选自ruder.io
作者:Sebastian Ruder
机器之心编译
机器之心编辑部
2021 年已经过去 , 这一年里 , 机器学习(ML)和自然语言处理(NLP)又出现了哪些研究热点呢?谷歌研究科学家 Sebastian Ruder 的年度总结如约而至 。
文章图片
2021 年 , ML 和 NLP 领域取得了很多激动人心的进展 。 在 Sebastian Ruder 的最新博客《ML and NLP Research Highlights of 2021》中 , 他介绍了自己认为最具有启发意义的论文和研究领域 。

文章图片
文章涵盖了 15 个研究热点 , 具体如下:
- 通用预训练模型
- 大规模多任务学习
- Transformer 架构替代方案
- 提示( prompting)
- 高效的方法
- 基准测试
- 条件图像生成
- 与自然科学结合的机器学习
- 程序合成
- 偏见
- 检索增广
- Token-free 模型
- 时序自适应
- 数据的重要性
- 元学习
文章图片
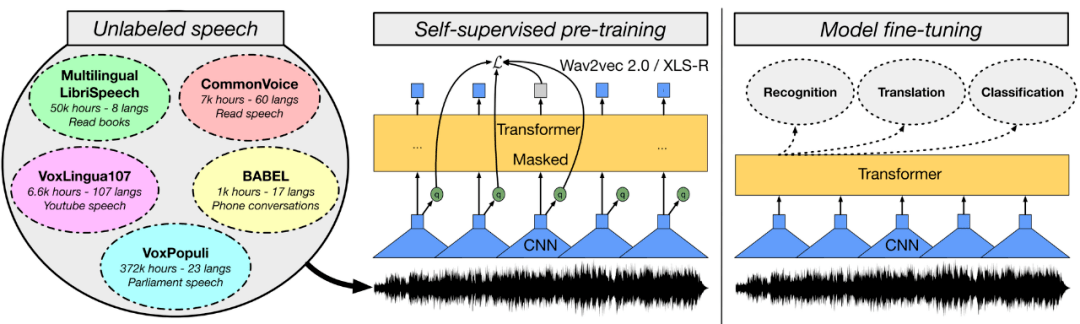
2021 年研究者开发了更大的预训练模型 。 预训练模型可以应用于不同的领域 , 对 ML 研究至关重要 。 在计算机视觉中 , 有监督预训练模型如 Vision Transformer 继续被扩展 , 而自监督预训练模型性能也在不断提高 。 在语音方面 , 基于 wav2vec 2.0 模型(如 W2v-BERT) , 以及更强大的多语言模型(如 XLS-R)已经被构建出来 。 与此同时 , 新的统一预训练模型可用于不同的模态(例如视频和语言等) 。 在视觉和语言方面 , 对照研究揭示了这种多模态模型的重要组成部分 。 此外 , 预训练模型在强化学习和蛋白质结构预测等其他领域也取得了巨大进展 。
为什么预训练模型如此重要?预训练模型已被证明可以很好地泛化到给定领域或不同模态中 。 它们表现出较强的小样本学习行为和良好的学习能力 。 因此 , 预训练模型是进行科学研究和实际应用的重要组成部分 。
下一步是什么?我们无疑将在未来看到更多甚至更大的预训练模型 。 同时 , 我们应该期望单个模型同时执行多个任务 。 在语言任务中 , 模型以通用的文本到文本格式构建执行不同的任务 。 同样 , 我们可能会看到在单个模型中执行图像和语音任务的模型 。 最后 , 我们将看到更多的、针对多模态进行训练的模型 。
大规模多任务学习
文章图片
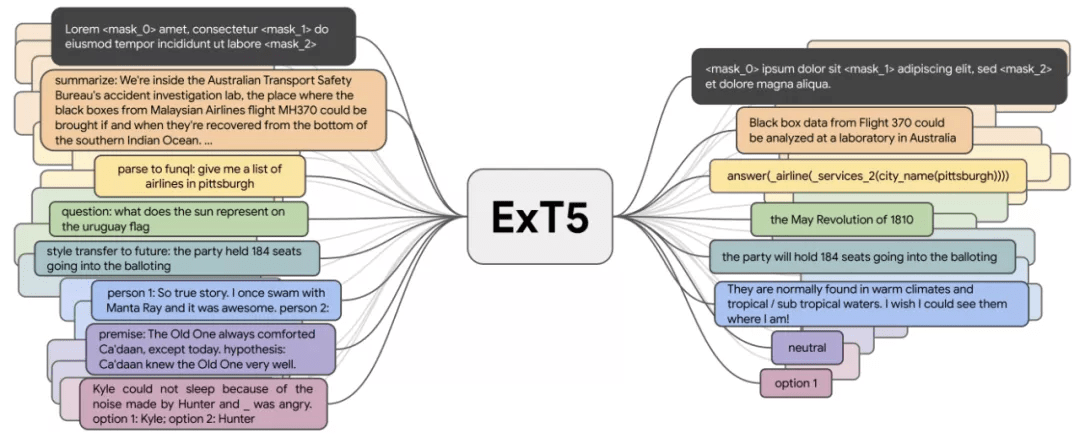
上一节中的大多数预训练模型都是自监督的 , 它们从大量未标记的数据中学习 。 然而 , 对于许多领域 , 已经有大量标记数据可用 , 可用于学习更好的表示 。 到目前为止 , T0、FLAN 和 ExT5 等多任务模型已经在大约 100 个任务上进行了预训练 , 可用于语言任务 。 如此大规模的多任务学习与元学习密切相关 。 通过访问不同的任务分配 , 模型可以学习不同类型的行为 , 比如如何在上下文中学习 。
为什么多任务模型很重要?T5 、 GPT-3 等许多模型可以使用文本到文本格式 , 因此可以进行大规模多任务学习 。 因此 , 模型不再需要手工设计的、特定于任务的损失函数或特定于任务的层 , 以便有效地跨多个任务学习 。 这些方法突出了将自监督预训练与监督的多任务学习相结合的好处 , 并证明了两者的结合会产生更通用的模型 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。