一个与集群管理器良好集成的系统负责持续检测主机问题 。 集群管理器能做出很多智能决策 , 例如限制速率以避免同时停用过多的损坏主机 。 Hadoop 管理器在采取任何行动之前会确保集群在不同的系统变量下都是健康的 。 Hadoop 管理器中包含的检查可确保集群中不存在丢失或复制不足的块 , 并且在运行关键运维操作之前确保数据在 DataNode 之间保持均衡 , 并执行其他必要检查 。
使用声明式运维模型(使用目标状态)后 , 我们减少了运维集群时的人工操作 。 一个很好的例子是系统可以自动检测到损坏主机并将其安全地从集群中停用以待修复 。 每退役一台损坏主机 , 系统都会补充一个新主机来保持集群容量不变(维持目标状态中所定义的容量) 。
下图显示了由于各种问题在一周时间段内的各个时间点退役的 HDFS DataNode 数量 。 每种颜色描绘了一个 HDFS 集群 。
图 3:自动检测和停用损坏的 HDFS 数据节点
容器化 Hadoop
在过去 , 我们基础设施的内在可变性曾多次给我们带来了意想不到的麻烦 。 有了新架构后 , 我们得以在不可变 Docker 容器中运行所有 Hadoop 组件(NodeManager、DataNode 等)和 YARN 应用程序 。
当我们开始重构时 , 我们在生产环境中为 HDFS 运行的是 Hadoop v2.8 , 为 YARN 集群运行的是 v2.6 。 v2.6 中不存在对 YARN 的 Docker 支持 。 鉴于依赖 YARN 的多个系统(Hive、Spark 等)对 v2.x 存在紧密依赖 , 将 YARN 升级到 v3.x(以获得更好的 Docker 支持)是一项艰巨的任务 。 我们最终将 YARN 升级到了支持 Docker 容器运行时的 v2.9 , 并从 v3.1 向后移植了几个补丁(YARN-5366、YARN-5534) 。
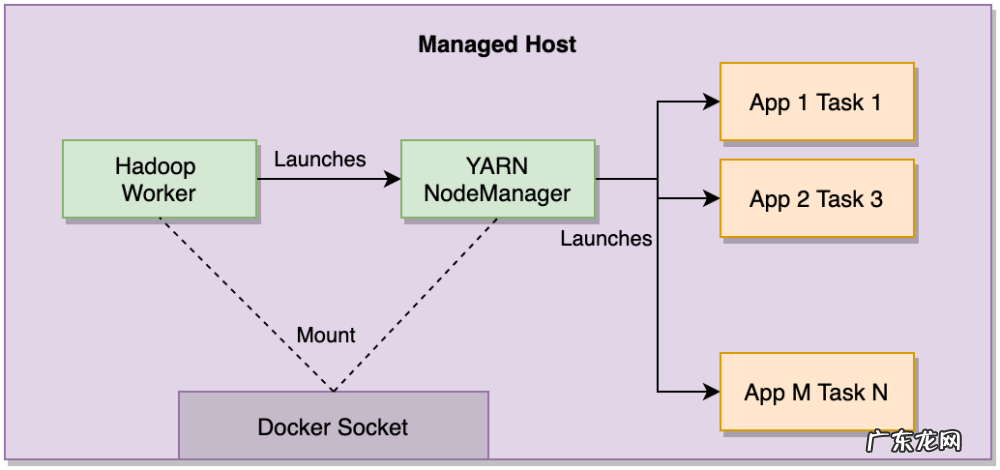
YARN NodeManager 运行在主机上的 Docker 容器中 。 主机 Docker 套接字挂载到 NodeManager 容器 , 使用户的应用程序容器能够作为兄弟容器启动 。 这绕过了运行 Docker-in-Docker 会引入的所有复杂性 , 并使我们能够在不影响客户应用程序的情况下管理 YARN NodeManager 容器的生命周期(例如 重启) 。
文章插图
图 4:YARN NodeManager 和应用程序兄弟容器
为了让超过 150,000 多个应用程序从裸金属 JVM(DefaultLinuxContainerRuntime)无缝迁移到 Docker 容器(DockerLinuxContainerRuntime) , 我们添加了一些补丁以在 NodeManager 启动应用程序时支持一个默认 Docker 镜像 。 此镜像包含所有依赖项(python、numpy、scipy 等) , 使环境看起来与裸金属主机完全一样 。
在应用程序容器启动期间拉取 Docker 镜像会产生额外的开销 , 这可能会 导致超时 。 为了规避这个问题 , 我们通过 Kraken 分发 Docker 镜像 。 Kraken 是一个最初在 Uber 内部开发的开源点对点 Docker 注册表 。 我们在启动 NodeManager 容器时预取默认应用程序 Docker 镜像 , 从而进一步优化了设置 。 这可确保在请求进入之前默认应用程序 Docker 镜像是可用的 , 以启动应用程序容器 。
所有 Hadoop 容器(DataNode、NodeManager)都使用卷挂载(volume mount)来存储数据(YARN 应用程序日志、HDFS 块等) 。 这些卷在节点放在托管主机上时可用 , 并在节点从主机退役 24 小时后删除 。
在迁移过程中 , 我们逐渐让应用转向使用默认 Docker 镜像启动 。 我们还有一些客户使用了自定义 Docker 镜像 , 这些镜像让他们能够带来自己的依赖项 。 通过容器化 Hadoop , 我们通过不可变部署减少了可变性和出错的几率 , 并为客户提供了更好的体验 。
- 塑化剂对孩子健康有什么影响
- 淘宝卖手办需要营业执照吗?如何优化?
- 9岁有赞发布数字化转型“10大观察”
- 宝宝肠胃不好,总是消化不良,也长不胖,该怎么办?
- 淘宝店铺涨价怎么回事?怎样优化价格?
- 发力“农研”的拼多多,正寻求电商领域的差异化发展路线
- 深蹲可以瘦腿吗?每天深蹲200个,坚持3个月会产生什么变化?
- 安利空气净化器排名 中国空气净化器排名
- 小狗身体强酸强碱化学物质的来源于
- 聚合新兴市场本地化支付,Grepay服务B2C客户跨境收单需求
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。