得益于更强的灵活性 , token-free 模型能够更好地建模词法 , 在面对新词和语言变化时也能泛化得很好 。 但是 , 依然不清楚的是:与基于字词的方法相比 , token-free 模型在不同类型的构词处理上的表现如何 , 以及它们在哪些方面做了权衡 。
时序自适应
文章图片
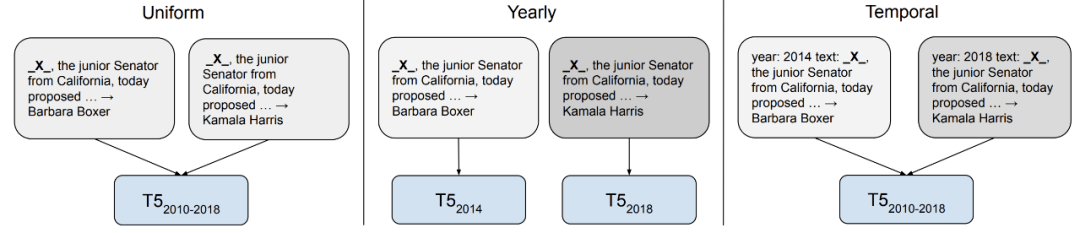
模型根据其训练时使用的数据 , 会在很多方面表现出偏见 。 2021 年 , 受到了越来越多关注的一种偏见是对模型训练数据的时间框架(timeframe)的偏见 。 考虑到语言持续演化 , 新的术语不断出现 , 在过时数据上训练的模型已被证实泛化性能不佳 。 但是 , 时序自适应是否有用 , 可能取决于下游任务 。 比如 , 对于那些语言使用中事件驱动变化与任务性能无关的任务而言 , 时序自适应可能帮助不大 。
在某些问答任务中 , 一个问题的答案根据问问题的时间而变化 。 时序自适应对于这类问答任务极其重要 。
开发可以适应新时间框架的方法需要摆脱静态的预训练微调( pre-train–fine-tune)范式 , 并需要更高效的方法来更新预训练模型知识 。 在这方面 , 高效方法和检索增广都很有用 。 此外 , 我们还需要开发新的模型 , 使得输入不存在于真空中 , 而是建立在非语言上下文和现实世界的基础上 。
数据的重要性

文章图片
长期以来 , 数据都是 ML 至关重要的一环 , 但往往被建模方面的进展所掩盖 。 然而 , 考虑到数据在模型扩展中的重要性 , 研究社区也慢慢从以模型为中心(model-centric)转向以数据为中心(data-centric)的方法 。 重要的主题包括如何高效地构建和维护新数据集 , 以及如何保证数据质量 。 此外 , 预训练模型使用的大规模数据集在 2021 年受到了审查 , 包括多模态数据集、英语和多语种文本语料库 。
数据在训练大规模 ML 模型时至关重要 , 并且是模型获取新信息的关键因素 。 随着模型规模越来越大 , 保证大规模数据的质量变得越来越具有挑战性 。
目前 , 对于如何高效构建用于不同任务的数据集 , 以及如何可靠地保证数据质量 , 我们在这些方面缺乏最佳实践和原则性方法 。 此外 , 数据如何与模型学习交互以及数据如何形成模型偏见 , 在这些方面依然理解不深 。
元学习

文章图片
尽管元学习和迁移学习有着共同的目标 , 但主要是在不同的社区中进行研究 。 在一个新的基准上 , 大规模迁移学习方法优于元学习方法 。 一个有希望的发展方向是扩展元学习方法 , 结合存储效率更高的训练方法 , 提高元学习模型在现实世界基准测试中的性能 。 元学习方法还可以与高效的自适应方法(如 FiLM 层)相结合 , 使通用模型更高效地适应新的数据集 。
元学习是一种重要的范式 , 但在设计时未考虑到元学习系统的标准基准上未能实现 SOTA 结果 。 将元学习和迁移学习社区更紧密地联系在一起 , 可能会产生在现实世界应用中更有用的元学习方法 。
当与用于大规模多任务学习的大量自然任务相结合时 , 元学习特别有用 。 元学习还可以通过学习如何根据大量可用提示设计或使用提示 , 来提升提示(prompting) 。
【一年一总结的NLP年度进展,2021年有哪些研究热点?】博客链接:https://ruder.io/ml-highlights-2021/
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。