文章图片
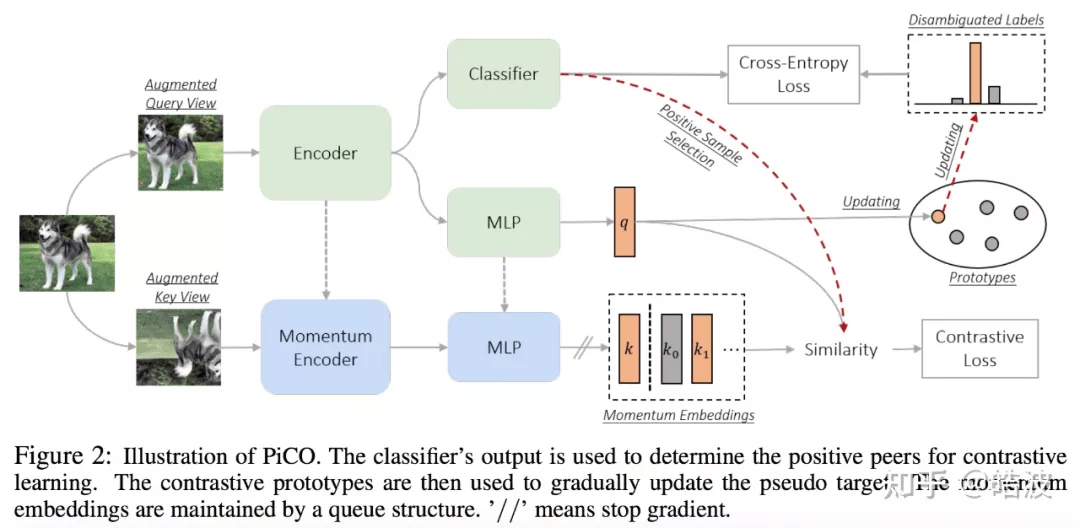
框架
简而言之 , PiCO 包含两个关键组件 , 分别进行表示学习和标签消歧 。 这两个组件系统地作为一个整体运行并相互反哺 。 后续 , 研究者也会进一步从 EM 的角度对 PiCO 的进行严格的理论解释 。
分类损失(Classification Loss)
给定数据集
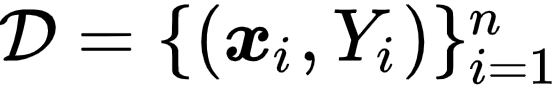
文章图片
, 每个元组包含
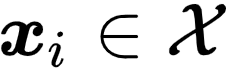
文章图片
和一个候选标签集合
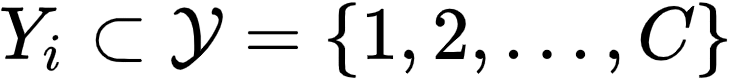
文章图片
。 为了有效解决 PLL 问题 , 研究者为每个样本
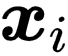
文章图片
维护一个伪标签向量
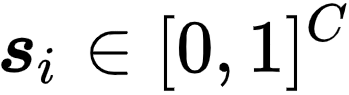
文章图片
。 在训练过程中 , 研究者会不断更新这个伪标签向量 , 而模型则会优化以下损失进行更新分类器
文章图片
,
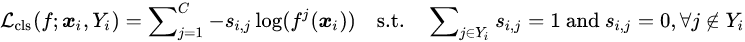
文章图片
PLL的对比表征学习(Contrastive Representation Learning For PLL)
受到监督对比学习(SCL)[3] 的启发 , 研究者旨在引入对比学习机制 , 为来自同一类的样本学习相近的表征 。 PiCO 的基本结构和 MoCo [4] 类似 , 均由两个网络构成 , 分别为 Query 网络
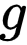
文章图片
和 Key 网络
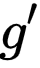
文章图片
。 给定一个样本
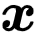
文章图片
, 研究者首先利用随机数据增强技术获得两个增广样本 , 分别称为 Query View 和 Key View 。 然后 , 它们会被分别输入两个网络 , 获得一对
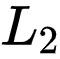
文章图片
- 归一化的 embeddings , 即
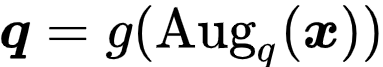
文章图片
和
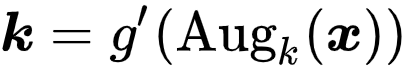
文章图片
。
实现时 , 研究者让 Query 网络与分类器共享相同的卷积块 , 并增加一个额外的投影网络 。 和 MoCo 一样 , 研究者利用 Query 网络的动量平均(Momentum Averaging)技术对 Key 网络进行更新 。 并且 , 研究者引入一个队列 queue , 存储过去一段时间内的 Key embedding 。 由此 , 研究者获得了以下的对比学习 embedding pool:
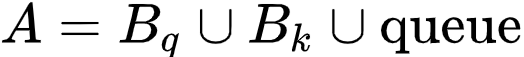
文章图片
。 接着 , 研究者根据如下公式计算每个样本的对比损失:

特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。