图1:执行 CMatch 前后效果对比
CMatch 方法由两个步骤组成:帧级标签分配和字符级别的分布匹配 。
其中,帧级别标签分配可以为语音信号获得更加准确的“特征-标签”对应关系,为下一步实现基于标签(即字符)的分布适配提供依据,即需要获得帧级别的标签以取得更细粒度的特征分布 。要想进行帧级标签分配,首先需要获得较为准确的标签对齐 。如图2所示的三种方法:CTC 强制对齐、动态帧平均、以及伪 CTC 标签 。可以看出,CTC 强制对齐是通过预训练的 CTC 模块,在计算每条文本对应的最可能的 CTC 路径(插入重复和 Blank 符号)后分配到每个语音帧上,这个方法相对准确但是计算代价较高;动态帧平均则是将语音帧平均分配到每个字符上,这个方法需要基于源域和目标域语速均匀的假设;而伪 CTC 标签的方法,通过利用已经在源域上学习较好的 CTC 模块外加基于置信度的过滤(如图2中的 t、e、p 等),兼顾了高效和准确性 。

文章插图
图2:三种帧级标签分配策略
需要说明的是,在源域上使用真实文本进行标签分配时,由于目标域没有文本,所以需要借助源域模型先对目标域的语音数据进行伪标注,然后再使用模型标注的文本进行标签分配 。
得到帧级别的标签后,就需要进行字符级别的分布匹配 。研究员们选择采用了 Maximum Mean Discrepancy(MMD)度量进行特征匹配 。MMD 用于评估两个分布之间的差异,是迁移学习中常见的一种分布度量方法 。它的公式为:
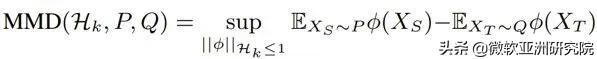
文章插图
实际操作中,给定源域和目标域样本 X_S, X_T,计算 MMD 的有偏差的经验估计:
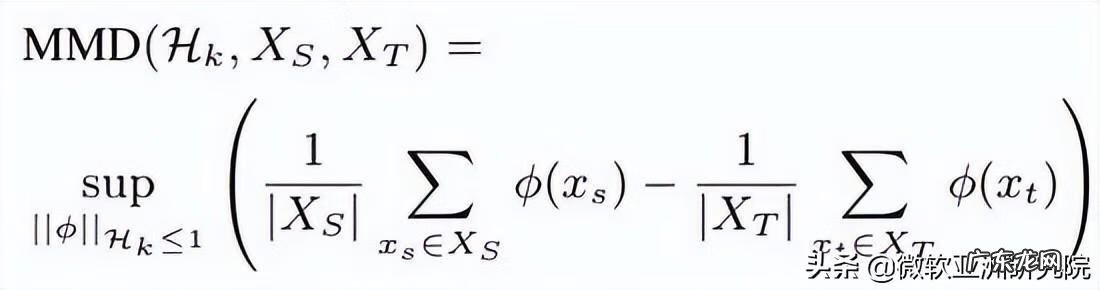
文章插图
通过计算所有字符之间的平均 MMD,可以得到字符级别的分布匹配损失函数:

文章插图
最终,微软亚洲研究院采用 CTC-Attention 混合模型作为基础 ASR 模型,以及同时混合学习 CTC 模块(用于帧级标签分配)和基于 Transformer Decoder 的 Seq2Seq Loss,于是语音识别的损失函数可以表示为:
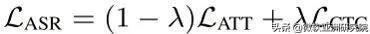
文章插图
将分布匹配损失函数和语音识别损失函数相结合,就得到了最终的损失函数:
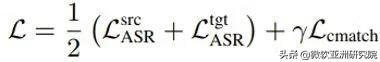
文章插图
最终算法流程如表1:

文章插图
表1:CMatch 学习算法
表2是跨设备语音识别时的结果,值得注意到的是,Source-only 的模型在其他设备录制语音上的识别效果相比领域内模型都会有一定程度的下降 。而基于全局 MMD 和领域对抗训练的方法均有所提升,CMatch 则在各个情况下均取得了最佳的效果 。
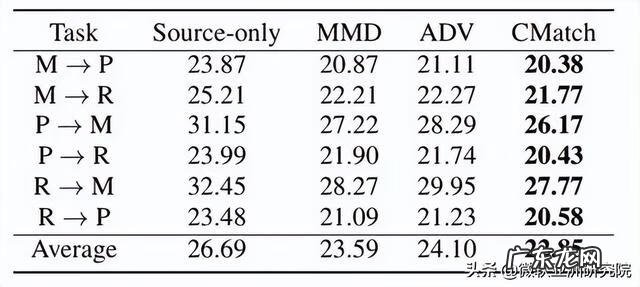
文章插图
表2:跨设备语音识别结果
表3的结果表明,CMatch 在跨环境(抗噪声)语音识别情况下也取得了很好的效果 。
- 若不差钱,建议给家里添置这5件小家电,提升生活幸福感!
- 考贵大的mba难度大吗 MBA考试难么
- 南海观世音菩萨在小说中出场的情节有哪些-观音的言行,对唐僧师徒西天取经有哪几方面的影响-请结合相关?
- 小学生清明节手抄报大全?
- 小朋友偏食怎么办?
- 小时候夏夜仰望星空满天都是星星,现在怎么都看不到那种景象了?
- 夜晚很无聊怎么办?
- 如何做好一名优秀的小班幼儿教师研修成果论文?
- 血小板低怎么调理 血小板低是怎么回事
- 今年高考数学那么难,区分度会好吗?
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。