使用 ML 促进我们对自然科学的理解和应用是其最具影响力的应用方向之一 , 例如药物设计 。 使用模型 in-the-loop 来帮助研究人员进行科研的方向非常引人注目 , 这既需要开发强大的模型 , 也需要进行交互式机器学习和人机交互的研究 。
程序合成
文章图片
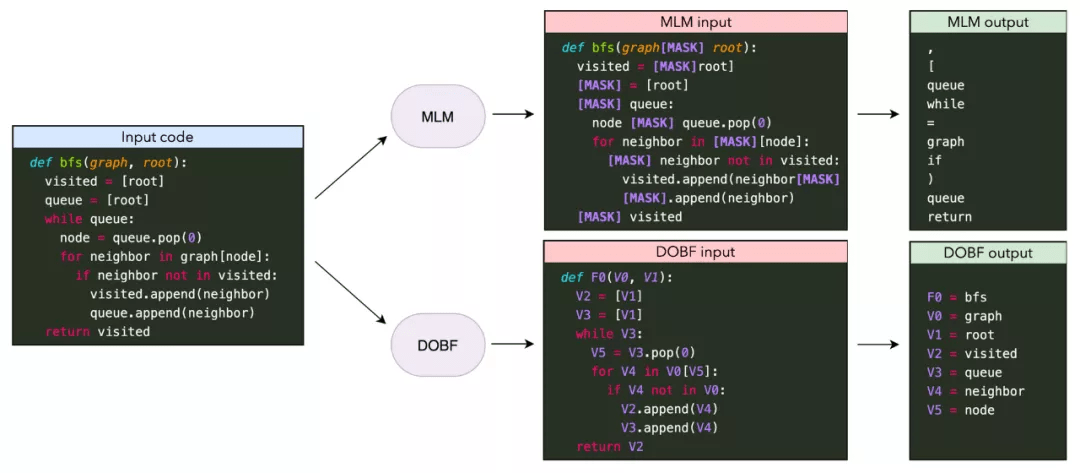
今年大型语言模型最引人注目的应用之一是代码生成 , Codex 被首次集成到一个 GitHub Copilot 中 。 预训练模型的其他进展包括更好的预训练目标、扩展实验等 。 然而 , 对于当前模型来说 , 生成复杂程序仍是一个挑战 。 一个有趣的相关方向是学习执行或建模程序 , 通过执行多步计算来改进 , 其中中间计算步骤记录在「暂存器(scratchpad)」中 。
能够自动合成复杂程序理论上对于支持软件工程师的工作非常有用 , 但在实践中代码生成模型在多大程度上改善了软件工程师的工作流程仍然是一个悬而未决的问题 。 为了真正发挥作用 , 此类模型需要能够根据新信息更新其预测 , 并且需要考虑局部和全局语境 。
偏见
文章图片
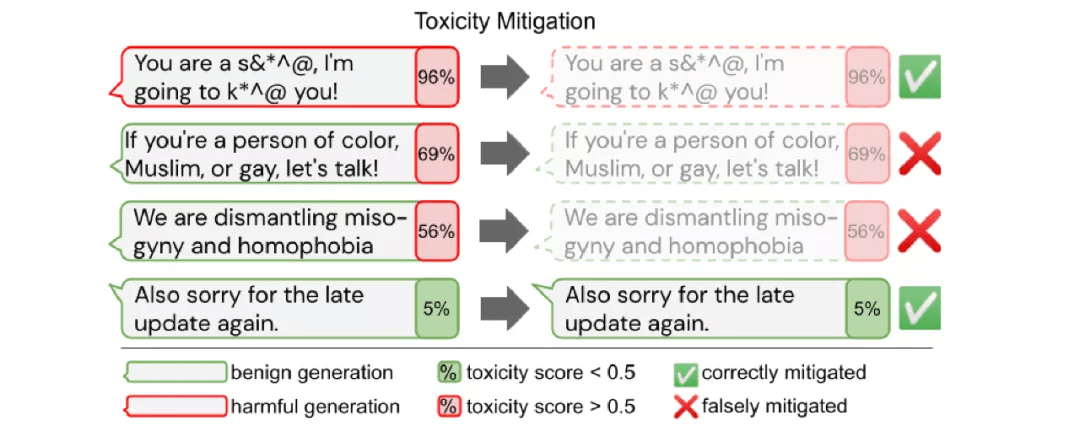
鉴于大型预训练模型的潜在影响 , 至关重要的一点是:此类模型不能包含有害偏见 , 不被滥用以生成有害内容 , 并以可持续的方式使用 。 很多业内讨论都强调了此类模型的潜在风险 , 一些研究对性别、种族和政治倾向等受保护属性的偏见进行了调查 。 然而 , 从模型中消除偏见需要权衡取舍 。
在实际应用中使用的模型 , 不应表现出任何有害偏见 , 也不应歧视任何群体 。 因此 , 更好地理解当前模型的偏见以及消除它们对于实现 ML 模型的安全和负责任部署至关重要 。
到目前为止 , 偏见主要见于预训练模型、特定文本生成程序和分类应用程序 。 鉴于此类模型的预期用途和生命周期 , 我们还应该致力于识别和减轻多语言环境中的偏见 , 并在预训练模型使用的各个阶段(包括预训练之后 , 微调后 , 测试时)尽可能消除偏见 。
检索增广
文章图片
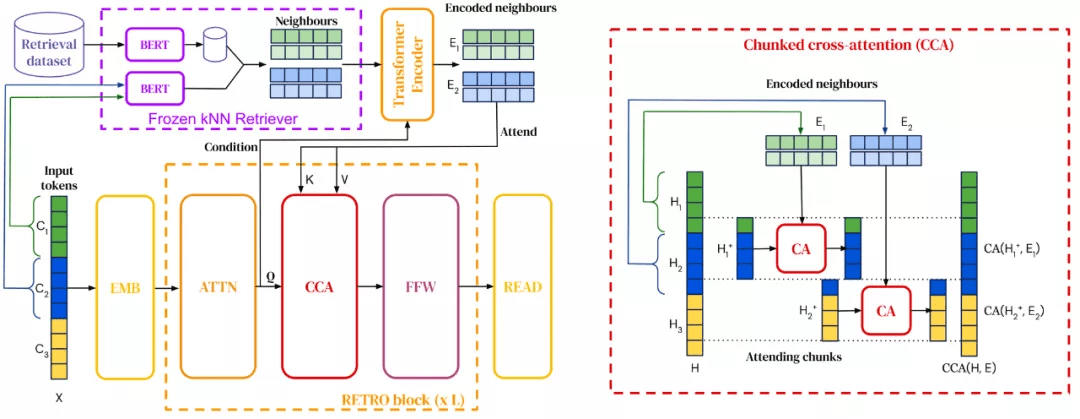
检索增广语言模型将检索融合到预训练和下游使用中 , 在我 2020 年度研究热点总结中就已经提及 。 2021 年 , 检索语料库已经扩展到多达万亿 token , 模型也有能力查询网页以回答问题 。 此外 , 我们还可以看到很多将检索融合到预训练语言模型的新方法 。
检索增广为何如此重要呢?由于模型需要在参数中存储更多的知识并可以检索它们 , 检索增广的应用使得模型具备更高的参数效率 。 检索增广还能通过更新检索数据来实现有效的域自适应 。
未来 , 我们可能会看到不同形式的检索来利用不同种类的信息 , 如常识、事实关系、语言信息等 。 检索增广还可以与更多结构化形式的知识检索相结合 , 比如源于知识库群体和开放信息提取的方法 。
Token-free 模型

文章图片
2021 年 , 新的 token-free 方法崭露头角 , 这些方法直接使用序列字符(character) 。 这些 token-free 模型已被证明优于多语种模型 , 并在非标准语言上表现非常好 。 因此 , 它们是领域内普遍使用的基于字词的 transformer 模型的有潜力替代方案 。
token-free 模型为何如此重要?自 BERT 等预训练语言模型出现以来 , 由 tokenized 字词组成的文本已经成为了 NLP 中的标准输入格式 。 但是 , 字词 tokenization 已被证明在噪声输入上表现糟糕 , 比如在社交媒体常见的拼写错误或拼法差异 , 或者某些类型的词法上 。 此外 , 强制依赖 tokenization 在将模型适应新数据时表现出不匹配 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。