机器之心专栏
清华大学
清华提出的高效学习框架 TLM 也学会了「抱佛脚」 。近期 , 来自清华大学的研究者们提出了一种简单高效的 NLP 学习框架 。 不同于当下 NLP 社区主流的大规模预训练 + 下游任务微调(pretraining-finetuning)的范式 , 这一框架无需进行大规模预训练 。 相较于传统的预训练语言模型 , 该框架将训练效率 (Training FLOPs) 提升了两个数量级 , 并且在多个 NLP 任务上实现了比肩甚至超出预训练模型的性能 。 这一研究结果对大规模预训练语言模型的必要性提出了质疑:大规模预训练对下游任务的贡献究竟有多大?我们真的需要大规模预训练来达到最好的效果吗?

文章图片
- 论文地址:https://arxiv.org/pdf/2111.04130.pdf
- 项目地址:https://github.com/yaoxingcheng/TLM
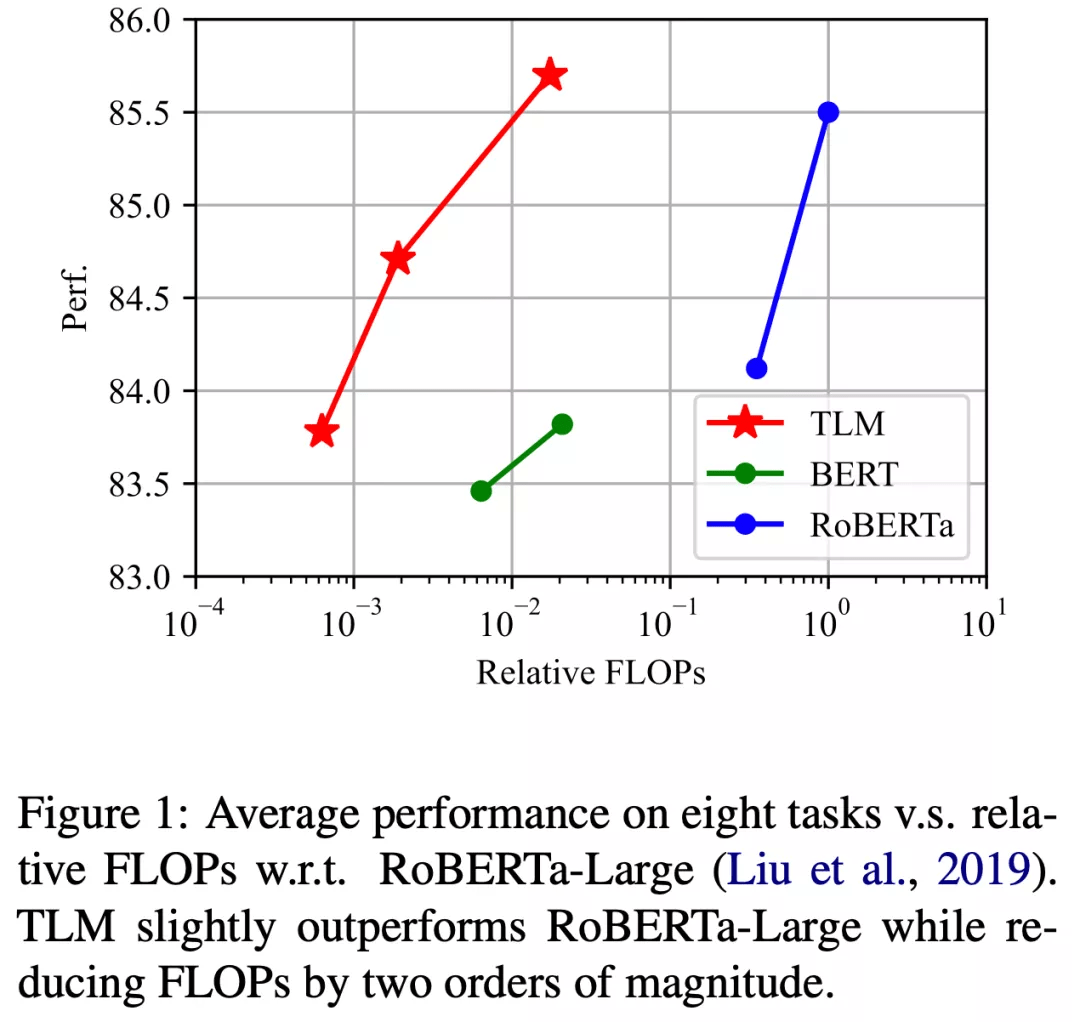
近期 , 为了缓解这一现状 , 来自清华大学的研究者们提出的一种完全不需要预训练语言模型的高效学习框架 。 这一框架从通用语料中筛选出与下游任务相关的子集 , 并将语言建模任务与下游任务进行联合训练 。 研究者们称之为 TLM (Task-driven Language Modeling) 。 相较于传统的预训练模型(例如 RoBERTa) , TLM 仅需要约 1% 的训练时间与 1% 的语料 , 即可在众多 NLP 任务上比肩甚至超出预训练模型的性能(如图 1 所示) 。 研究者们希望 TLM 的提出能够引发更多对现有预训练微调范式的思考 , 并推动 NLP 民主化的进程 。
文章图片
语言模型会「抱佛脚」吗? 任务驱动的语言建模
文章图片
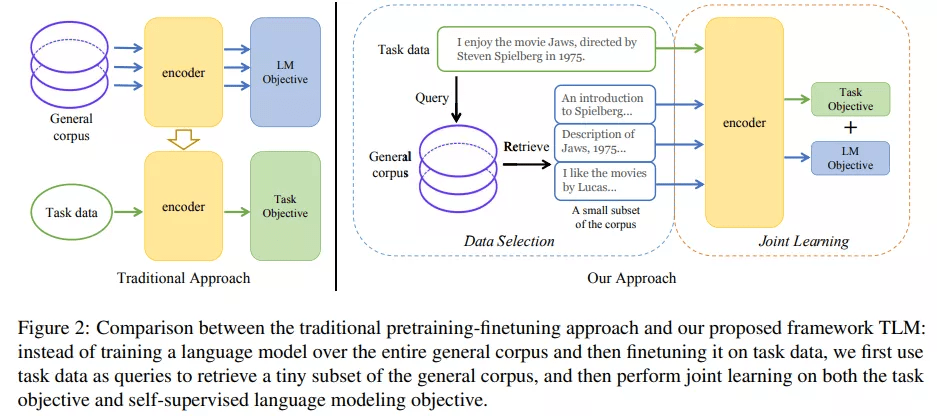
TLM 提出的动机源于一个简单的观察:人类可以通过仅对关键信息的学习 , 以有限的时间和精力快速掌握某一任务技能 。 例如 , 在临考抱佛脚时 , 焦虑的学生仅需要根据考纲复习浏览若干相关章节即可应对考试 , 而不必学习所有可能的知识点 。 类似地 , 我们也可以推测:预训练语言模型在下游任务上的优良表现 , 绝大多数来源于语料中与下游任务相关的数据;仅利用下游任务相关数据 , 我们便可以取得与全量数据类似的结果 。
为了从大规模通用语料中抽取关键数据 , TLM 首先以任务数据作为查询 , 对通用语料库进行相似数据的召回 。 这里作者选用基于稀疏特征的 BM25 算法[2] 作为召回算法 。 之后 , TLM 基于任务数据和召回数据 , 同时优化任务目标和语言建模目标 (如下图公式所示) , 从零开始进行联合训练 。
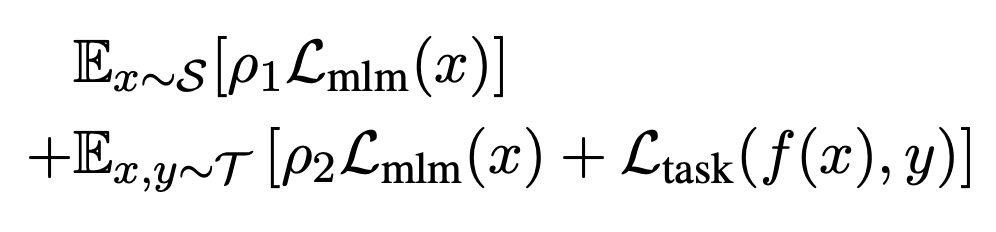
文章图片
1% 的算力 + 1% 的语料即可比肩预训练语言模型
为了测试 TLM 的性能 , 研究者们在 8 个 NLP 分类任务上从三个不同规模展开了对比实验 。 这 8 个任务涵盖了计算机科学、生物医药、新闻、评论等 4 个领域 , 包括了训练样本数量小于 5000 的低资源任务(Hyperpartisan News, ACL-ARC, SciERC, Chemprot)和训练样本数量大于 20000 的高资源任务(IMDB, AGNews, Helpfulness, RCT) , 覆盖了话题分类 , 情感分类 , 实体关系抽取等任务类型 。 从实验结果可以看出 , 和对应预训练 - 微调基准相比 , TLM 实现了相当甚至更优的性能 。 平均而言 , TLM 减少了两个数量级规模的训练计算量 (Training FLOPs) 以及训练语料的规模 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。