这里 , 我们不妨借助几个典型的实例 , 来看看亚马逊云科技的产品或者服务在产业发展的节点是否具备变革或者重塑的能力?
2012年发布业界首个云上数据仓库Amazon Redshift , 实现并发扩展的过程中持续稳定的查询性能 , 且按用量付费 , 数据仓库不再只是超大型企业的专利 , 同时为后续云原生产业的快速发展奠定了基础 。
需要说明的是 , 在此之前 , 数据仓库是一项重资产的技术 , 只有大企业才负担得起 , 而且效果很不理想 。 Amazon Redshift直接在云上部署 , 规避了软件在本地安装时要考虑的兼容存储、计算能力以及最小安装等问题 。 云计算与生俱来的弹性优势 , 让Amazon Redshift带给客户低成本起步、简化运维和接近无限的扩展能力 , 实现并发扩展的过程中持续稳定的查询性能 , 且按用量付费 。 Amazon Redshift一经推出迅速成为亚马逊云科技有史以来发展最快的服务 , 这个记录一直保持到后来亚马逊云科技推出云原生关系数据库Amazon Aurora 。
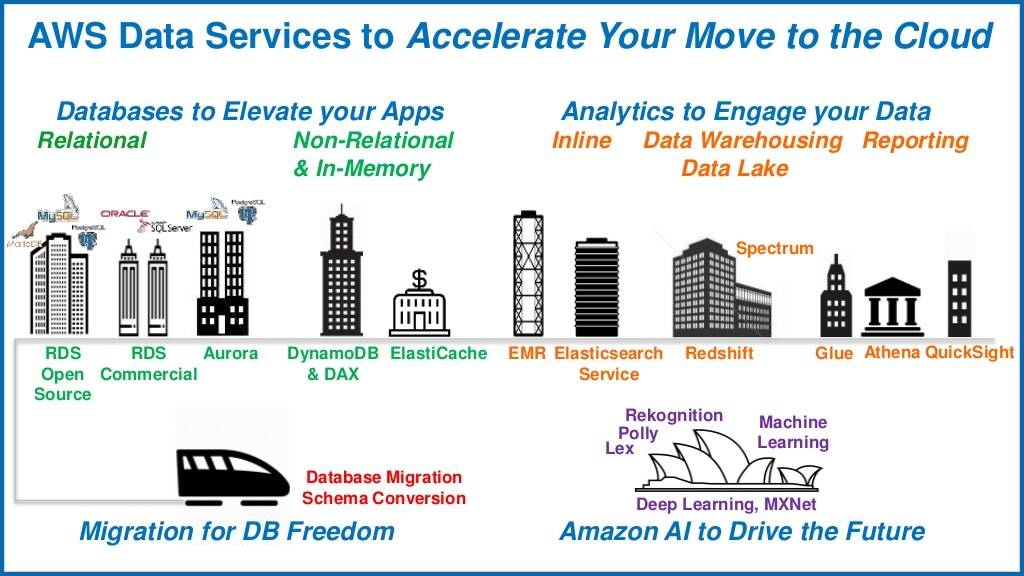
目前 , 亚马逊云科技通过re:Invent陆续发布并对外提供了十余种专门构建的数据库服务 , 支持关系、键值、文档、内存、图、时间序列、宽列和分类账八大数据类型 。
文章图片
对此 , 亚马逊云科技大中华区产品部总经理顾凡表示:“一个传统关系型数据库打天下的时代已经过去了 。 像视频、社交、出行等行业 , 他们的应用所要应付的数据级别是 PB/EB , 并发的请求甚至要服务全世界数亿人 , 还要保持极低的延迟 , 不是传统数据库能搞定的 。 所以我们需要能支撑现代化应用的数据库 , 以及针对存储数据的类型 , 数据访问的特点去选择云上专门构建的数据库 , 专库专用才能带来极致性能 。 ”
2017年 , 针对人工智能的兴起(注:这一年 , AlphaGO击败人类围棋棋手李世石引发科技圈热议的同时 , 标志着机器学习工程化时代的悄然到来) , 发布首个机器学习集成开发环境Amazon SageMaker , 破除软硬件环境限制及资金门槛 , 释放数据科学家的生产力 。

文章图片
以往 , 开展机器学习需要搭建硬件环境并适配其兼容性、配置机器学习框架、分别部署多种工具 , 用于准备数据、训练模型、测试模型、部署模型等 , 繁琐的流程给数据科学家带来很高的上手门槛 。 Amazon SageMaker以全托管的方式 , 消除了基础设施管理的繁琐工作 , 并且将各种工具部署在一个平台上 , 让数据科学家不需要花时间构建机器学习的基础架构 , 直接利用开箱即用的集成环境 , 专注于机器学习本身 。
而在今年的re:Invent 全球大会 , 亚马逊云科技又发布了Amazon SageMaker Canvas 服务 , 即使没有任何机器学习经验 , 也无需编写任何代码 , 开发者也可以更方便的创建机器学习模型 , 从而极大降低了机器学习的门槛 。 通过 Amazon SageMaker Canvas 服务 , 更多的用户可以比以往任何时候都更为方便的最大限度地利用机器学习技术 , 无论他们的经验水平如何 。
值得一提的是 , 同年 , 亚马逊云科技还发布Amazon Nitro系统 , 重构云计算的基础 。
众所周知 , 传统云计算都是基于软件虚拟化的计算 , 服务器既要运行提供给客户的虚拟机 , 也要运行网络、存储、安全、监控等各项功能 , 服务器管理虚拟机大约要占去30%的服务器性能开销 , 导致服务器只有约七成的资源能够提供给用户 。 Amazon Nitro架构在业界首次使用专用芯片 , 采用板卡+专用软件的方式 , 把服务器性能完全通过全新虚拟化技术解放出来 , 消除服务器虚拟化性能损耗 , 用户可获取全部物理服务器资源 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。