文章图片
其中
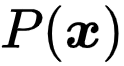
文章图片
是对比学习中的正样本集 , 而
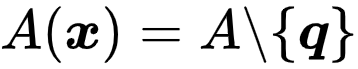
文章图片
。
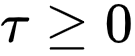
文章图片
是温度参数 。
Positive Set 选择 。 可以发现 , 对比学习模块中 , 最重要的问题即为正样本集合的构建 。 然而 , 在 PLL 问题中 , 真实标签是未知的 , 因此无法直接选择同类样本 。 因此 , 研究者采用了一个简单而有效的策略 , 即直接使用分类器预测的标签:
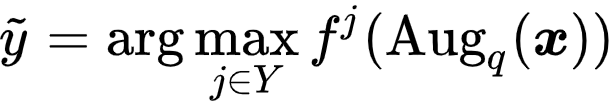
文章图片
, 构建如下正样本集:
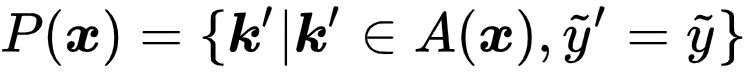
文章图片
为了节约计算效率 , 研究者还维护一个标签队列来存储之前几个 Batch 的预测 。 尽管该策略很简单 , 却能得到非常好的实验结果 , 并且能够从理论上被证明该策略是行之有效的 。
基于原型的标签消歧(Prototype-based Label Disambiguation)
值得注意的是 , 对比学习依然依赖于准确的分类器预测 , 因此依然需要一个有效的标签消歧策略 , 获取准确的标签估计 。 为此 , 研究者提出了一个新颖的基于原型的标签消歧策略 。 具体的 , 研究者为每个标签
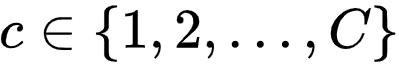
文章图片
维护了一个原型 embedding 向量
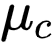
文章图片
, 它可以被看作一组具有代表性的 embedding 向量 。
伪标签更新 。 在学习过程中 , 研究者首先将 S 初始化为 Uniform 向量
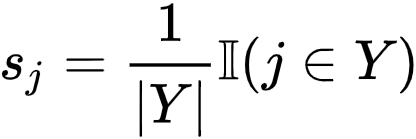
文章图片
。 接着 , 基于类原型 , 研究者采用一个滑动平均的策略更新伪标签向量 ,
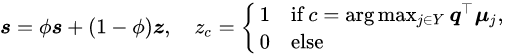
文章图片
即 , 研究者选择最近的原型对应的标签 , 逐步更新伪标签 S 。 此处 , 采用滑动平均原因是对比学习网络输出的 embeddings 在初始阶段并不可靠 , 此时拟合 Uniform 伪目标能够很好地初始化分类器 。 然后 , 滑动平均策略伪标签平滑地更新为正确的目标 , 以确保一个稳定的 Traning Dynamic 。
原型更新 。 为了更新伪标签 , 一个简单的方法是每个迭代或者 Epoch 中都计算一次每个类的中心 , 不过这会引起较大的计算代价 。 因此研究者再一次使用滑动平均技术更新原型 ,
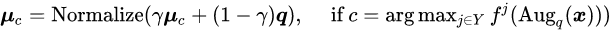
文章图片
即 , 当
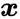
文章图片
被预测为类别
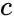
文章图片
时 , 则令
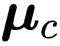
文章图片
往对应的
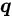
文章图片
向量方向步进一些 。
Insights. 值得注意的是 , 这两个看似独立的模块实际上能够协同工作 。 首先 , 对比学习在 embeddings 空间中具有聚类效果 , 因此能够被标签消歧模块利用 , 以获得更准确的类中心 。 其次 , 经过标签消歧后 , 分类器预测的标签更准确 , 能够反哺对比学习模块构造更精准的 Positive Set 。 当两个模块达成一致时 , 整个训练过程就会收敛 。 研究者在接下来在理论上更严格地讨论 PiCO 与经典 EM 聚类算法的相似之处 。特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。