作者 | Aimme
出品 | 焉知
一直想通过计算机视觉的角度好好地把其在自动驾驶视觉检测、追踪及融合上的原理进行详细阐述 , 对于下一代自动驾驶系统来说 , 会采用集中式方案进行摄像头的原始感知信息输入和原始雷达目标的输入 。 对于纯摄像头的感知方案通常采用针孔相机模型进行相机标定 , 在本文中 , 将研究相机配准和雷达传感器融合的整体过程 。 了解其对于掌握后续关于测量提取和传感器校准的讨论是必要的 。
单/双目相机标定基本原理
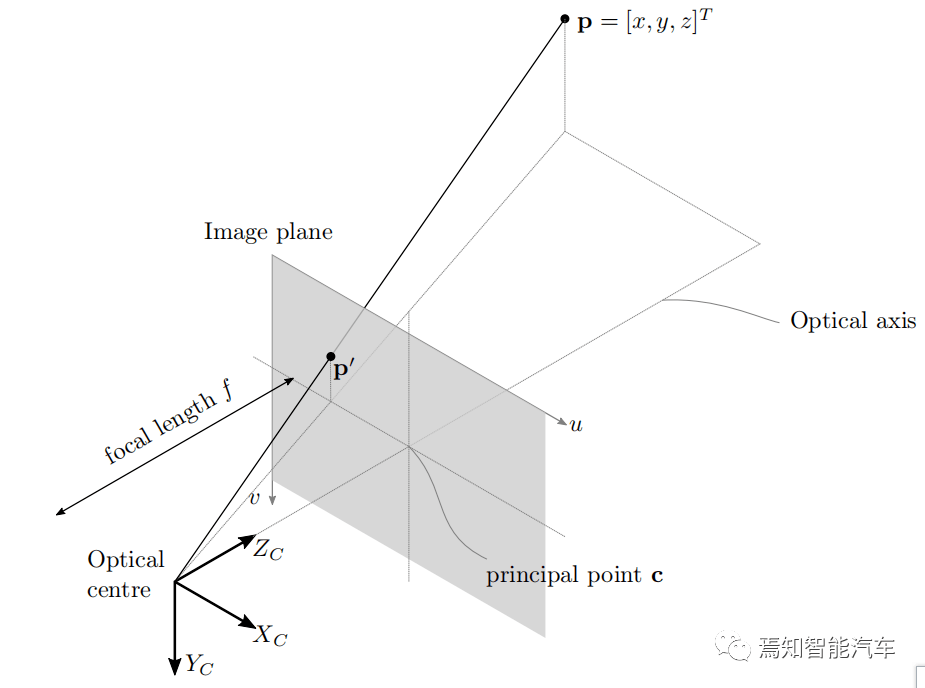
将相机信息与物理世界相关联 , 需要描述 3D 世界坐标和图像坐标之间数学关系的模型 , 计算机视觉中最简单的此类模型是针孔相机模型(如下图) 。
文章图片
图1 相机模型模型的投影
针孔模型中的图像形成是通过假设一个无限小的孔径来解释的 , 因此用了针孔这个术语 。 考虑上图中所有光线会聚在光学中心上 , 该中心与相机参考系的原点重合 , 光心到像面上主点c的距离等于焦距f , 来自点 p = [x,y,z] T的光线穿过光学中心 , 从而投影到位于图像平面上的点 p’= [x’,y’,z’] T 。 相似三角形的原理规定 , 点 [x,y,z] T 被映射到图像平面上的点 p’= [fx/z, fy/z, f] T。 忽略深度 , 该投影由 R3(三维)到 R2(二维)映射给出 , 即
(1)
引入齐次坐标 , 如上图像点信息可以改写为矩阵形式 , 其中K表示相机校准矩阵 。
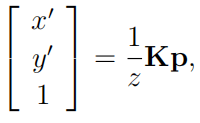
文章图片
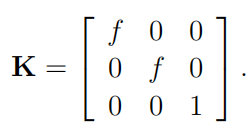
文章图片
(2)
方程 (2) 提供了将 3D 空间中的点转换为图像坐标的框架 。 通常 , 图像平面上的点 p’ 将根据像素坐标来寻找 。 可以适当缩放相机校准矩阵中的焦距条目 , 以将 R3 (三维)度量转换为 R2 (二维)像素 。 在实践中 , 相机校准矩阵默认为以像素为单位的焦距 , 并且它包括考虑非理想情况的参数 , 例如偏移主点或各个维度中每单位长度的像素数量不相等 。
相机标定方法旨在估计构成相机标定矩阵的参数 , 这些量被称为内在参数 , 校准一般采用张正友的九宫格标定技术 , 校准过程主要是通过采集不同的九宫格点构造如上方程的多个子式并进行6参数求解 。 本文讨论将不会深入研究关于相机校准的细节 , 而是重点讨论关于双目摄像头的感知过程 。
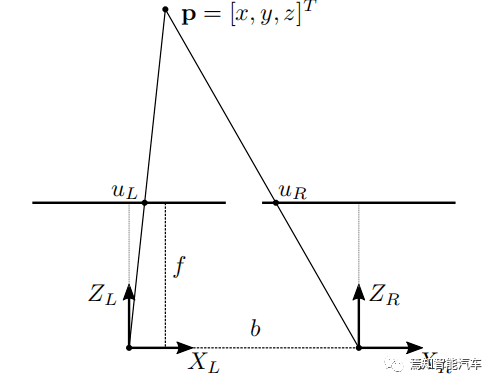
当多个摄像机查看同一场景时 , 可以从图像中提取深度信息 。 要使用单个摄像机实现相同的目标 , 需要了解正在记录的场景 。 考虑下图所示的理想化水平立体声配置 , 在这种情况下 , 各个相机的光学中心和图像平面共面 。
文章图片
图2 简单的相机视差模型
光学中心也相距一定距离 b , 这被称为立体基线 , 则视差计算方法如下:
(4)
【基于双目视觉的目标检测与追踪方案详解】计算水平和垂直坐标 x 和 y 依赖于与以前相同的原则 。 然而 , 深度信息具有唯一确定性 , 其过程就是求解环境检测点 p 的 z 坐标 。 其中 uL和 uR是点 p 投影到相应图像平面上的左右水平坐标 。 假设坐标系的原点与左相机中心重合 , 则
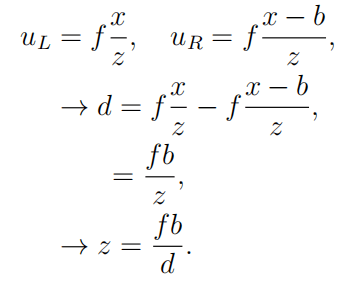
文章图片
(5)
等式 (5) 给出了理想水平立体配置中校准相机的视差和范围之间的关系 , 深度计算所需的关键量是视差 , 确定视差依赖于找到相应的像素在相应的图像中的位置点 , 对应的方法一般是依靠纹理信息进行帧间匹配 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。