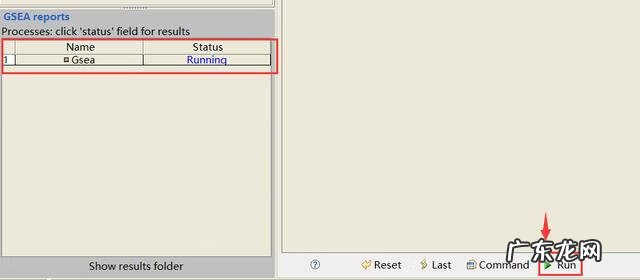
以上参数都设置好后点击参数设置栏下方的一个绿色按钮Run,若软件左下方GSEA reports处的状态显示Running的话则表示运行成功,此过程大概需要十分钟左右,视数据大小而定 。
文章插图
- Command:显示运行这个分析的命令行,以后就可以批量运行类似分析了 。
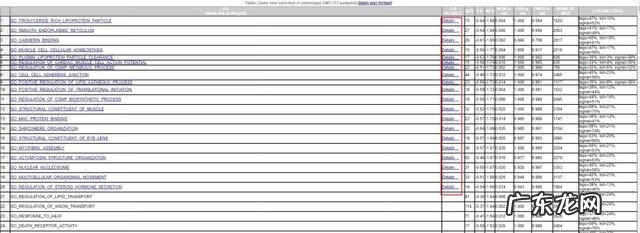
结果报告分为多个子项目,其中最重要的是前面两部分,基因富集结果就在这里 。从第三部分开始其实是软件在分析数据的过程产生的中间文件, 也很重要,读懂后可以加深对GSEA分析的认识,理解我们是如何从最初的基因表达矩阵得到最终的结果(即报告的前两个项目) 。建议先从Dataset details看起,然后再返回看第一部分的结果报告 。
1. Enrichment in phenotype
以正常人组NGT的17个样本数据为例解析最终结果 。

文章插图
报告首页文字总结信息表示:
- 经过条件筛选后还剩下3953个GO条目,其中1697个GO条目在NGT组中富集;
- 有36个GO基因条目在FDR<25%的条件下显著富集,这部分基因最有可能用于推进后续实验;
- 在统计检验p<0.01, p<0.05的条件下分别有19和114个GO条目显著富集;
- 结果有多种显示方式:图片快照(snapshot)、网页(html)和表格(Excel)形式;
- 点击Guide to可以查看官方帮助解读结果的文档 。
文章插图
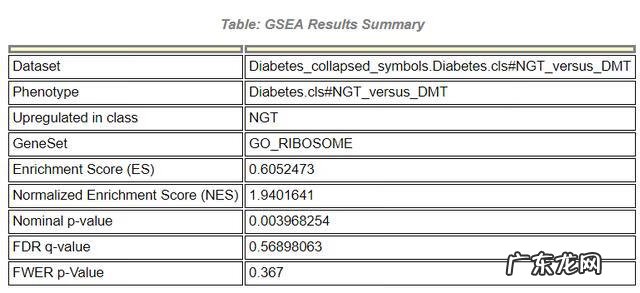
- GS:基因集的名字,GO条目的名字
- SIZE:GO条目中包含表达数据集文中的基因数目(经过条件筛选后的值);
- ES:富集评分;
- NES:校正后的归一化的ES值 。
- 由于不同用户输入的基因数据库文件中的基因集数目可能不同,富集评分的标准化考虑了基因集个数和大小 。
- 其绝对值大于1为一条富集标准 。
- 计算公式如下:
- NOM p-val:即p-value,是对富集得分ES的统计学分析,用来表征富集结果的可信度;
- FDR q-val:即q-value,是多重假设检验校正之后的p-value,即对NES可能存在的假阳性结果的概率估计,因此FDR越小说明富集越显著;
- RANK AT MAX:当ES值最大时,对应基因所在排序好的基因列表中所处的位置;(注:GSEA采用p-value<5%,q-value<25%进行数据过滤)
- LEADING EDGE:该处有3个统计值,tags=59%表示核心基因占该基因集中基因总数的百分比;list=21%表示核心基因占所有基因的百分比;signal=74%,将前两项统计数据结合在一起计算出的富集信号强度,计算公式如下:
- 其中n是列表中的基因数目,nh是基因集中的基因数目
文章插图
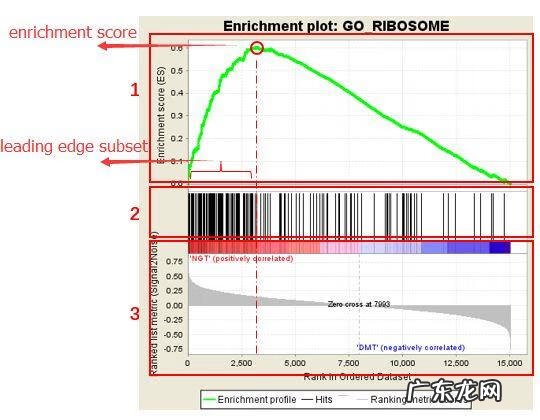
首先是一个选定GOset下的汇总信息表,每一部分意思在上面已做解释,其中Upregulated in class表示该基因集在哪个组别中高表达,这个主要看富集分析后的leading edge分布位置 。
- 中国研究生准考证打印 研究生考试准考证打印要求
- 英语四级考试考什么 四级英语总分多少
- 天津会计初级考试 天津会计考试
- 四级考试时间 四级考试报名条件
- 英语口语考试常用对话 英语口语考试对话内容
- 公共英语等级有几级 全国公共英语等级考试
- 会计初级证书报名条件 会计初级职称考试报考条件
- 造价工程师入门手册书籍 造价师考试用书
- 幼儿教师招聘考试试题及答案?
- 广东省公务员考试成绩怎么查询?
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。