机器之心专栏
作者:王皓波
本文介绍浙江大学、威斯康星大学麦迪逊分校等机构的最新工作 PiCO , 相关论文已被 ICLR 2022 录用(Oral, Top 1.59%)!偏标签学习 (Partial Label Learning, PLL) 是一个经典的弱监督学习问题 , 它允许每个训练样本关联一个候选的标签集合 , 适用于许多具有标签不确定性的的现实世界数据标注场景 。 然而 , 现存的 PLL 算法与完全监督下的方法依然存在较大差距 。
为此 , 本文提出一个协同的框架解决 PLL 中的两个关键研究挑战 —— 表征学习和标签消歧 。 具体地 , 研究者提出的 PiCO 由一个对比学习模块和一个新颖的基于类原型的标签消歧算法组成 。 PiCO 为来自同一类的样本生成紧密对齐的表示 , 同时促进标签消歧 。 从理论上讲 , 研究者表明这两个组件能够互相促进 , 并且可以从期望最大化 (EM) 算法的角度得到严格证明 。 大量实验表明 , PiCO 在 PLL 中显着优于当前最先进的 PLL 方法 , 甚至可以达到与完全监督学习相当的结果 。

文章图片
- 论文地址:https://arxiv.org/pdf/2201.08984v2.pdf
- 项目主页:https://github.com/hbzju/pico
深度学习的兴起依赖于大量的准确标注数据 , 然而在许多场景下 , 数据标注本身存在较大的不确定性 。 例如 , 大部分非专业标注者都无法确定一只狗到底是阿拉斯加还是哈士奇 。 这样的问题称为标签歧义(Label Ambiguity) , 源于样本本身的模糊性和标注者的知识不足 , 在更需要专业性的标注场景中十分普遍 。 此时 , 要获得准确的标注 , 通常需要聘用具有丰富领域知识的专家进行标注 。 为了减少这类问题的标注成本 , 本文研究偏标签学习 [1](Partial Label Learning , PLL) , 在该问题中 , 研究者允许样本
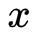
文章图片
关联一个候选标签集合
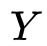
文章图片
, 其中包含了真实的标签
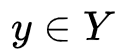
文章图片
。
在 PLL 问题中 , 最重要的问题为标签消歧(Disambiguation) , 即从候选标签集合中识别得到真实的标签 。 为了解决 PLL 问题 , 现有的工作通常假设样本具有良好的表征 , 然后基于平滑假设进行标签消歧 , 即假设特征接近的样本可能共享相同的真实标签 。 然而 , 对表征的依赖致使 PLL 方法陷入了表征 - 消歧困境:标注的不确定性会严重影响表征学习 , 表征的质量又反向影响了标签消歧 。 因此 , 现有的 PLL 方法的性能距离完全监督学习的场景 , 依然存在一定的差距 。
为此 , 研究者提出了一个协同的框架 PiCO , 引入了对比学习技术(Contrastive Learning , CL) , 来同时解决表示学习和标签消歧这两个高度相关的问题 。 本文的主要贡献如下:
- 方法:本论文率先探索了部分标签学习的对比学习 , 并提出了一个名为 PiCO 的新框架 。 作为算法的一个组成部分 , 研究者还引入了一种新的基于原型的标签消歧机制 , 有效利用了对比学习的 embeddings 。
- 实验:研究者提出的 PiCO 框架在多个数据集上取得了 SOTA 的结果 。 此外 , 研究者首次尝试在细粒度分类数据集上进行实验 , 与 CUB-200 数据集的最佳基线相比 , 分类性能提高了 9.61% 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。