下一步是什么?高效的模型和训练方法应该变得更容易使用和更容易获得 。 同时 , 社区应该开发更有效的方式来与大模型交互 , 并有效地适应、组合或修改它们 , 而无需从头开始预训练新模型 。
基准测试
文章图片
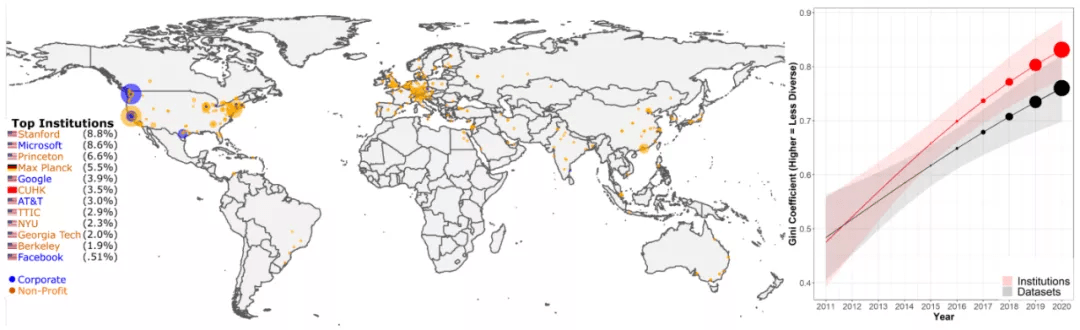
近来 ML 和 NLP 模型的快速改进已经超越了许多基准度量的能力 。 与此同时 , 社区评估的基准越来越少 , 这些基准只来自少数精英机构 。 因此 , 2021 年出现了很多能够可靠评估此类模型的方法的实践与讨论 , 我在这篇博文中对此进行了介绍 。
2021 年在 NLP 社区中出现的重要排行榜形式包括动态对抗性评估、社区驱动型评估(社区成员合作创建评估数据集 , 例如 BIG-bench)、跨多种错误类型的交互式细粒度评估、超越单一性能指标评估模型的多维评估。 此外 , 领域内针对有影响力的设置还提出了新的基准 , 例如小样本评估和跨域泛化 。 一些用于评估通用预训练模型的新基准也应运而生 , 包括用于语音、特定语言等特定模态的基准和跨模态基准 。
另一方面 , 评估指标也是应该关注的重点 。 机器翻译 (MT) 元评估显示:尽管已经提出了 108 个具有更好人类相关性的替代指标 , 但在过去十年的 769 篇机器翻译论文中 , 74.3% 的论文仍然仅使用了 BLEU 。 因此 , 一些研究(例如 GEM 和二维排行榜)提出联合评估模型和方法 。
基准测试和评估是机器学习和 NLP 进步的关键 。 如果没有准确可靠的基准 , 就无法判断我们是在取得真正的进步还是对根深蒂固的数据集和指标的过度拟合 。
提高对基准测试的认识将使得新数据集的设计更具深思熟虑 。 对新模型的评估也应减少对单一性能指标的关注 , 而应考虑多个维度 , 例如模型的公平性、效率和稳健性 。
条件图像生成
文章图片
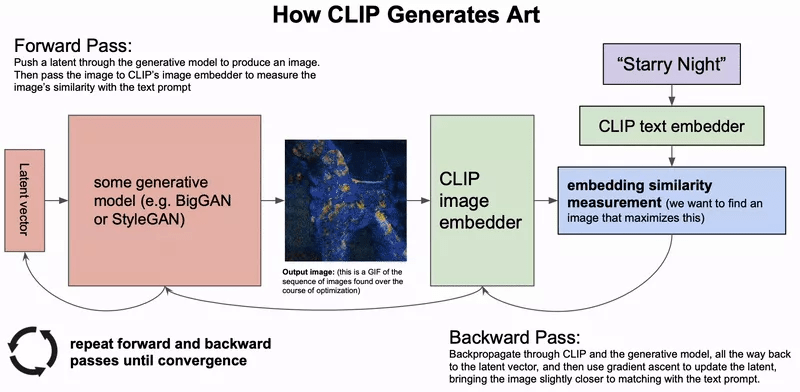
条件图像生成 , 即基于文本描述生成图像 , 这一领域在 2021 年取得了令人瞩目的成果 。 围绕最新一代的生成模型涌现出一系列进展 。 最新的方法不是直接基于 DALL-E 模型中的文本输入生成图像 , 而是使用联合图像文本嵌入模型(例如 CLIP)指导生成模型(例如 VQ-GAN)的输出 。 基于似然的扩散模型逐渐消除了信号中的噪声 , 已成为强大的新生成模型 , 其性能优于 GAN 。 通过基于文本输入指导其输出 , 最近的模型已经可以生成逼真的图像 。 这类模型也特别擅长修复 , 可以根据描述修改图像的区域 。
自动生成由用户指导的高质量图像具有广泛的艺术和商业应用前景 , 包括视觉产品的自动设计、模型辅助的设计、个性化等 。
与基于 GAN 的模型相比 , 基于扩散的模型的采样速度要慢得多 , 因此这些模型需要提高效率才能具有实际作用 。 此外 , 该领域还需要对人机交互进行更多研究 , 以确定此类模型帮助人类的最佳应用方式 。
与自然科学结合的机器学习
文章图片
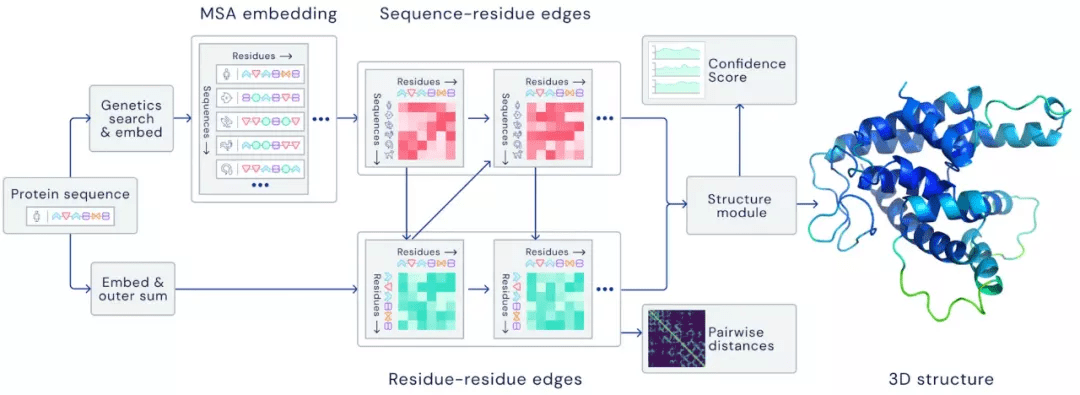
2021 年 , 机器学习在推动自然科学方面取得了多项突破 。 在气象学方面 , 机器学习与降水预报的结合大大提高了预测的准确性 , 使得模型优于最先进的物理预测模型 。 在生物学方面 , AlphaFold 2.0 使得在不知道类似结构的情况下 , 也能以前所未有的准确率预测蛋白质的结构 。 在数学方面 , ML 被证明能够引导数学家的直觉 , 以发现新的联系和算法 。 Transformer 模型也被证明经过足量数据训练后可学习差分系统的数学特性 , 例如局部稳定性 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。