同样在2015年 , 在CVPR (计算机视觉顶会)上深度学习巨头Yan LeCun 等人召集了一场深度视觉研讨会 (DeepVision Workshop),邀请Yoshua Bengio等就“视觉的未来”各抒己见 。

文章图片
会上 , 何晓冬在报告中提出了一个观点 , 便是语言-视觉深度多模态语义模型 (DMSM) , 也就是AI在描述一张图的时候 , 是否能够在语义层面上达到一个等价的匹配 。
换句话说 , 就是我们常说的“看图说话” , 文字描述出来的话和图片的内容在语义上要是一致的 。
而何晓冬他们提出的DMSM模型就是一个具体实现的算法 , 能够把图像和文字都表示成为同一个跨模态语义空间内的向量 。
而后在这个空间中进行跨模态语义匹配计算 , 从而帮助生成最匹配图像内容的文字表述 。

文章图片
△何晓冬等在CVPR2015发表的关于视觉和语言多模态图像描述的论文
而且不仅只是语言、图像 , 何晓冬和他的同事后来又将知识融入到了多模态模型中 。
这样做的效果 , 便是AI在“看”到有具体人物、地标的图片时 , 就不仅仅会将其描述为“一个运动员”这样的笼统的信息 。
而是会把描述的语言变得更加细致 , 例如AI就会把图片中的具体人物“纳德拉”都说出来 。
2016年 , 微软CEO纳德拉在微软Build大会中便展示了这项技术 。
文章图片
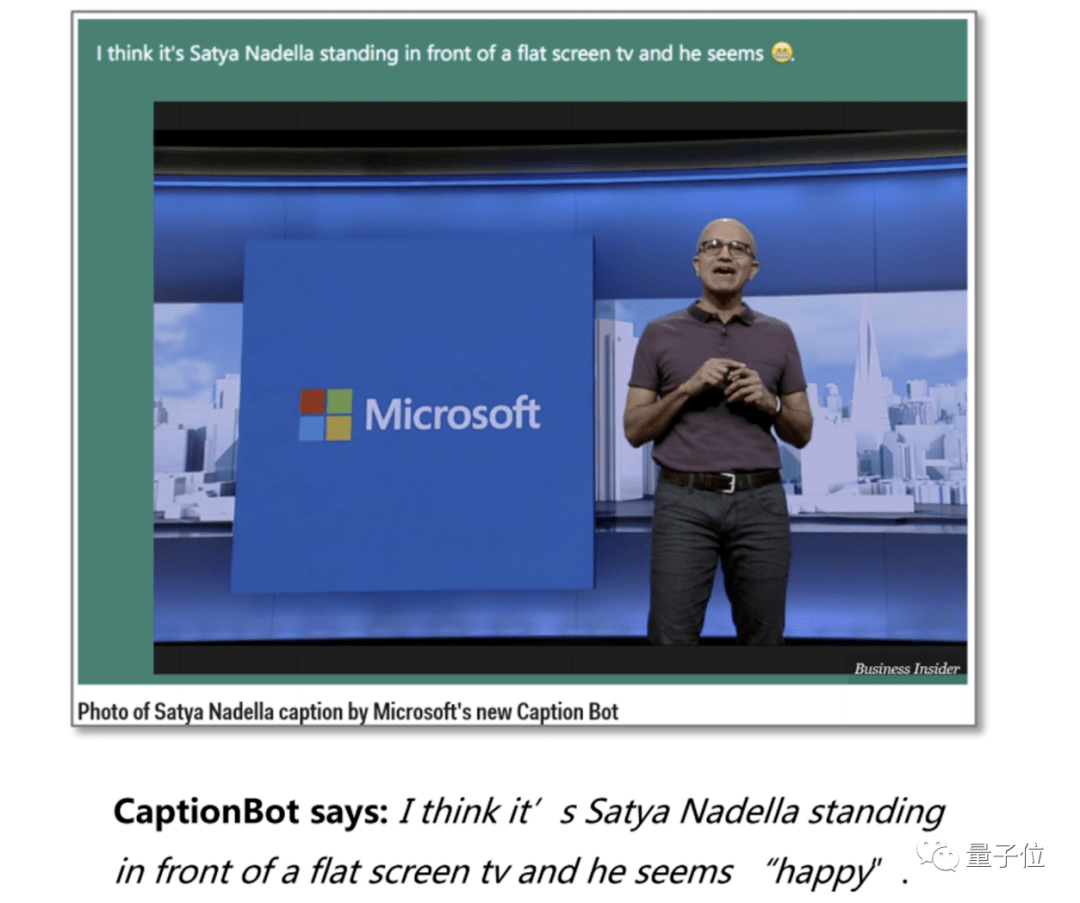
△Business Insider媒体报道CaptionBot
何晓冬带领团队开发的这款名为CaptionBot的AI 应用 , 精准描述了图片中纳德拉的言行举止 , 还能够描述人物情绪 。
一时间 , 跨语言、视觉以及知识的多模态技术迅速实用化 , 该应用也迅速走进了大众的视野当中 。
深度学习崛起和发展过程中有种种“巧合” , 但其实更有赖于很多技术人对技术执著的 “信念” 。 何晓冬自嘲说 , 感觉他就像电影《阿甘正传》里的阿甘一样 , 很幸运的见证了这一轮AI复兴浪潮的关键节点 , 还有幸能在其中做了一点贡献 , 也像是经历了一个技术人的“奇幻之旅 。 ”
回国 , 加盟京东
时间拨转到2018年 , 彼时在微软雷蒙德研究院已经工作十余载的何晓冬 , 选择回到国内 , 并加盟京东 。
这一决定在外界看来或许有些突然 , 但于其本人而言 , 或许更是一种必然 。
就像第一台通用计算机刚刚被发明出来时一样 , 最大的问题是如何让它去做我们想让它做的事 , 发挥出它的潜力和价值 。
作为深度学习新一轮浪潮的亲历者与参与者 , 何晓冬深感应用之于AI的意义 。
而在和人类沟通的过程中 , AI不仅要听懂人类说的话或者看懂人类输入的文字 , 还要理解人的深层意图去组织语言 , 甚至还是一系列的博弈与决策 (比如该做什么、该怎么回复、该询问补充信息还是立刻回答、该采取什么交互策略等等)……这一切使得实用场景成了最好的训练场 。
文章图片
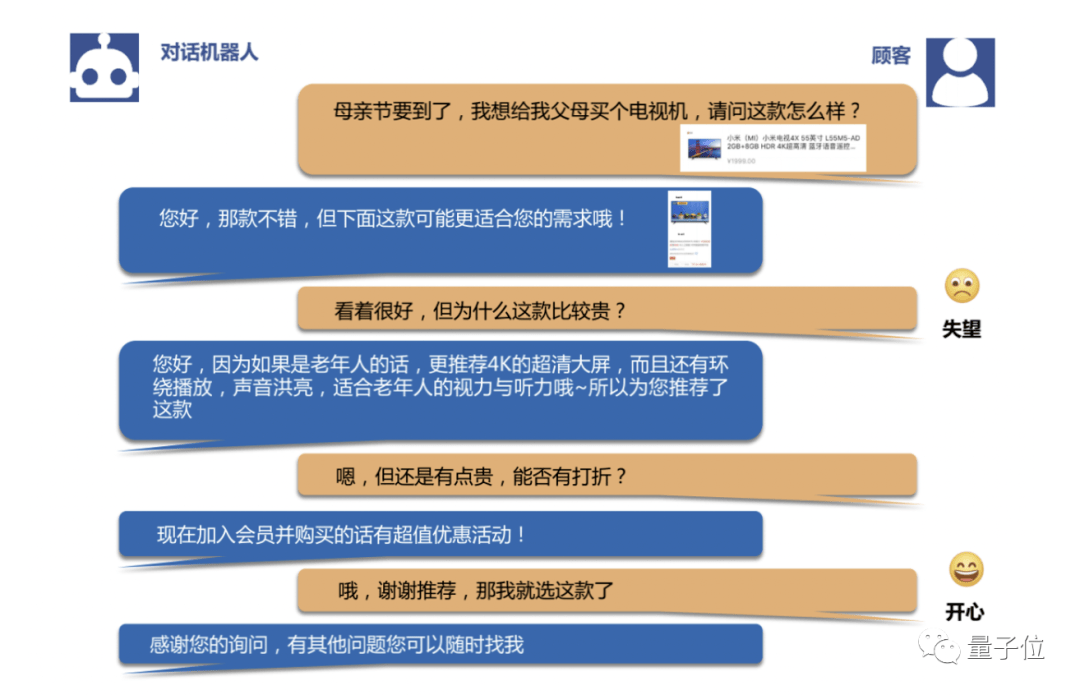
△售前咨询对话的一个案例
何晓冬针对AI的进展做了一个判断 , 当下AI技术的三要素已经从 (静态的)数据、 (单一任务的)算法、算力转化为 (交互行为的)场景、 (多任务协同的)系统和算力新三要素 。
根据复杂的应用中发现的问题反过来推动基础技术的发展 , 也成为如今AI发展的一种新趋势 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。