Kerberos 集成
我们所有的 Hadoop 集群都由 Kerberos 负责安全性 。 集群中的每个节点都需要在 Kerberos(dn/hdfs-dn-host-1.example.com)中 注册 主机特定服务主体 Principal(身份) 。 在启动任何 Hadoop 守护程序之前 , 需要生成相应的密钥表(Keytab)并将其安全地发送到节点 。
Uber 使用 SPIRE 来做负载证明 。 SPIRE 实现了 SPIFFE 规范 。 形式为 spiffe://example.com/some-service 的 SPIFFE ID 用于表示负载 。 这通常与部署服务的主机名无关 。
很明显 , SPIFFE 和 Kerberos 都用的是它们自己独特的身份验证协议 , 其身份和负载证明具有不同的语义 。 在 Hadoop 中重新连接整个安全模型以配合 SPIRE 并不是一个可行的解决方案 。 我们决定同时利用 SPIRE 和 Kerberos , 彼此之间没有任何交互 / 交叉证明 。
这简化了我们的技术解决方案 , 方案中涉及以下自动化步骤序列 。 我们“信任”集群管理器和它为从集群中添加 / 删除节点而执行的目标状态运维操作 。

文章插图
图 5:Kerberos 主体注册和密钥表分发
使用位置信息(目标状态)从集群拓扑中获取所有节点 。
将所有节点的对应主体注册到 Kerberos 中并生成相应的密钥表 。
在 Hashicorp Vault 中保存密钥表 。 设置适当的 ACL , 使其只能由 Hadoop Worker 读取 。
集群管理器代理获取节点的目标状态并启动 Hadoop Worker 。
Hadoop Worker 由 SPIRE 代理验证 。
Hadoop Worker:
获取密钥表(在步骤 2 中生成)
将其写入 Hadoop 容器可读的一个只读挂载(mount)
启动 Hadoop 容器
Hadoop 容器(DataNode、NodeManager 等):
从挂载读取密钥表
在加入集群之前使用 Kerberos 进行身份验证 。
一般来说 , 人工干预会导致密钥表管理不善 , 从而破坏系统的安全性 。 通过上述设置 , Hadoop Worker 由 SPIRE 进行身份验证 , Hadoop 容器由 Kerberos 进行身份验证 。 上述整个过程是端到端的自动化 , 无需人工参与 , 确保了更严格的安全性 。
用户组管理
在 YARN 中 , 分布式应用程序的容器作为提交应用程序的用户(或服务帐户)运行 。 用户组(UserGroup)在活动目录(Active Directory , AD)中管理 。 我们的旧架构需要通过 Debian 包安装用户组定义(从 AD 生成)的定期快照 。 这导致了全系统范围的不一致现象 , 这种不一致是由包版本差异和安装失败引起的 。
未被发现的不一致现象会持续数小时到数周 , 直到影响用户为止 。 在过去 4 年多的时间里 , 由于跨主机的用户组信息不一致引发的权限问题和应用程序启动失败 , 让我们遇到了不少麻烦 。 此外 , 这还导致了大量的手动调试和修复工作 。
Docker 容器中 YARN 的用户组管理自身存在一系列 技术挑战 。 维护另一个守护进程 SSSD(如 Apache 文档中所建议的)会增加团队的开销 。 由于我们正在重新构建整个部署模型 , 因此我们花费了额外的精力来设计和构建用于用户组管理的稳定系统 。
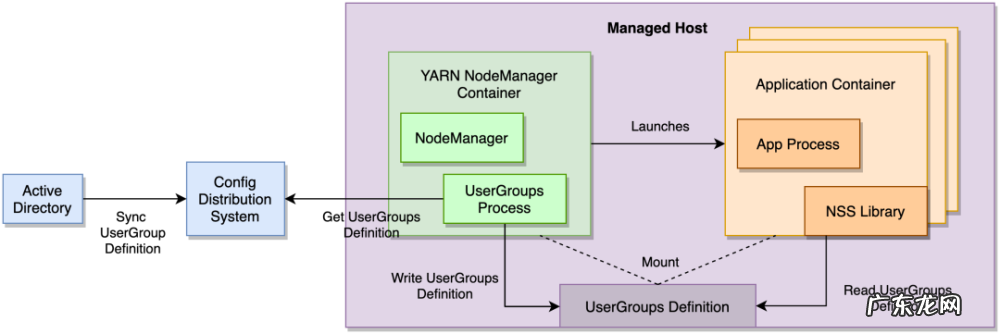
文章插图
图 6:容器内的用户组
我们的设计是利用一个经过内部强化、信誉良好的配置分发系统(Config Distribution System)将用户组定义中继到部署 YARN NodeManager 容器的所有主机上 。 NodeManager 容器运行用户组进程(UserGroups Process) , 该进程观察用户组定义(在配置分发系统内)的更改 , 并将其写入一个卷挂载 , 该挂载与所有应用程序容器(Application Container)以只读方式共享 。
- 塑化剂对孩子健康有什么影响
- 淘宝卖手办需要营业执照吗?如何优化?
- 9岁有赞发布数字化转型“10大观察”
- 宝宝肠胃不好,总是消化不良,也长不胖,该怎么办?
- 淘宝店铺涨价怎么回事?怎样优化价格?
- 发力“农研”的拼多多,正寻求电商领域的差异化发展路线
- 深蹲可以瘦腿吗?每天深蹲200个,坚持3个月会产生什么变化?
- 安利空气净化器排名 中国空气净化器排名
- 小狗身体强酸强碱化学物质的来源于
- 聚合新兴市场本地化支付,Grepay服务B2C客户跨境收单需求
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。