可以看出 , RRL 显著优于其他可解释模型 , 只有两个复杂模型 , 即 LightGBM 和 XGBoost 有着相当的结果 。 此外 , RRL 在所有数据集上均取得了较好的结果 , 这也证明了 RRL 良好的可扩展性 。
表 2:13 个数据集上各模型的分类效果(五折交叉验证的 F1 Score)
模型复杂度
可解释模型追求在确保准确率可接受的前提下 , 尽可能降低模型复杂度 。 如果模型分类效果太差 , 那么再低的模型复杂度也没有意义 。 因此 , 从业人员真正关心的是模型分类效果与复杂度之间的关系 。
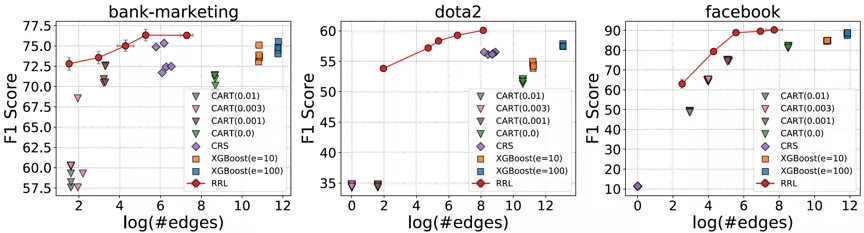
考虑到存在规则复用的情况 , 论文使用边的总数而不是规则总数来衡量基于规则的模型的复杂度(可解释性) 。 RRL , CART , CRS 以及 XGBoost 的模型复杂度与模型分类效果之间的关系如图 4 所示 , 其中横轴为复杂度 , 纵轴为分类效果 。 可以看出 , 相比其他规则模型和集成模型 , RRL 能够更加高效地利用规则 , 即用更低的模型复杂度获得更好的分类效果 。 结果还表明 , 通过参数设置 , RRL 可以轻松地在模型复杂度和分类性能间进行权衡 。
文章图片
图 4:RRL 与基线模型的模型复杂度与分类效果散点图 。
消融实验
离散模型训练方法
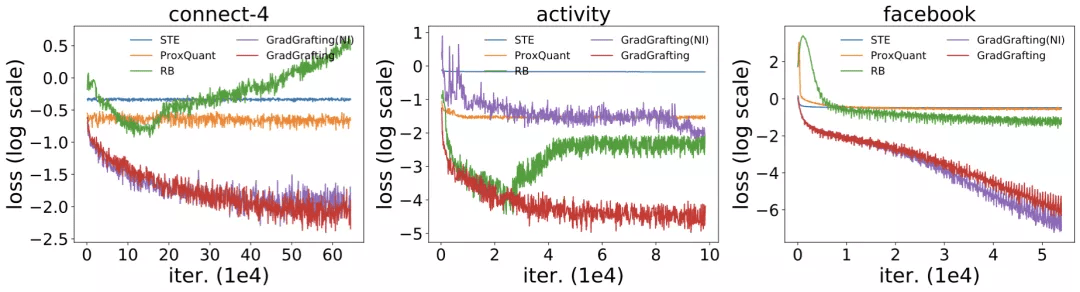
通过训练结构相同的 RRL , 作者将梯度嫁接法与 STE(Courbariaux et al., 2015, 2016) , ProxQuant(Bai et al., 2018)以及 RB(Wang et al., 2020)这三类离散模型训练方法进行了对比 , 训练损失函数结果如图 5 所示 。 由于 RRL 本身特殊的结构(即在离散点处的梯度具有极少的信息) , 只有使用梯度嫁接法训练的 RRL 才能够很好的收敛 。
改进的逻辑激活函数
改进前后的逻辑激活函数的结果同样在图 5 中展示 。 可以看出 , 当处理大规模数据时 , 逻辑激活函数会发生梯度消失的问题 , 从而导致不收敛 。 而改进后的逻辑激活函数则克服了该问题 。
文章图片
图 5:梯度嫁接和另外三种离散模型训练方法的训练损失 , 以及使用改进前后的逻辑激活函数的训练损失 。
实例展示
权重分布
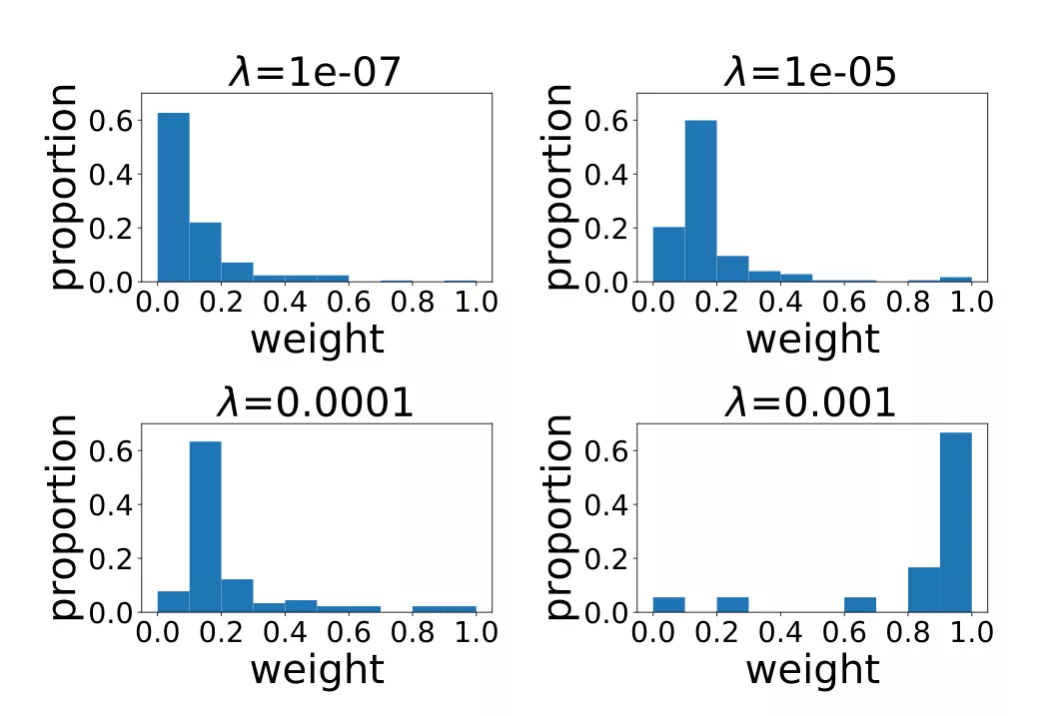
图 6 展示的是不同正则项系数所对应的 RRL 线性层权重(规则重要度)的分布情况 。 当正则项系数比较小时 , RRL 产生的规则比较复杂 , 数量较多 。 但从分布可以看出 , 大多数是权重绝对值较小的规则 。 因此 , 可以先去理解权重值较大的重要规则 , 当对模型整体和数据有了更好的认识后 , 再去理解权重较小的规则 。 而当正则项系数较大时 , RRL 整体复杂度较低 , 则可以直接理解模型整体 。
文章图片
图 6:不同正则项系数所对应的线性层权重分布 。
具体规则
图 7 为 bank-marketing 数据集所学到的部分规则 , 这些规则被用于预测用户是否会在电话销售中接受银行的贷款 。 可以从这些规则中直观看出哪些用户状态以及公司行为会对销售结果产生影响 , 例如中年已婚的低存款用户更可能接受贷款 。 银行可以根据这些可解释的规则来调整自己的营销策略 , 以增加销量 。
虽然 RRL 并非专门设计用于图像分类任务 , 但得益于其较好的可扩展性 , RRL 仍可以通过可视化的方式为图像分类任务提供直观的解释 。 图 8 是对 fashion-mnist 图像数据集上 RRL 所学到的规则的可视化 。 从中可以直观地总结出模型的决策模式 , 例如通过袖子长短区分 T 恤和套头衫 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。