使用深度可分卷积有什么坏处吗?当然是有的 。 深度可分卷积会降低卷积中参数的数量 。 因此 , 对于较小的模型而言 , 如果用深度可分卷积替代 2D 卷积 , 模型的能力可能会显著下降 。 因此 , 得到的模型可能是次优的 。 但是 , 如果使用得当 , 深度可分卷积能在不降低你的模型性能的前提下帮助你实现效率提升 。
分组卷积
AlexNet 论文(https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf)在 2012 年引入了分组卷积 。 实现分组卷积的主要原因是让网络训练可在 2 个内存有限(每个 GPU 有 1.5 GB 内存)的 GPU 上进行 。 下面的 AlexNet 表明在大多数层中都有两个分开的卷积路径 。 这是在两个 GPU 上执行模型并行化(当然如果可以使用更多 GPU , 还能执行多 GPU 并行化) 。
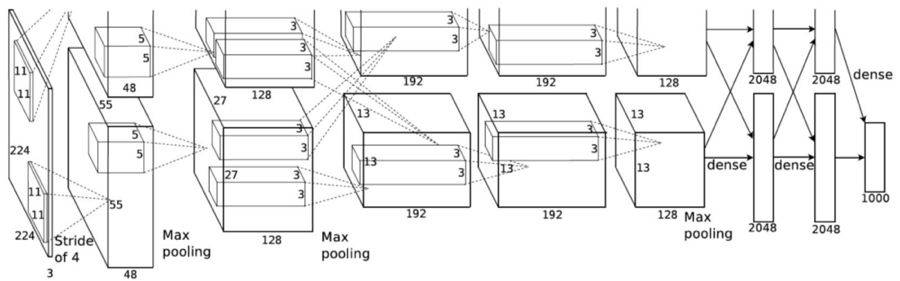
文章图片
图片来自 AlexNet 论文
这里我们介绍一下分组卷积的工作方式 。 首先 , 典型的 2D 卷积的步骤如下图所示 。 在这个例子中 , 通过应用 128 个大小为 3×3×3 的过滤器将输入层(7×7×3)变换到输出层(5×5×128) 。 推广而言 , 即通过应用 Dout 个大小为 h x w x Din 的核将输入层(Hin x Win x Din)变换到输出层(Hout x Wout x Dout) 。
标准的 2D 卷积
在分组卷积中 , 过滤器会被分为不同的组 。 每一组都负责特定深度的典型 2D 卷积 。 下面的例子能让你更清楚地理解 。
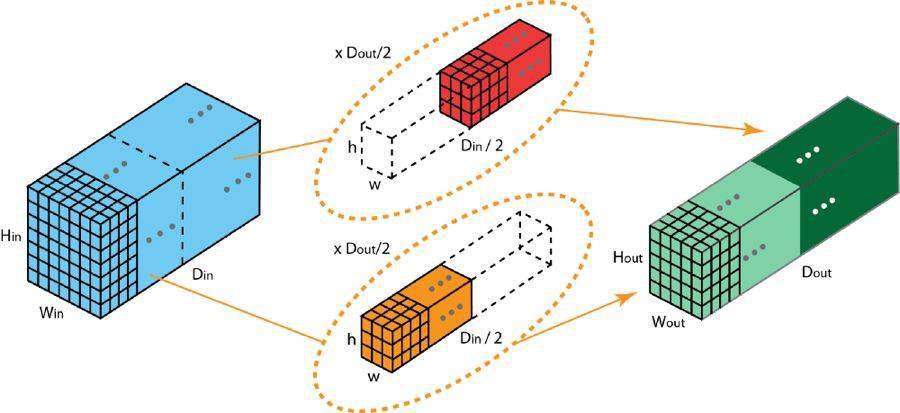
文章图片
具有两个过滤器分组的分组卷积
上图展示了具有两个过滤器分组的分组卷积 。 在每个过滤器分组中 , 每个过滤器的深度仅有名义上的 2D 卷积的一半 。 它们的深度是 Din/2 。 每个过滤器分组包含 Dout/2 个过滤器 。 第一个过滤器分组(红色)与输入层的前一半([:, :, 0:Din/2])卷积 , 而第二个过滤器分组(橙色)与输入层的后一半([:, :, Din/2:Din])卷积 。 因此 , 每个过滤器分组都会创建 Dout/2 个通道 。 整体而言 , 两个分组会创建 2×Dout/2 = Dout 个通道 。 然后我们将这些通道堆叠在一起 , 得到有 Dout 个通道的输出层 。
1、分组卷积与深度卷积
你可能会注意到分组卷积与深度可分卷积中使用的深度卷积之间存在一些联系和差异 。 如果过滤器分组的数量与输入层通道的数量相同 , 则每个过滤器的深度都为 Din/Din=1 。 这样的过滤器深度就与深度卷积中的一样了 。
另一方面 , 现在每个过滤器分组都包含 Dout/Din 个过滤器 。 整体而言 , 输出层的深度为 Dout 。 这不同于深度卷积的情况——深度卷积并不会改变层的深度 。 在深度可分卷积中 , 层的深度之后通过 1×1 卷积进行扩展 。
分组卷积有几个优点 。
第一个优点是高效训练 。 因为卷积被分成了多个路径 , 每个路径都可由不同的 GPU 分开处理 , 所以模型可以并行方式在多个 GPU 上进行训练 。 相比于在单个 GPU 上完成所有任务 , 这样的在多个 GPU 上的模型并行化能让网络在每个步骤处理更多图像 。 人们一般认为模型并行化比数据并行化更好 。 后者是将数据集分成多个批次 , 然后分开训练每一批 。 但是 , 当批量大小变得过小时 , 我们本质上是执行随机梯度下降 , 而非批梯度下降 。 这会造成更慢 , 有时候更差的收敛结果 。
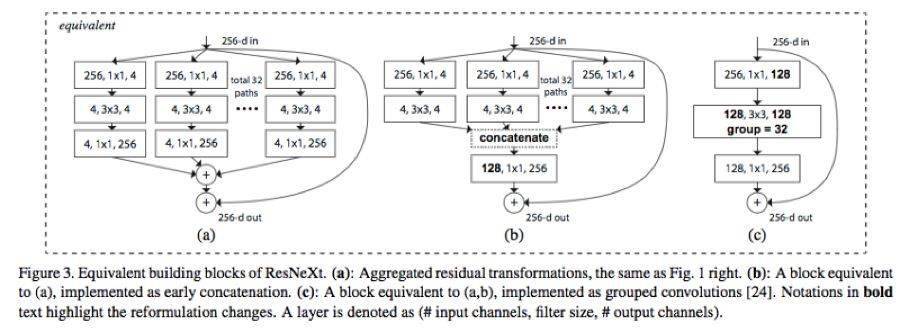
在训练非常深的神经网络时 , 分组卷积会非常重要 , 正如在 ResNeXt 中那样 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。