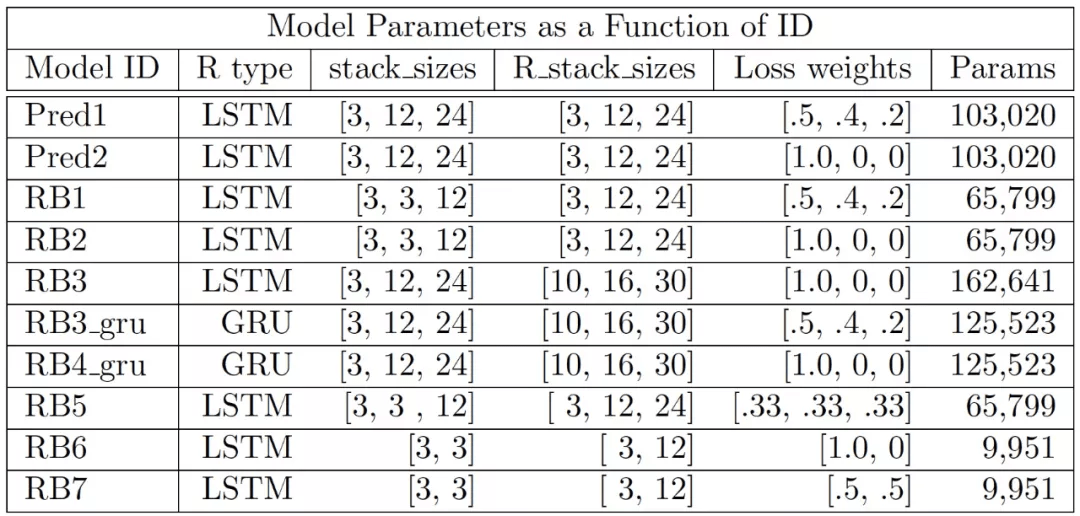
所有的模型都在预处理的 KITTI 交通数据集上使用 Adam 优化器训练了 20 个 epochs 。 该数据集经过预处理 , 以获得尺寸为 120 x 160 像素的三通道彩色图像 。 完成这个数据集上的预测任务需要模型检测和跟踪视频帧中的几个移动和非移动物体 。 作者通过实验测试了三种架构 。 第一个是 RBP 架构 , 其中 R^l 模块是由 cLSTMs 构建的 。 第二个也是 RBP 架构 , 其中 R^l 模块由卷积 GRU 构建 。 第三种是使用原始 PredNet 架构进行测试 。 如表 3 所示具体的模型体系结构规范 。
文章图片
表 3. 根据模型 ID 索引的模型体系结构规范 。 其中 , "stack sizes" 是误差模块的输入通道数 , "R stack sizes" 是表示模块的输出通道的数量 , "Params" 是模型中可训练参数的数量
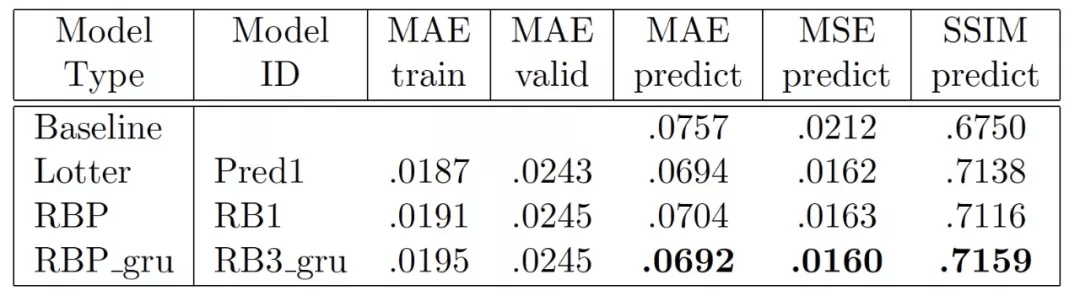
作者具体完成了两个实验 。 第一个实验使用的损失函数权重值为 [.5, .4, .2] 。 第二个实验使用的损失函数权重值为[1, 0, 0] 。 在所有的实验中 , 作者记录了三个性能指标:平均绝对误差(MAE)、平均平方误差(MSE)和结构相似度指数(SSIM) 。 所有指标都是在文献[3] 给出的基线控制条件下计算的 , 以便与神经网络性能指标进行比较 。 基线使用当前的视频帧作为下一帧的预测值 。 表 4 和表 5 分别给出两个实验的结果 。 作者将预测误差分数应与基线分数相比较 。 在训练阶段 , RBP 模型对训练数据的平均绝对误差(MAE)为 .0191 , 对验证误差的平均绝对误差为 .0245 。 在测试阶段 , MSE 下一帧的预测精度为 .0163 , 而使用前一帧作为预测的基线预测精度为 .0212 。 这些结果与 PredNet 模型非常接近 。 SSIM 的结果与 MAE 非常类似 。 这些结果表明 , 尽管这两个模型的通信结构不同 , 但实际上是等效的 。 第二个实验给出的结果与实验一有所不同 。 两个模型的预测性能都有所提高 。 就 Lotter 等人提出的 PredNet 模型而言 , 这是预料之中的 , 因为该结果已在原始论文中报告 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。