实验结果
主要结果
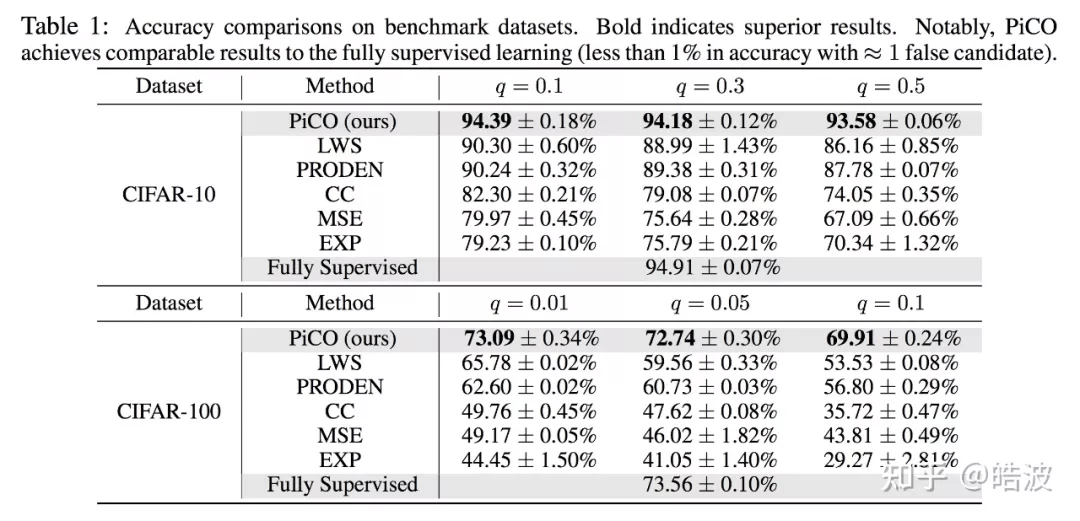
在展开理论分析之前 , 研究者首先看一下 PiCO 优异的实验效果 。 首先是在 CIFAR-10、CIFAR-100 上的结果 , 其中 ,
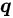
文章图片
表示每个 Negative Label 成为候选标签的概率 。
文章图片
如上图 , PiCO 达到了十分出色的实验结果 , 在两个数据集、不同程度的歧义下(对应
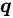
文章图片
的大小) , 均取得了 SOTA 的结果 。 值得注意的是 , 之前的工作 [5][6] 均只探讨了标签量较小的情况(
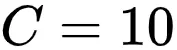
文章图片
) , 研究者在 CIFAR-100 上的结果表明 , 即使在标签空间较大 , PiCO 依然具有十分优越良好的性能 。 最后 , 值得注意的是 , 当
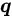
文章图片
相对较小的时候 , PiCO 甚至达到了接近全监督的结果!
表征学习
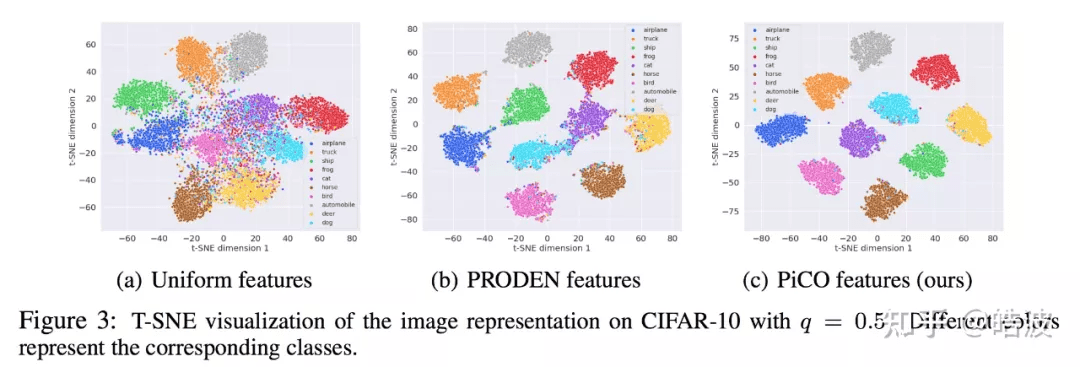
除此之外 , 研究者还可视化了不同方法学习到的表征 , 可以看到 Uniform 标签导致了模糊的表征 , PRODEN 方法学习到的簇则存在重叠 , 无法完全分离 。 相比之下 , PiCO 学习的表征更紧凑 , 更具辨识度 。
文章图片
消融实验
最后 , 研究者展示不同的模块对实验结果的影响 , 可以看到 , 标签消歧模块和对比学习模块都会带来非常明显的性能提升 , 消融其中一个会带来
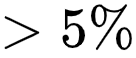
文章图片
的性能下降 。 更多的实验结果请详见原论文 。

文章图片
理论分析
终于到了最激动人心的部分!相信大家都有一个疑问:为什么 PiCO 能够获得如此优异的结果?本文中 , 研究者从理论上分析对比学习得到的原型有助于标签消歧 。 研究者将会展示 , 对比学习中的对齐性质(Alignment)本质上最小化了 embedding 空间中的类内协方差 , 这与经典聚类算法的目标是一致的 。 这促使研究者从期望最大化算法(Expectation-Maximization , EM)的角度来解释 PiCO 。
首先 , 研究者考虑一个理想的 Setup:在每个训练步骤中 , 所有数据样本都是可访问的 , 并且增广的样本也包含在训练集中 , 即
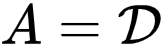
文章图片
。 然后 , 可以如下计算对比损失:
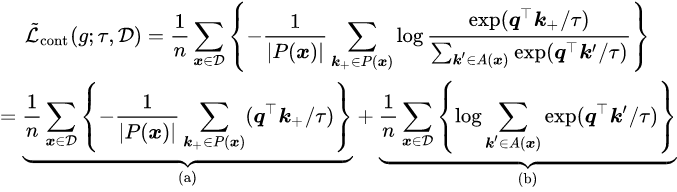
文章图片
研究者主要关注第一项 (a) , 即 Alignment 项 [2] , 另一项 Uniformity 则被证明有利于 Information-Preserving 。 在本文中 , 研究者将其与经典的聚类算法联系起来 。 研究者首先将数据集划分为
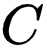
文章图片
个子集
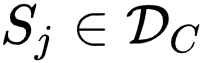
文章图片
, 其中每个子集中的样本包含具有相同的预测标签 。 实际上 , PiCO 的 Positive Set 选择策略也是通过从相同的策略来构造 Positive Sets 。 因此 , 研究者有 ,
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。