应用程序容器使用一个自定义 NSS 库(内部开发并安装在 Docker 镜像中)来查找用户组定义文件 。 有了这套解决方案 , 我们能够在 2 分钟内实现用户组在全系统范围内的一致性 , 从而为客户显著提高可靠性 。
配置生成
我们运营着 40 多个服务于不同用例的集群 。 在旧系统中 , 我们在单个 Git 存储库中独立管理每个集群的配置(每个集群一个目录) 。 结果复制粘贴配置和管理跨多个集群的部署变得越来越困难 。
通过新系统 , 我们改进了管理集群配置的方式 。 新系统利用了以下 3 个概念:
针对.xml 和.properties 文件的 Jinja 模板 , 与集群无关
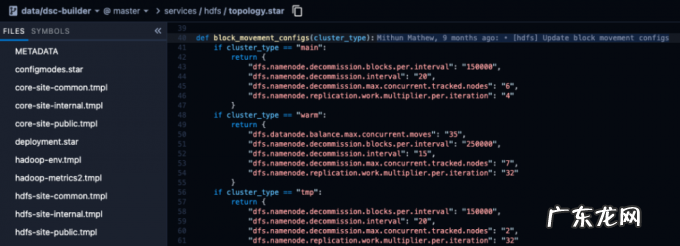
Starlark 在部署前为不同类别 / 类型的集群生成配置
节点部署期间的运行时环境变量(磁盘挂载、JVM 设置等)注入
文章插图
图 7:Starlark 文件定义不同集群类型的配置
我们将模板和 Starlark 文件中总共 66,000 多行的 200 多个.xml 配置文件减少到了约 4,500 行(行数减少了 93% 以上) 。 事实证明 , 这种新设置对团队来说更具可读性和可管理性 , 尤其是因为它与集群管理系统集成得更好了 。 此外 , 该系统被证明有利于为批处理分析栈中的其他相关服务(例如 Presto)自动生成客户端配置 。
发现与路由
在以前 , 将 Hadoop 控制平面(NameNode 和 ResourceManager)移动到不同的主机一直是很麻烦的操作 。 这些迁移通常会导致整个 Hadoop 集群滚动重启 , 还需要与许多客户团队协调以重启相关服务 , 因为客户端要使用主机名来发现这些节点 。 更糟糕的是 , 某些客户端倾向于缓存主机 IP 并且不会在出现故障时重新解析它们——我们从一次重大事件中学到了这一点 , 该事件让整个区域批处理分析栈降级了 。
Uber 的微服务和在线存储系统在很大程度上依赖于内部开发的服务网格来执行发现和路由任务 。 Hadoop 对服务网格的支持远远落后于其他 Apache 项目 , 例如 Apache Kafka 。 Hadoop 的用例以及将其与内部服务网格集成所涉及的复杂性无法满足工程工作的投资回报率目标 。 取而代之的是 , 我们选择利用基于 DNS 的解决方案 , 并计划将这些更改逐步贡献回开源社区(HDFS-14118、HDFS-15785) 。
我们有 100 多个团队每天都在与 Hadoop 交互 。 他们中的大多数都在使用过时的客户端和配置 。 为了提高开发人员的生产力和用户体验 , 我们正在对整个公司的 Hadoop 客户端进行标准化 。 作为这项工作的一部分 , 我们正在迁移到一个中心化配置管理解决方案 , 其中客户无需为初始化客户端指定典型的*-site.xml 文件 。
利用上述配置生成系统 , 我们能够为客户端生成配置并将配置推送到我们的内部配置分发系统 。 配置分发系统以可控和安全的方式在整个系统范围内部署它们 。 服务 / 应用程序使用的 Hadoop 客户端将从主机本地配置缓存(Config Cache)中获取配置 。

文章插图
图 8:客户端配置管理
标准化客户端(具有 DNS 支持)和中心化配置从 Hadoop 客户那里完全抽象出了发现和路由操作 。 此外 , 它还提供了一组丰富的可观察性指标和日志记录 , 让我们可以更轻松地进行调试 。 这进一步改善了我们的客户体验 , 并使我们能够在不中断客户应用程序的情况下轻松管理 Hadoop 控制平面 。
- 塑化剂对孩子健康有什么影响
- 淘宝卖手办需要营业执照吗?如何优化?
- 9岁有赞发布数字化转型“10大观察”
- 宝宝肠胃不好,总是消化不良,也长不胖,该怎么办?
- 淘宝店铺涨价怎么回事?怎样优化价格?
- 发力“农研”的拼多多,正寻求电商领域的差异化发展路线
- 深蹲可以瘦腿吗?每天深蹲200个,坚持3个月会产生什么变化?
- 安利空气净化器排名 中国空气净化器排名
- 小狗身体强酸强碱化学物质的来源于
- 聚合新兴市场本地化支付,Grepay服务B2C客户跨境收单需求
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。