下一步是什么?鉴于数据集(统一格式)的可用性和开源性 , 我们可以想象一个良性循环 , 新创建的高质量数据集可用于不同的任务 , 以训练更强大的模型 , 然后这些模型可以在循环中被用来创建更具挑战性的数据集 。
Transformer 架构替代方案
文章图片
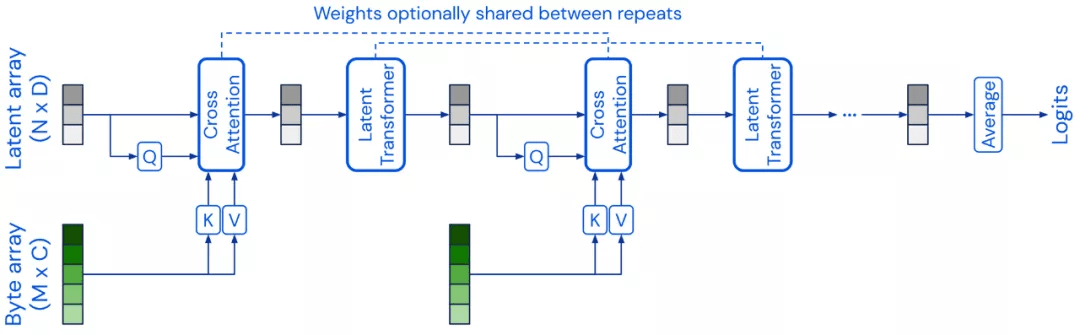
前几节中讨论的大多数预训练模型都是基于 Transformer 架构的 。 2021 年出现了替代的模型架构 , 这些架构是 transformer 的可行替代方案 。 Perceiver 是一种类似 transformer 的架构 , 它通过使用固定维度的潜在数组作为其基本表示并通过交叉注意力在输入上进行调节 , 从而可以扩展到非常高维的输入 。 Perceiver IO 通过扩展架构 , 可以处理结构化的输出空间 。 还有一些模型试图替换自注意力层 , 最著名的是使用多层感知器 (MLPs) , 如 MLP-Mixer 和 gMLP 。 FNet 使用 1D Fourier Transforms 而不是 self-attention 在 token 级别混合信息 。 一般来说 , 将架构与预训练策略解耦是很有用的 。 如果 CNN 以与 Transformer 模型相同的方式进行预训练 , 它们将在许多 NLP 任务上实现具有竞争力的性能 。 同样 , 使用可替代的预训练目标(例如 ELECTRA-style 的预训练)可能会带来更多收益 。
为什么替代 Transformer 架构很重要?如果大多数研究都集中在单一架构上 , 这将不可避免地导致偏见、盲点等一系列错误 。 新模型可能会解决一些 Transformer 的限制 , 例如注意力的计算复杂性、黑盒性质等 。
下一步是什么?虽然预训练 transformer 会被继续部署 , 作为许多任务的标准基线 , 我们应该期待看到可替代的架构被提出 。
提示(Prompting)
文章图片
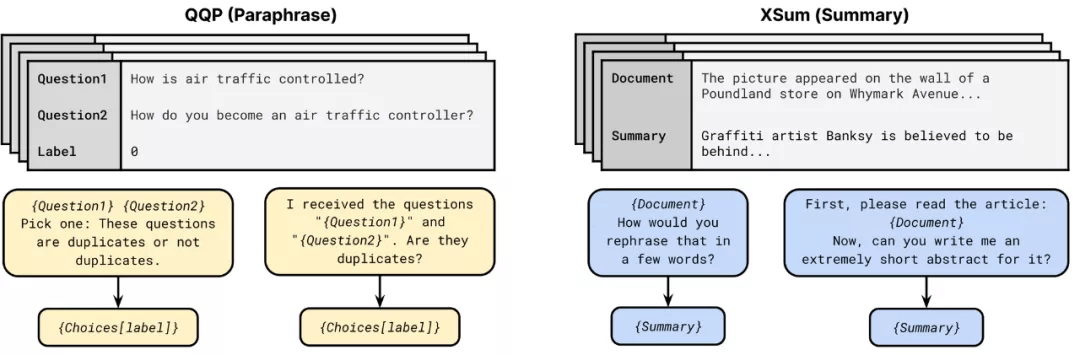
由于 GPT-3 的普及 , 使得提示( prompting)已成为 NLP 模型中一种可行的替代输入格式 。 提示包括模式(即要求模型进行特定预测)和将预测转换为类标签的语言器(verbalizer) 。 PET、iPET 和 AdaPET 等几种方法利用提示进行小样本学习 , 然而 , 提示并不是万能的 。 模型的性能因提示而异 , 找到最佳提示仍然需要标记示例 。 为了在少量设置中比较模型的可靠性 , 我们需要不断的开发新的评估程序 。
为什么提示很重要?提示可用于对特定任务信息进行编码 , 根据任务的不同 , 这些信息可能高达 3,500 个标记示例 。 因此 , 提示是一种将专家信息纳入模型训练的新方法 , 而不是手动标记示例或定义标记函数 。
下一步是什么?目前 , 我们只是触及了使用提示来改进模型学习 。 在以后的研究中 , 提示将变得更加复杂 , 例如包括更长的指令、正例和负例、一般启发式 。 提示也可能是将自然语言解释纳入模型训练的一种更自然的方式 。
高效的方法
文章图片
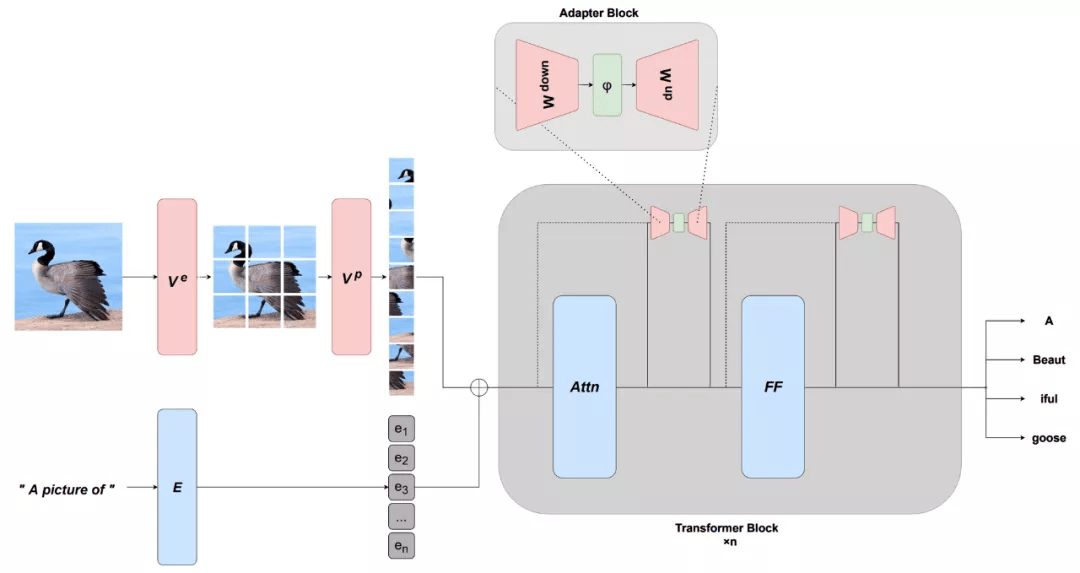
预训练模型的一个缺点是 , 它们通常非常大 , 而且在实践中效率低下 。 2021 年研究者带来了更高效的架构和更高效的微调方法 。 在建模方面 , 我们可以看到几个更有效的自注意力版本 。 当前预训练模型非常强大 , 只需更新少量参数即可有效地调节模型 , 这促进了基于连续提示和适配器(adapter)等更有效的微调方法的发展 。 高效的方法还可以通过学习适当的前缀(prefix)或适当的转换来适应新的模式 。
为什么高效的方法很重要?如果模型在标准硬件上运行不可行或过于昂贵 , 那么它们就没有意义 。 效率的提高将确保模型在变得更大的同时 , 对实践人员有益并易于使用 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。