文章图片
样本 target:人体姿态目标(蓝色)、关键点目标(红色)、无目标(绿色) , 「?」值不用于损失计算 。
下图展示了在 TITAN Xp GPU 上实时运行 KAPAO-S 进行视频推理的效果:

文章图片
KAPAO-S 在 TITAN Xp GPU 上可以实时运行 , 比本地每秒 25 帧的帧率还要快 , 不过图中未显示面部关键点 。
实验结果
该研究用实验表明了 KAPAO 比之前的方法明显更快、更准确 , 热图后处理对之前的方法影响很大 。 此外 , 在不使用测试时增强(test-time augmentation , TTA)的实际设置中 , KAPAO 在准确率 - 速度方面明显更优秀 。 大型模型 KAPAO-L 在没有 TTA 的情况下在 Microsoft COCO Keypoints 验证集上实现了 70.6 AP , 并且比准确率低 4.0 AP 的单阶段模型还快了 2.5 倍 。
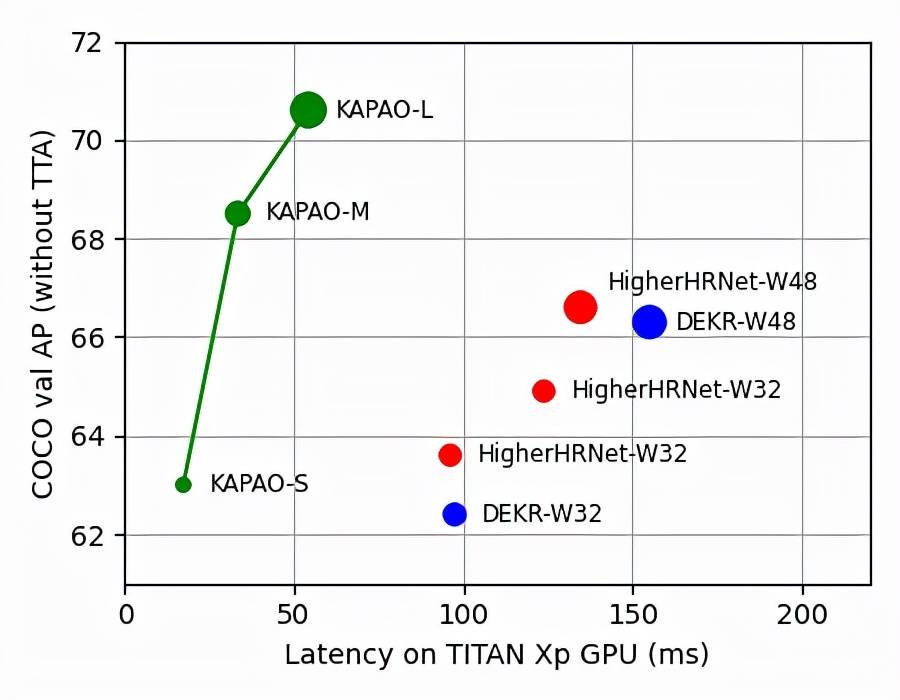
文章图片
图 1:在没有 TTA 的情况下 , KAPAO 与单阶段多人人体姿态估计 SOTA 方法 DEKR、 HigherHRNet 的准确率 - 速度比较结果 。
该研究在 COCO test-dev 上比较了 KAPAO 与单阶段和两阶段方法的准确性 , 结果如下表所示 。
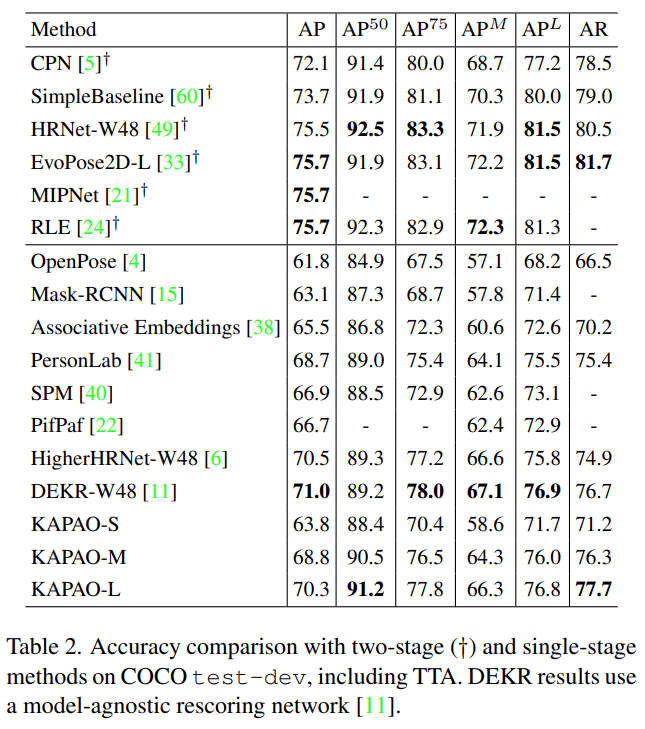
文章图片
为了探究 KAPAO 在拥挤场景中的性能 , 该研究在 CrowdPose 测试集上对几种模型进行了比较 , 结果表明 KAPAO 在存在遮挡的情况下同样表现出色 , 在所有指标上超过了所有此前的单阶段方法 。 在分析 APE、APM 和 APH 时 , KAPAO 对拥挤场景的优势是显而易见的 。
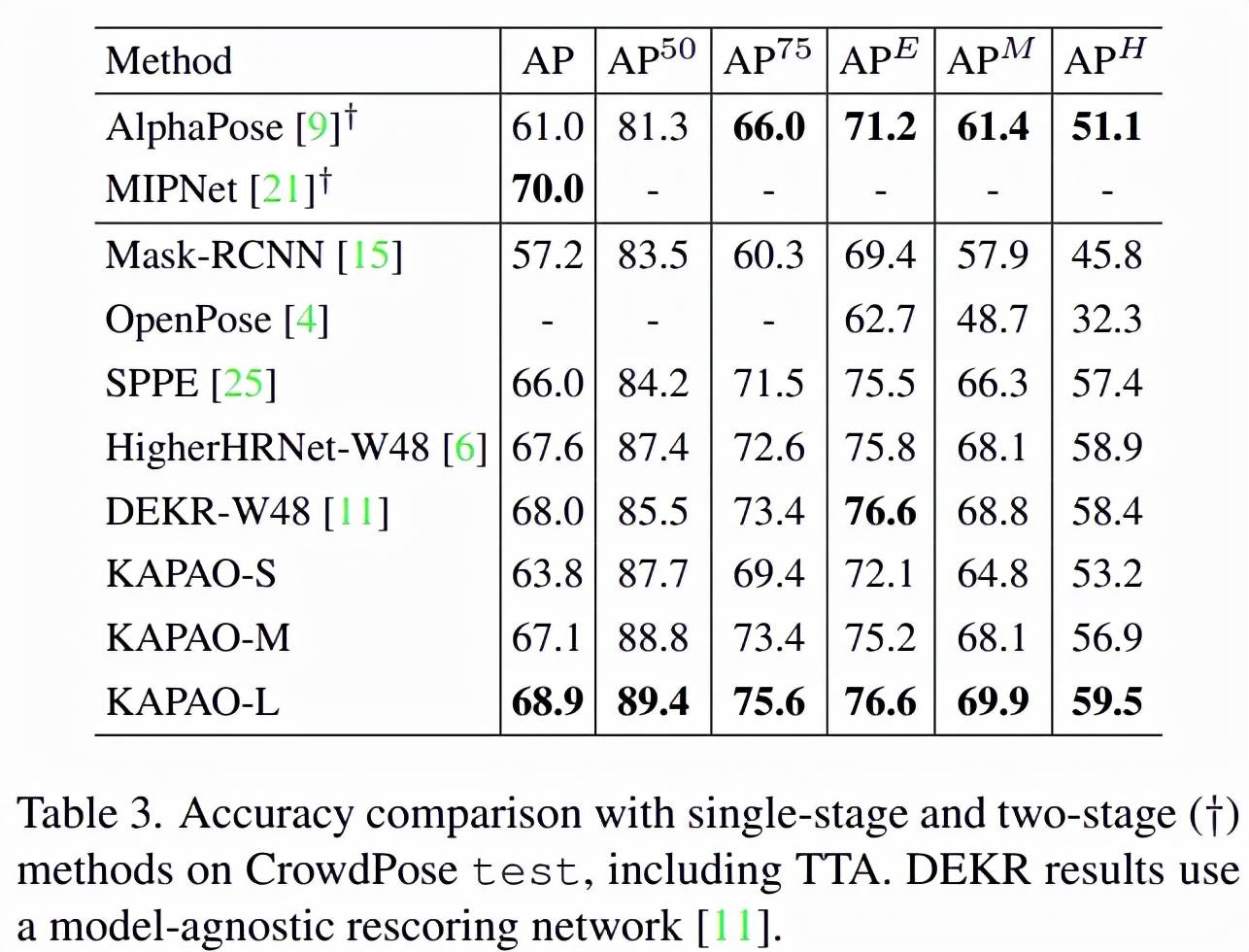
文章图片
具体而言 , KAPAO融合关键点目标和姿态目标所带来的准确率改进如下表4所示:
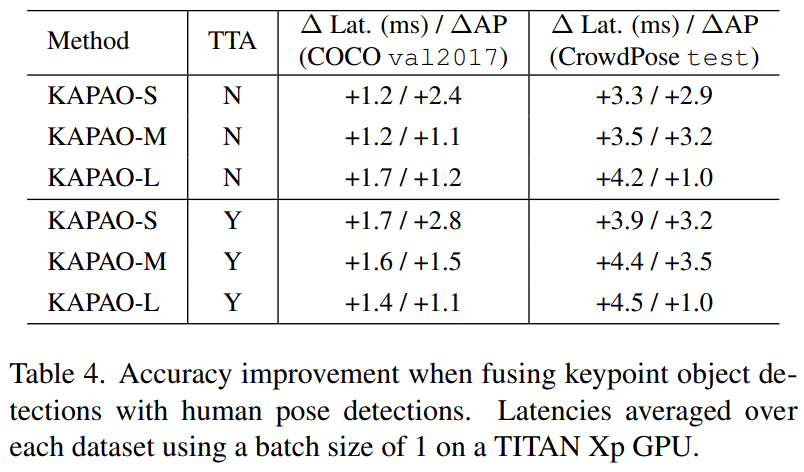
文章图片
为了显示在没有 TTA 的情况下KAPAO的优势 , 图 6 绘制了在 COCO val2017 上 , KAPAO-S 对每个关键点类型的融合率:
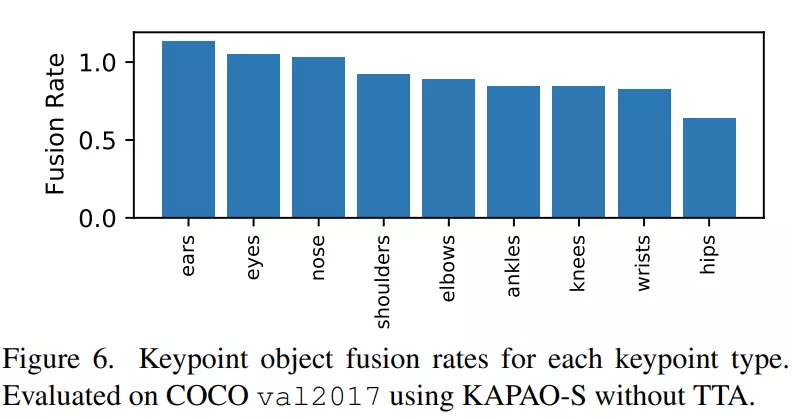
文章图片
感兴趣的读者可以阅读论文原文了解更多细节 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。